 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnticipating human actions by correlating past with the future with Jaccard similarity measures
May 26, 2021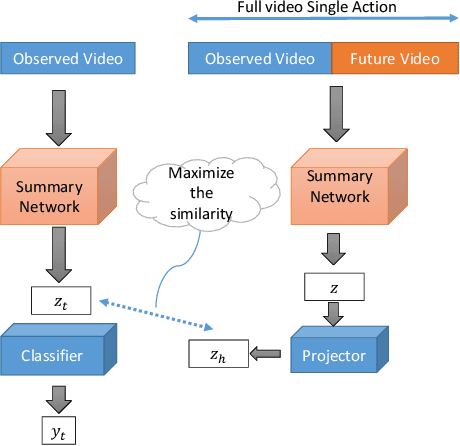
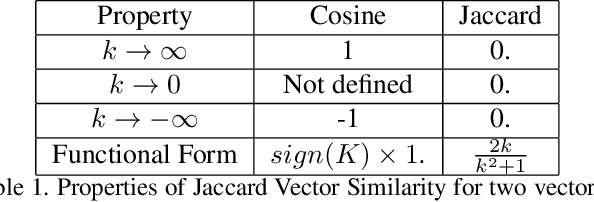
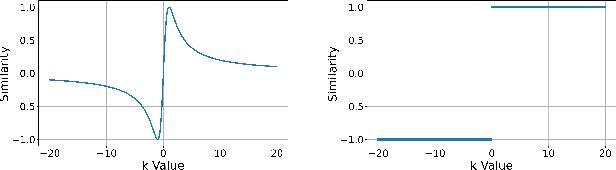

We propose a framework for early action recognition and anticipation by correlating past features with the future using three novel similarity measures called Jaccard vector similarity, Jaccard cross-correlation and Jaccard Frobenius inner product over covariances. Using these combinations of novel losses and using our framework, we obtain state-of-the-art results for early action recognition in UCF101 and JHMDB datasets by obtaining 91.7 % and 83.5 % accuracy respectively for an observation percentage of 20. Similarly, we obtain state-of-the-art results for Epic-Kitchen55 and Breakfast datasets for action anticipation by obtaining 20.35 and 41.8 top-1 accuracy respectively.
All Labels Are Not Created Equal: Enhancing Semi-supervision via Label Grouping and Co-training
Apr 12, 2021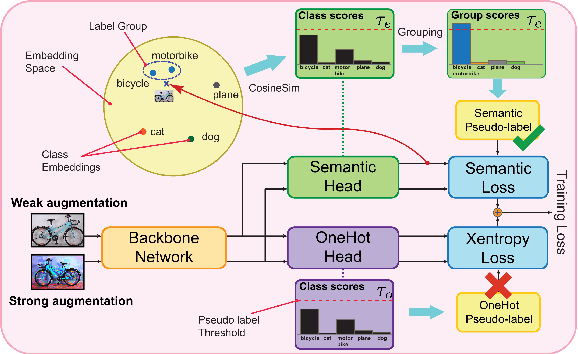
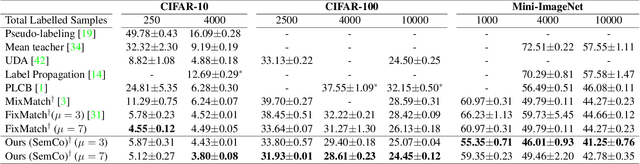
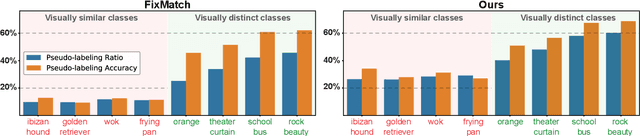
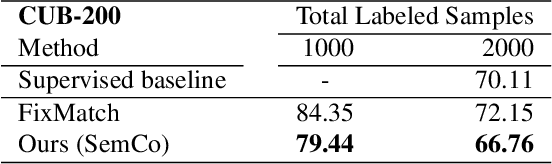
Pseudo-labeling is a key component in semi-supervised learning (SSL). It relies on iteratively using the model to generate artificial labels for the unlabeled data to train against. A common property among its various methods is that they only rely on the model's prediction to make labeling decisions without considering any prior knowledge about the visual similarity among the classes. In this paper, we demonstrate that this degrades the quality of pseudo-labeling as it poorly represents visually similar classes in the pool of pseudo-labeled data. We propose SemCo, a method which leverages label semantics and co-training to address this problem. We train two classifiers with two different views of the class labels: one classifier uses the one-hot view of the labels and disregards any potential similarity among the classes, while the other uses a distributed view of the labels and groups potentially similar classes together. We then co-train the two classifiers to learn based on their disagreements. We show that our method achieves state-of-the-art performance across various SSL tasks including 5.6% accuracy improvement on Mini-ImageNet dataset with 1000 labeled examples. We also show that our method requires smaller batch size and fewer training iterations to reach its best performance. We make our code available at https://github.com/islam-nassar/semco.
