 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Video Analytics Systems to Large Camera Deployments
Nov 03, 2018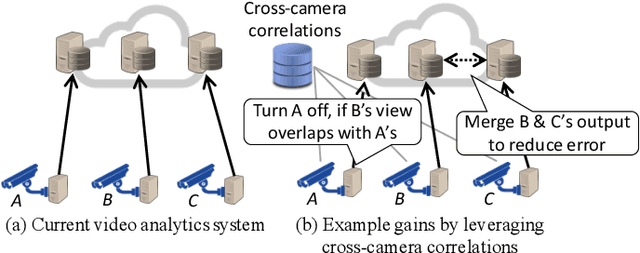
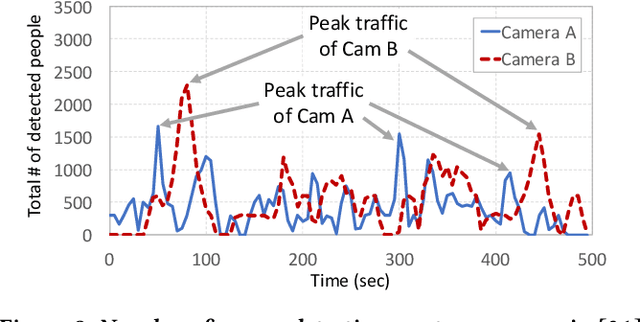
Driven by advances in computer vision and the falling costs of camera hardware, organizations are deploying video cameras en masse for the spatial monitoring of their physical premises. Scaling video analytics to massive camera deployments, however, presents a new and mounting challenge, as compute cost grows proportionally to the number of camera feeds. This paper is driven by a simple question: can we scale video analytics in such a way that cost grows sublinearly, or even remains constant, as we deploy more cameras, while inference accuracy remains stable, or even improves. We believe the answer is yes. Our key observation is that video feeds from wide-area camera deployments demonstrate significant content correlations (e.g. to other geographically proximate feeds), both in space and over time. These spatio-temporal correlations can be harnessed to dramatically reduce the size of the inference search space, decreasing both workload and false positive rates in multi-camera video analytics. By discussing use-cases and technical challenges, we propose a roadmap for scaling video analytics to large camera networks, and outline a plan for its realization.
ReXCam: Resource-Efficient, Cross-Camera Video Analytics at Enterprise Scale
Nov 03, 2018


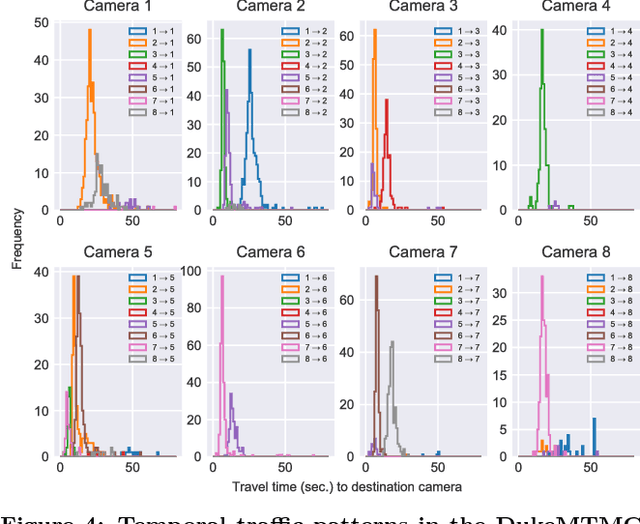
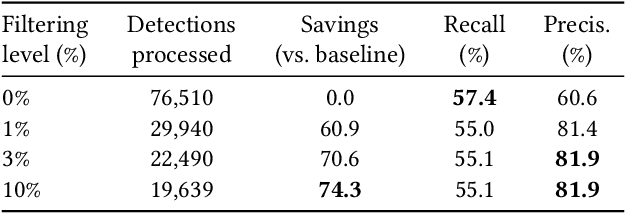
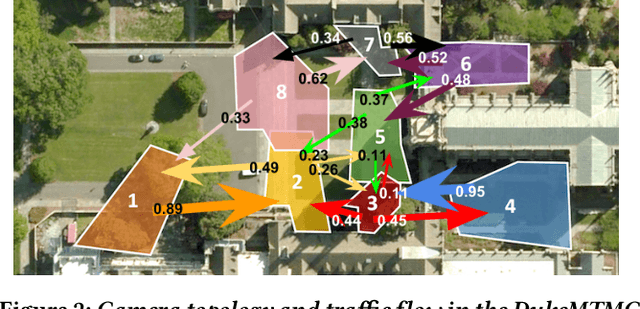
The deployment of large camera networks for video analytics is an established and accelerating trend. Many real video inference applications entail a common problem template: searching for an object or activity of interest (e.g. a person, a speeding vehicle) through a large camera network in live video. This capability, called cross-camera analytics, is compute and data intensive -- requiring automated search across cameras and across frames, at the throughput of the live video stream. To address the cost challenge of processing every raw video frame from a large deployment, we present ReXCam, a new system for efficient