 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh Resolution Tree Height Mapping of the Amazon Forest using Planet NICFI Images and LiDAR-Informed U-Net Model
Jan 17, 2025



Tree canopy height is one of the most important indicators of forest biomass, productivity, and ecosystem structure, but it is challenging to measure accurately from the ground and from space. Here, we used a U-Net model adapted for regression to map the mean tree canopy height in the Amazon forest from Planet NICFI images at ~4.78 m spatial resolution for the period 2020-2024. The U-Net model was trained using canopy height models computed from aerial LiDAR data as a reference, along with their corresponding Planet NICFI images. Predictions of tree heights on the validation sample exhibited a mean error of 3.68 m and showed relatively low systematic bias across the entire range of tree heights present in the Amazon forest. Our model successfully estimated canopy heights up to 40-50 m without much saturation, outperforming existing canopy height products from global models in this region. We determined that the Amazon forest has an average canopy height of ~22 m. Events such as logging or deforestation could be detected from changes in tree height, and encouraging results were obtained to monitor the height of regenerating forests. These findings demonstrate the potential for large-scale mapping and monitoring of tree height for old and regenerating Amazon forests using Planet NICFI imagery.
Amazon's 2023 Drought: Sentinel-1 Reveals Extreme Rio Negro River Contraction
Jan 29, 2024The Amazon, the world's largest rainforest, faces a severe historic drought. The Rio Negro River, one of the major Amazon River tributaries, reaches its lowest level in a century in October 2023. Here, we used a U-net deep learning model to map water surfaces in the Rio Negro River basin every 12 days in 2022 and 2023 using 10 m spatial resolution Sentinel-1 satellite radar images. The accuracy of the water surface model was high with an F1-score of 0.93. The 12 days mosaic time series of water surface was generated from the Sentinel-1 prediction. The water surface mask demonstrated relatively consistent agreement with the Global Surface Water (GSW) product from Joint Research Centre (F1-score: 0.708) and with the Brazilian Mapbiomas Water initiative (F1-score: 0.686). The main errors of the map were omission errors in flooded woodland, in flooded shrub and because of clouds. Rio Negro water surfaces reached their lowest level around the 25th of November 2023 and were reduced to 68.1\% (9,559.9 km$^2$) of the maximum water surfaces observed in the period 2022-2023 (14,036.3 km$^2$). Synthetic Aperture Radar (SAR) data, in conjunction with deep learning techniques, can significantly improve near real-time mapping of water surface in tropical regions.
Sub-Meter Tree Height Mapping of California using Aerial Images and LiDAR-Informed U-Net Model
Jun 02, 2023



Tree canopy height is one of the most important indicators of forest biomass, productivity, and species diversity, but it is challenging to measure accurately from the ground and from space. Here, we used a U-Net model adapted for regression to map the canopy height of all trees in the state of California with very high-resolution aerial imagery (60 cm) from the USDA-NAIP program. The U-Net model was trained using canopy height models computed from aerial LiDAR data as a reference, along with corresponding RGB-NIR NAIP images collected in 2020. We evaluated the performance of the deep-learning model using 42 independent 1 km$^2$ sites across various forest types and landscape variations in California. Our predictions of tree heights exhibited a mean error of 2.9 m and showed relatively low systematic bias across the entire range of tree heights present in California. In 2020, trees taller than 5 m covered ~ 19.3% of California. Our model successfully estimated canopy heights up to 50 m without saturation, outperforming existing canopy height products from global models. The approach we used allowed for the reconstruction of the three-dimensional structure of individual trees as observed from nadir-looking optical airborne imagery, suggesting a relatively robust estimation and mapping capability, even in the presence of image distortion. These findings demonstrate the potential of large-scale mapping and monitoring of tree height, as well as potential biomass estimation, using NAIP imagery.