Learning an Invariant Hilbert Space for Domain Adaptation
Apr 17, 2017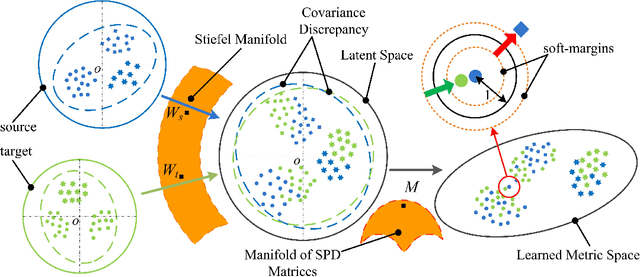
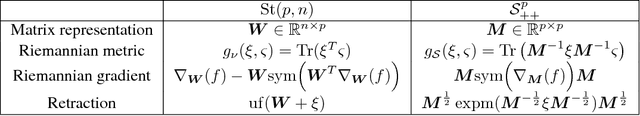
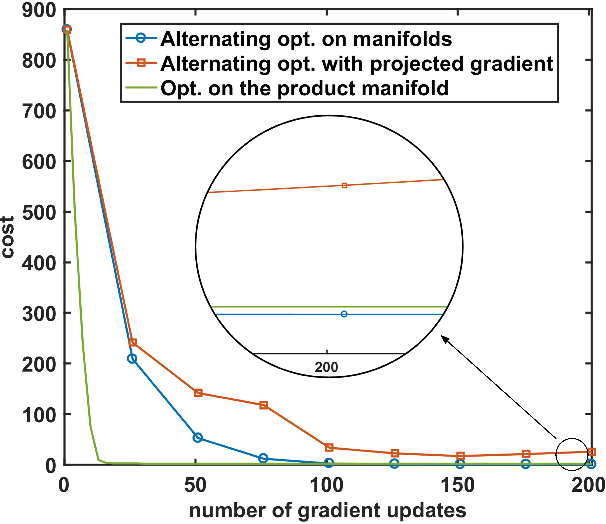
This paper introduces a learning scheme to construct a Hilbert space (i.e., a vector space along its inner product) to address both unsupervised and semi-supervised domain adaptation problems. This is achieved by learning projections from each domain to a latent space along the Mahalanobis metric of the latent space to simultaneously minimizing a notion of domain variance while maximizing a measure of discriminatory power. In particular, we make use of the Riemannian optimization techniques to match statistical properties (e.g., first and second order statistics) between samples projected into the latent space from different domains. Upon availability of class labels, we further deem samples sharing the same label to form more compact clusters while pulling away samples coming from different classes.We extensively evaluate and contrast our proposal against state-of-the-art methods for the task of visual domain adaptation using both handcrafted and deep-net features. Our experiments show that even with a simple nearest neighbor classifier, the proposed method can outperform several state-of-the-art methods benefitting from more involved classification schemes.