cross-camera video analytics. ReXCam exploits spatial and temporal locality in the dynamics of real camera networks to guide its inference-time search for a query identity. In an offline profiling phase, ReXCam builds a cross-camera correlation model that encodes the locality observed in historical traffic patterns. At inference time, ReXCam applies this model to filter frames that are not spatially and temporally correlated with the query identity's current position. In the cases of occasional missed detections, ReXCam performs a fast-replay search on recently filtered video frames, enabling gracefully recovery. Together, these techniques allow ReXCam to reduce compute workload by 4.6x and improve inference precision by 27% on a well-known video dataset with footage from eight cameras, while maintaining within 1-2% of baseline recall.
Fast Semantic Segmentation on Video Using Block Motion-Based Feature Interpolation
Oct 09, 2018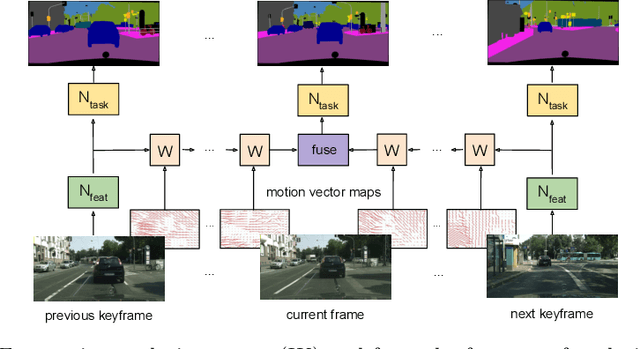

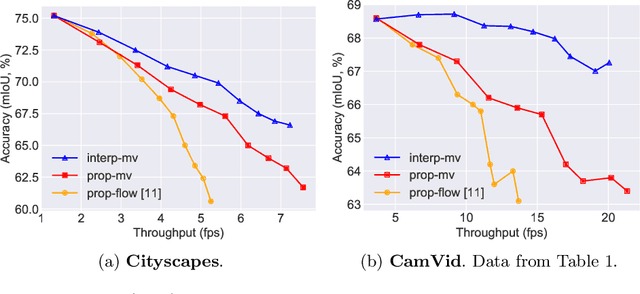
Convolutional networks optimized for accuracy on challenging, dense prediction tasks are prohibitively slow to run on each frame in a video. The spatial similarity of nearby video frames, however, suggests opportunity to reuse computation. Existing work has explored basic feature reuse and feature warping based on optical flow, but has encountered limits to the speedup attainable with these techniques. In this paper, we present a new, two part approach to accelerating inference on video. First, we propose a fast feature propagation technique that utilizes the block motion vectors present in compressed video (e.g. H.264 codecs) to cheaply propagate features from frame to frame. Second, we develop a novel feature estimation scheme, termed feature interpolation, that fuses features propagated from enclosing keyframes to render accurate feature estimates, even at sparse keyframe frequencies. We evaluate our system on the Cityscapes and CamVid datasets, comparing to both a frame-by-frame baseline and related work. We find that we are able to substantially accelerate semantic segmentation on video, achieving over twice the average inference speed as prior work at any target accuracy.
