 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Distributed Pipeline for Scalable, Deconflicted Formation Flying
Mar 04, 2020
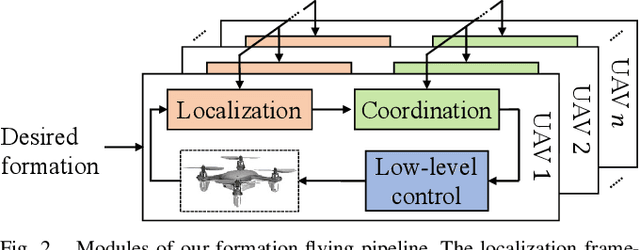

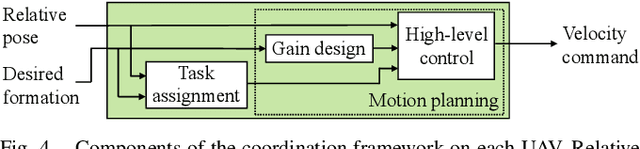
Reliance on external localization infrastructure and centralized coordination are main limiting factors for formation flying of vehicles in large numbers and in unprepared environments. While solutions using onboard localization address the dependency on external infrastructure, the associated coordination strategies typically lack collision avoidance and scalability. To address these shortcomings, we present a unified pipeline with onboard localization and a distributed, collision-free motion planning strategy that scales to a large number of vehicles. Since distributed collision avoidance strategies are known to result in gridlock, we also present a decentralized task assignment solution to deconflict vehicles. We experimentally validate our pipeline in simulation and hardware. The results show that our approach for solving the optimization problem associated with motion planning gives solutions within seconds in cases where general purpose solvers fail due to high complexity. In addition, our lightweight assignment strategy leads to successful and quicker formation convergence in 96-100% of all trials, whereas indefinite gridlocks occur without it for 33-50% of trials. By enabling large-scale, deconflicted coordination, this pipeline should help pave the way for anytime, anywhere deployment of aerial swarms.
Policy Distillation and Value Matching in Multiagent Reinforcement Learning
Mar 15, 2019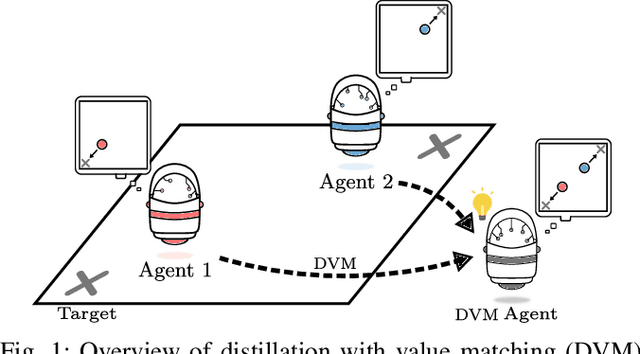
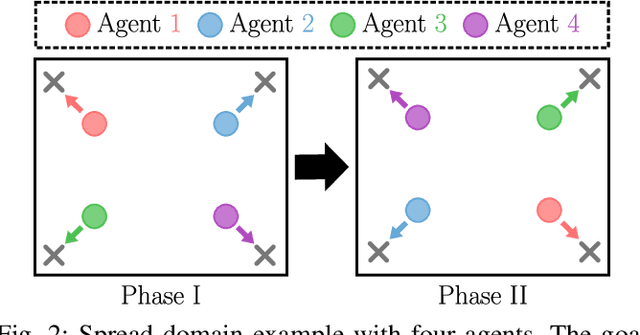
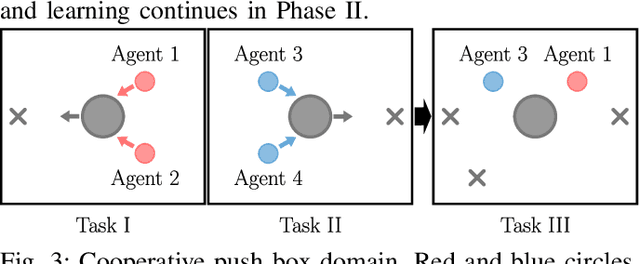

Multiagent reinforcement learning algorithms (MARL) have been demonstrated on complex tasks that require the coordination of a team of multiple agents to complete. Existing works have focused on sharing information between agents via centralized critics to stabilize learning or through communication to increase performance, but do not generally look at how information can be shared between agents to address the curse of dimensionality in MARL. We posit that a multiagent problem can be decomposed into a multi-task problem where each agent explores a subset of the state space instead of exploring the entire state space. This paper introduces a multiagent actor-critic algorithm and method for combining knowledge from homogeneous agents through distillation and value-matching that outperforms policy distillation alone and allows further learning in both discrete and continuous action spaces.