Going Deeper into Action Recognition: A Survey
Feb 01, 2017
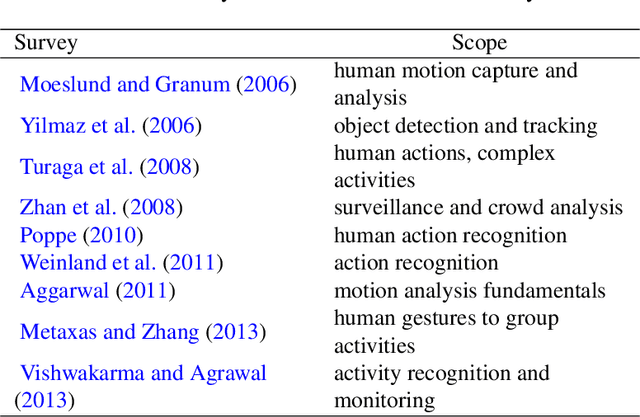
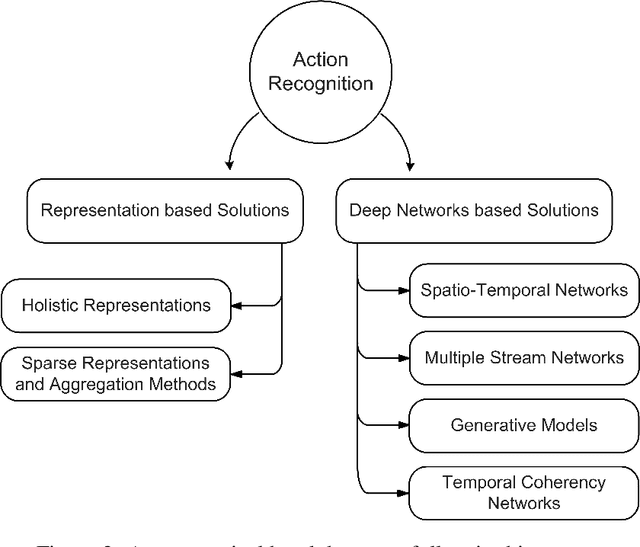
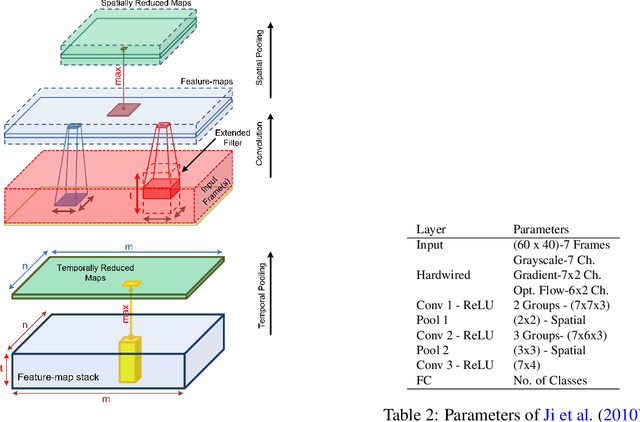
Understanding human actions in visual data is tied to advances in complementary research areas including object recognition, human dynamics, domain adaptation and semantic segmentation. Over the last decade, human action analysis evolved from earlier schemes that are often limited to controlled environments to nowadays advanced solutions that can learn from millions of videos and apply to almost all daily activities. Given the broad range of applications from video surveillance to human-computer interaction, scientific milestones in action recognition are achieved more rapidly, eventually leading to the demise of what used to be good in a short time. This motivated us to provide a comprehensive review of the notable steps taken towards recognizing human actions. To this end, we start our discussion with the pioneering methods that use handcrafted representations, and then, navigate into the realm of deep learning based approaches. We aim to remain objective throughout this survey, touching upon encouraging improvements as well as inevitable fallbacks, in the hope of raising fresh questions and motivating new research directions for the reader.