 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformers self-organize like newborn visual systems when trained in prenatal worlds
Jan 06, 2026Do transformers learn like brains? A key challenge in addressing this question is that transformers and brains are trained on fundamentally different data. Brains are initially "trained" on prenatal sensory experiences (e.g., retinal waves), whereas transformers are typically trained on large datasets that are not biologically plausible. We reasoned that if transformers learn like brains, then they should develop the same structure as newborn brains when exposed to the same prenatal data. To test this prediction, we simulated prenatal visual input using a retinal wave generator. Then, using self-supervised temporal learning, we trained transformers to adapt to those retinal waves. During training, the transformers spontaneously developed the same structure as newborn visual systems: (1) early layers became sensitive to edges, (2) later layers became sensitive to shapes, and (3) the models developed larger receptive fields across layers. The organization of newborn visual systems emerges spontaneously when transformers adapt to a prenatal visual world. This developmental convergence suggests that brains and transformers learn in common ways and follow the same general fitting principles.
Are Vision Transformers More Data Hungry Than Newborn Visual Systems?
Dec 05, 2023Vision transformers (ViTs) are top performing models on many computer vision benchmarks and can accurately predict human behavior on object recognition tasks. However, researchers question the value of using ViTs as models of biological learning because ViTs are thought to be more data hungry than brains, with ViTs requiring more training data to reach similar levels of performance. To test this assumption, we directly compared the learning abilities of ViTs and animals, by performing parallel controlled rearing experiments on ViTs and newborn chicks. We first raised chicks in impoverished visual environments containing a single object, then simulated the training data available in those environments by building virtual animal chambers in a video game engine. We recorded the first-person images acquired by agents moving through the virtual chambers and used those images to train self supervised ViTs that leverage time as a teaching signal, akin to biological visual systems. When ViTs were trained through the eyes of newborn chicks, the ViTs solved the same view invariant object recognition tasks as the chicks. Thus, ViTs were not more data hungry than newborn visual systems: both learned view invariant object representations in impoverished visual environments. The flexible and generic attention based learning mechanism in ViTs combined with the embodied data streams available to newborn animals appears sufficient to drive the development of animal-like object recognition.
A newborn embodied Turing test for view-invariant object recognition
Jun 08, 2023Recent progress in artificial intelligence has renewed interest in building machines that learn like animals. Almost all of the work comparing learning across biological and artificial systems comes from studies where animals and machines received different training data, obscuring whether differences between animals and machines emerged from differences in learning mechanisms versus training data. We present an experimental approach-a "newborn embodied Turing Test"-that allows newborn animals and machines to be raised in the same environments and tested with the same tasks, permitting direct comparison of their learning abilities. To make this platform, we first collected controlled-rearing data from newborn chicks, then performed "digital twin" experiments in which machines were raised in virtual environments that mimicked the rearing conditions of the chicks. We found that (1) machines (deep reinforcement learning agents with intrinsic motivation) can spontaneously develop visually guided preference behavior, akin to imprinting in newborn chicks, and (2) machines are still far from newborn-level performance on object recognition tasks. Almost all of the chicks developed view-invariant object recognition, whereas the machines tended to develop view-dependent recognition. The learning outcomes were also far more constrained in the chicks versus machines. Ultimately, we anticipate that this approach will help researchers develop embodied AI systems that learn like newborn animals.