Inter-BMV: Interpolation with Block Motion Vectors for Fast Semantic Segmentation on Video
Oct 08, 2018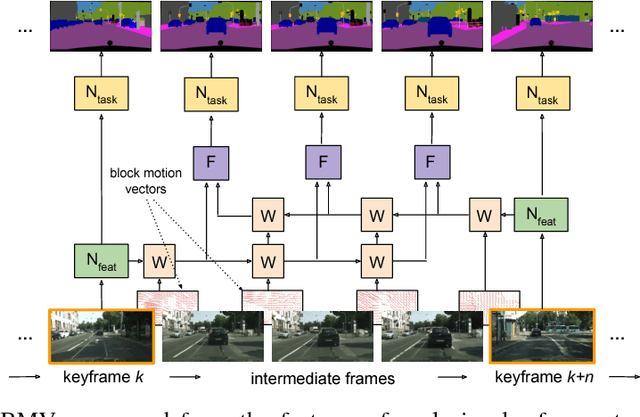
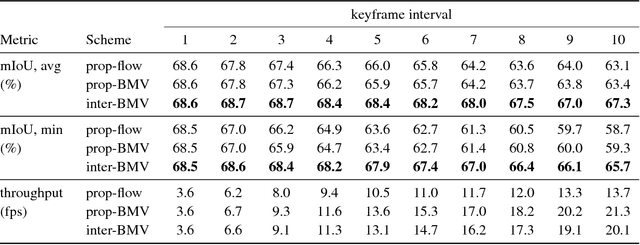

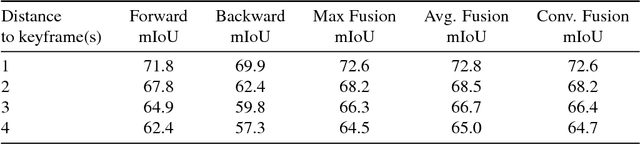
Models optimized for accuracy on single images are often prohibitively slow to run on each frame in a video. Recent work exploits the use of optical flow to warp image features forward from select keyframes, as a means to conserve computation on video. This approach, however, achieves only limited speedup, even when optimized, due to the accuracy degradation introduced by repeated forward warping, and the inference cost of optical flow estimation. To address these problems, we propose a new scheme that propagates features using the block motion vectors (BMV) present in compressed video (e.g. H.264 codecs), instead of optical flow, and bi-directionally warps and fuses features from enclosing keyframes to capture scene context on each video frame. Our technique, interpolation-BMV, enables us to accurately estimate the features of intermediate frames, while keeping inference costs low. We evaluate our system on the CamVid and Cityscapes datasets, comparing to both a strong single-frame baseline and related work. We find that we are able to substantially accelerate segmentation on video, achieving near real-time frame rates (20+ frames per second) on large images (e.g. 960 x 720 pixels), while maintaining competitive accuracy. This represents an improvement of almost 6x over the single-frame baseline and 2.5x over the fastest prior work.
