 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Semantic Segmentation on Video Using Block Motion-Based Feature Interpolation
Paper and Code
Oct 09, 2018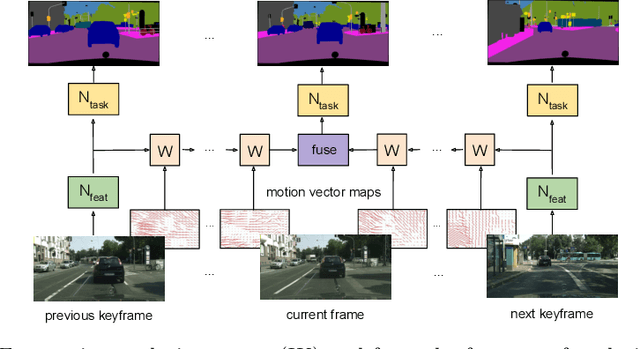

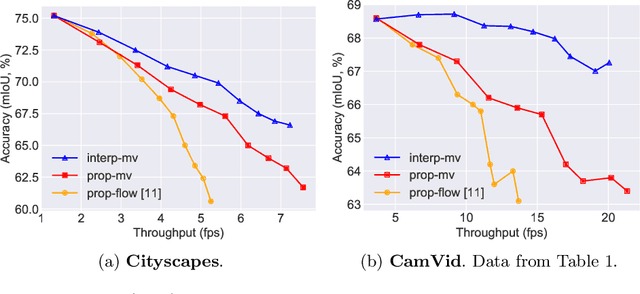
Convolutional networks optimized for accuracy on challenging, dense prediction tasks are prohibitively slow to run on each frame in a video. The spatial similarity of nearby video frames, however, suggests opportunity to reuse computation. Existing work has explored basic feature reuse and feature warping based on optical flow, but has encountered limits to the speedup attainable with these techniques. In this paper, we present a new, two part approach to accelerating inference on video. First, we propose a fast feature propagation technique that utilizes the block motion vectors present in compressed video (e.g. H.264 codecs) to cheaply propagate features from frame to frame. Second, we develop a novel feature estimation scheme, termed feature interpolation, that fuses features propagated from enclosing keyframes to render accurate feature estimates, even at sparse keyframe frequencies. We evaluate our system on the Cityscapes and CamVid datasets, comparing to both a frame-by-frame baseline and related work. We find that we are able to substantially accelerate semantic segmentation on video, achieving over twice the average inference speed as prior work at any target accuracy.