 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlashMoE: Reducing SSD I/O Bottlenecks via ML-Based Cache Replacement for Mixture-of-Experts Inference on Edge Devices
Jan 22, 2026Recently, Mixture-of-Experts (MoE) models have gained attention for efficiently scaling large language models. Although these models are extremely large, their sparse activation enables inference to be performed by accessing only a fraction of the model at a time. This property opens the possibility of on-device inference of MoE, which was previously considered infeasible for such large models. Consequently, various systems have been proposed to leverage this sparsity and enable efficient MoE inference for edge devices. However, previous MoE inference systems like Fiddler[8] or DAOP[13] rely on DRAM-based offloading and are not suitable for memory constrained on-device environments. As recent MoE models grow to hundreds of gigabytes, RAM-offloading solutions become impractical. To address this, we propose FlashMoE, a system that offloads inactive experts to SSD, enabling efficient MoE inference under limited RAM. FlashMoE incorporates a lightweight ML-based caching strategy that adaptively combines recency and frequency signals to maximize expert reuse, significantly reducing storage I/O. In addition, we built a user-grade desktop platform to demonstrate the practicality of FlashMoE. On this real hardware setup, FlashMoE improves cache hit rate by up to 51% over well-known offloading policies such as LRU and LFU, and achieves up to 2.6x speedup compared to existing MoE inference systems.
GST: Group-Sparse Training for Accelerating Deep Reinforcement Learning
Jan 24, 2021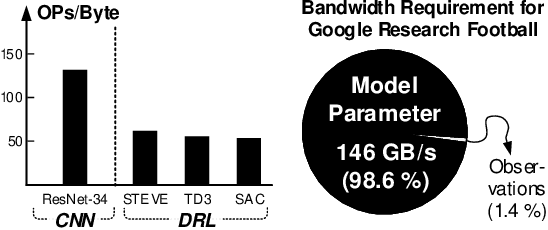
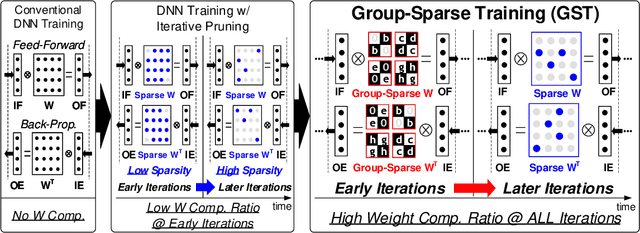
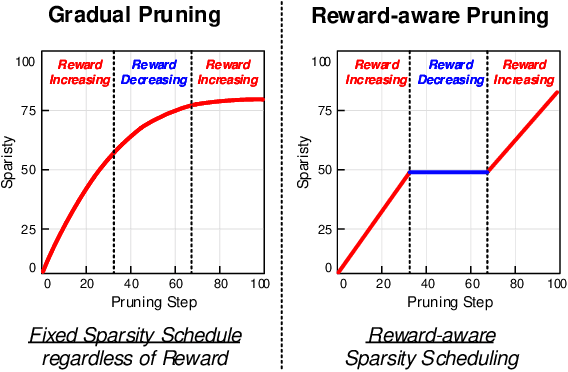
Deep reinforcement learning (DRL) has shown remarkable success in sequential decision-making problems but suffers from a long training time to obtain such good performance. Many parallel and distributed DRL training approaches have been proposed to solve this problem, but it is difficult to utilize them on resource-limited devices. In order to accelerate DRL in real-world edge devices, memory bandwidth bottlenecks due to large weight transactions have to be resolved. However, previous iterative pruning not only shows a low compression ratio at the beginning of training but also makes DRL training unstable. To overcome these shortcomings, we propose a novel weight compression method for DRL training acceleration, named group-sparse training (GST). GST selectively utilizes block-circulant compression to maintain a high weight compression ratio during all iterations of DRL training and dynamically adapt target sparsity through reward-aware pruning for stable training. Thanks to the features, GST achieves a 25 \%p $\sim$ 41.5 \%p higher average compression ratio than the iterative pruning method without reward drop in Mujoco Halfcheetah-v2 and Mujoco humanoid-v2 environment with TD3 training.