Accel: A Corrective Fusion Network for Efficient Semantic Segmentation on Video
Sep 07, 2018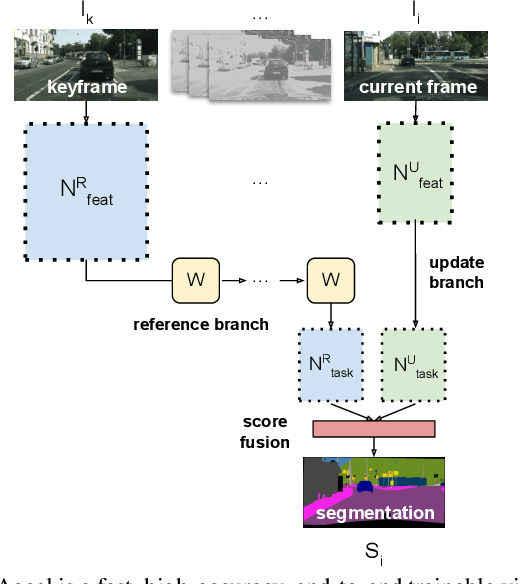
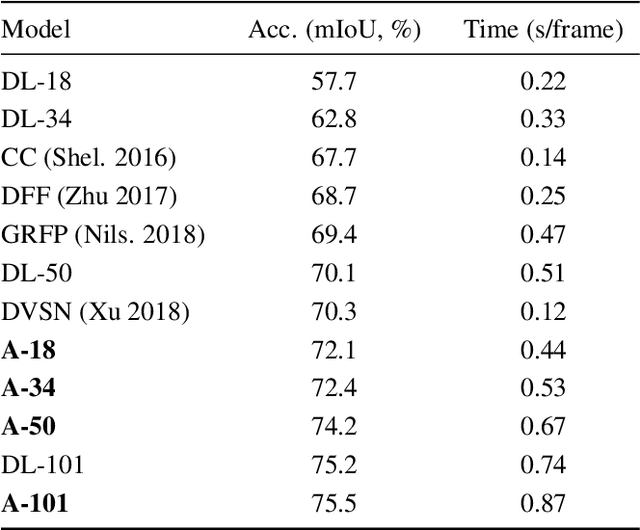
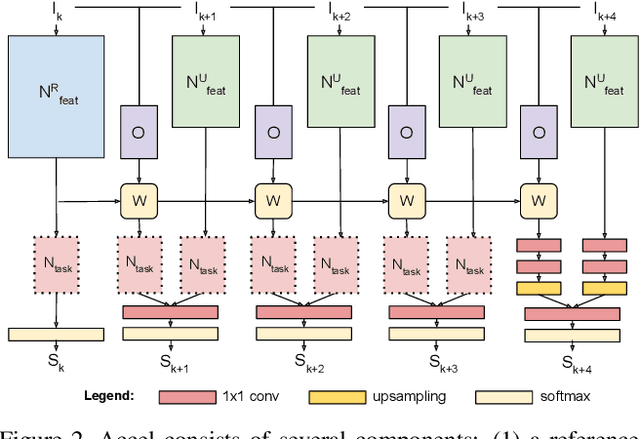
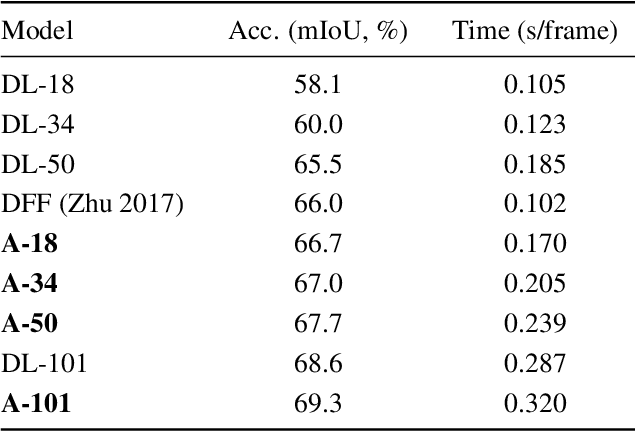
We present Accel, a novel semantic video segmentation system that achieves high accuracy at low inference cost by combining the predictions of two network branches: (1) a reference branch that extracts high-detail features on a reference keyframe, and warps these features forward using frame-to-frame optical flow estimates, and (2) an update branch that computes features of adjustable quality on the current frame, performing a temporal update at each video frame. The modularity of the update branch, where feature subnetworks of varying layer depth can be inserted (e.g. ResNet-18 to ResNet-101), enables operation over a new, state-of-the-art accuracy-throughput trade-off spectrum. Over this curve, Accel models achieve both higher accuracy and faster inference times than the closest comparable single-frame segmentation networks. In general, Accel significantly outperforms previous work on efficient semantic video segmentation, correcting warping-related error that compounds on datasets with complex dynamics. Accel is end-to-end trainable and highly modular: the reference network, the optical flow network, and the update network can each be selected independently, depending on application requirements, and then jointly fine-tuned. The result is a robust, general system for fast, high-accuracy semantic segmentation on video.