Development of collective behavior in newborn artificial agents
Nov 06, 2021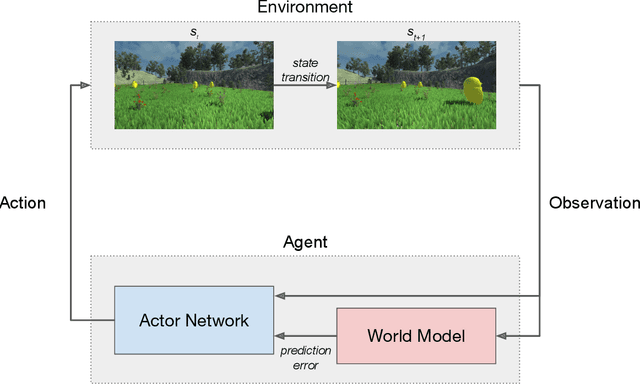
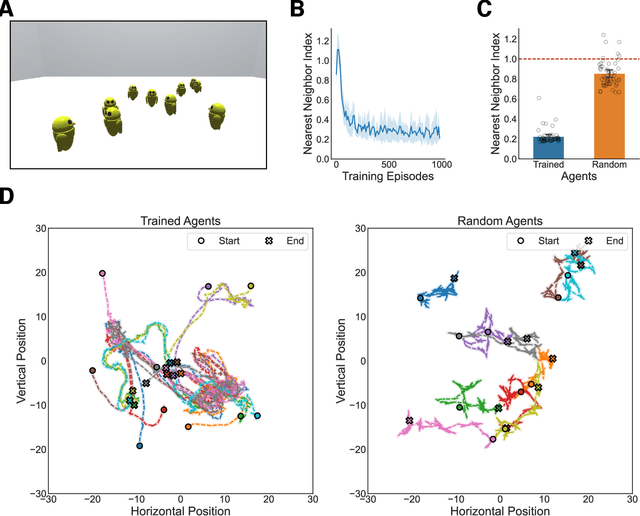
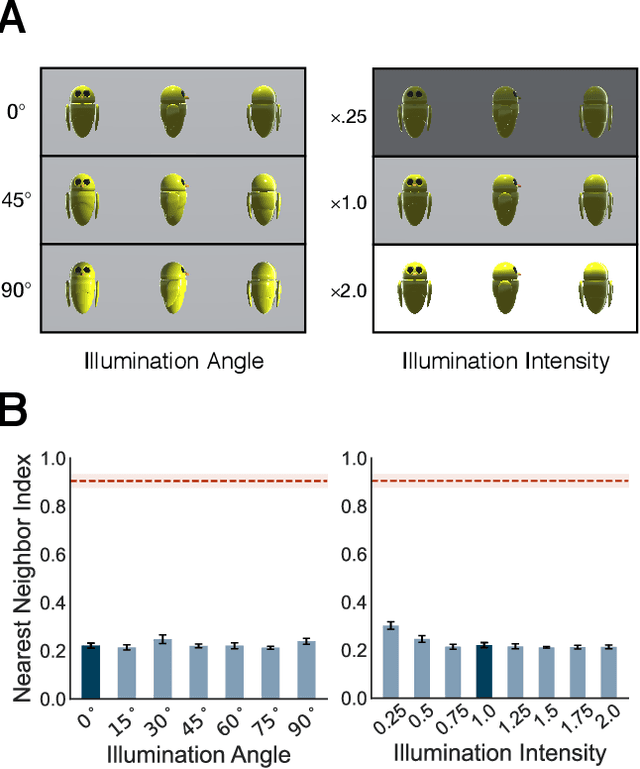
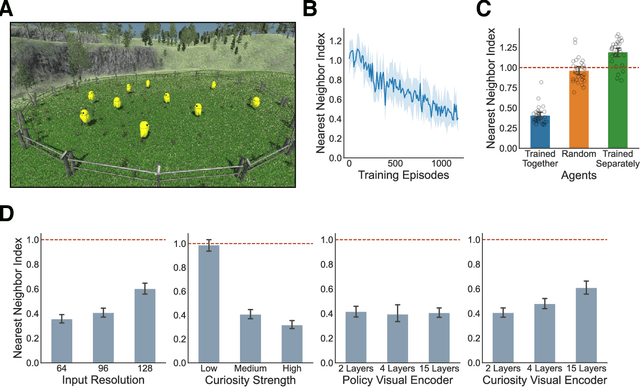
Collective behavior is widespread across the animal kingdom. To date, however, the developmental and mechanistic foundations of collective behavior have not been formally established. What learning mechanisms drive the development of collective behavior in newborn animals? Here, we used deep reinforcement learning and curiosity-driven learning -- two learning mechanisms deeply rooted in psychological and neuroscientific research -- to build newborn artificial agents that develop collective behavior. Like newborn animals, our agents learn collective behavior from raw sensory inputs in naturalistic environments. Our agents also learn collective behavior without external rewards, using only intrinsic motivation (curiosity) to drive learning. Specifically, when we raise our artificial agents in natural visual environments with groupmates, the agents spontaneously develop ego-motion, object recognition, and a preference for groupmates, rapidly learning all of the core skills required for collective behavior. This work bridges the divide between high-dimensional sensory inputs and collective action, resulting in a pixels-to-actions model of collective animal behavior. More generally, we show that two generic learning mechanisms -- deep reinforcement learning and curiosity-driven learning -- are sufficient to learn collective behavior from unsupervised natural experience.