K-textures, a self supervised hard clustering deep learning algorithm for satellite images segmentation
May 18, 2022
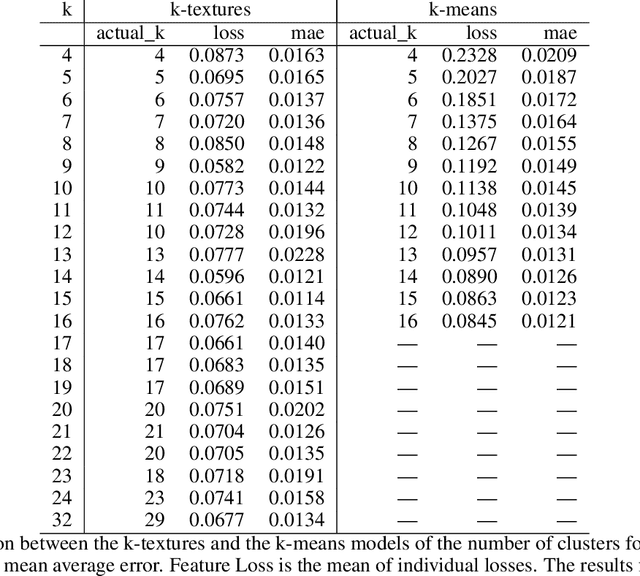
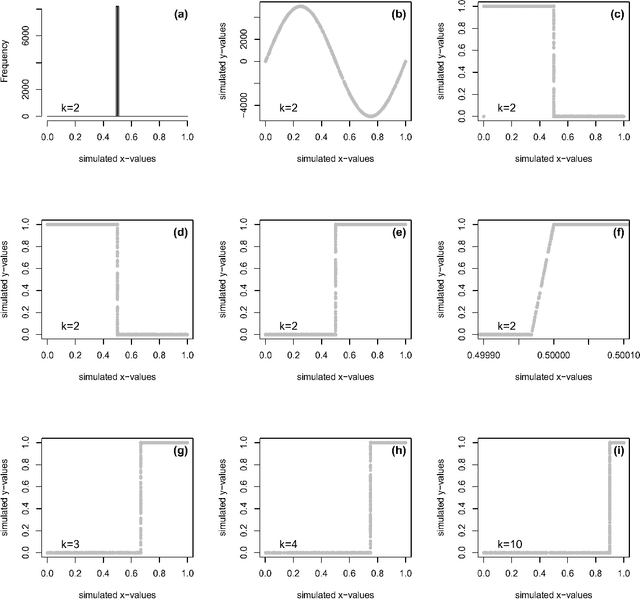
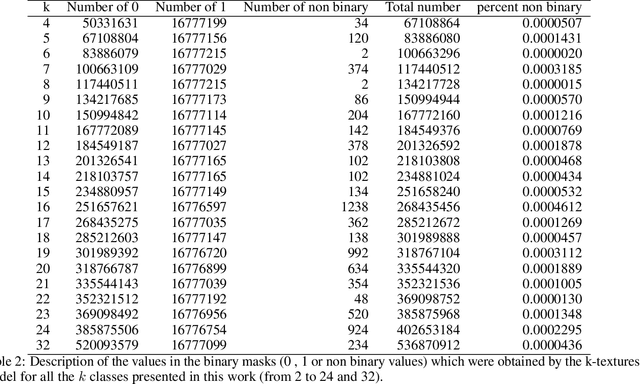
Deep learning self supervised algorithms that can segment an image in a fixed number of hard labels such as the k-means algorithm and only relying only on deep learning techniques are still lacking. Here, we introduce the k-textures algorithm which provides self supervised segmentation of a 4-band image (RGB-NIR) for a $k$ number of classes. An example of its application on high resolution Planet satellite imagery is given. Our algorithm shows that discrete search is feasible using convolutional neural networks (CNN) and gradient descent. The model detects $k$ hard clustering classes represented in the model as $k$ discrete binary masks and their associated $k$ independently generated textures, that combined are a simulation of the original image. The similarity loss is the mean squared error between the features of the original and the simulated image, both extracted from the penultimate convolutional block of Keras 'imagenet' pretrained VGG-16 model and a custom feature extractor made with Planet data. The main advances of the k-textures model are: first, the $k$ discrete binary masks are obtained inside the model using gradient descent. The model allows for the generation of discrete binary masks using a novel method using a hard sigmoid activation function. Second, it provides hard clustering classes -- each pixels has only one class. Finally, in comparison to k-means, where each pixel is considered independently, here, contextual information is also considered and each class is not associated only to a similar values in the color channels but to a texture. Our approach is designed to ease the production of training samples for satellite image segmentation. The model codes and weights are available at https://doi.org/10.5281/zenodo.6359859