 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncreasing the Inference and Learning Speed of Tsetlin Machines with Clause Indexing
Apr 07, 2020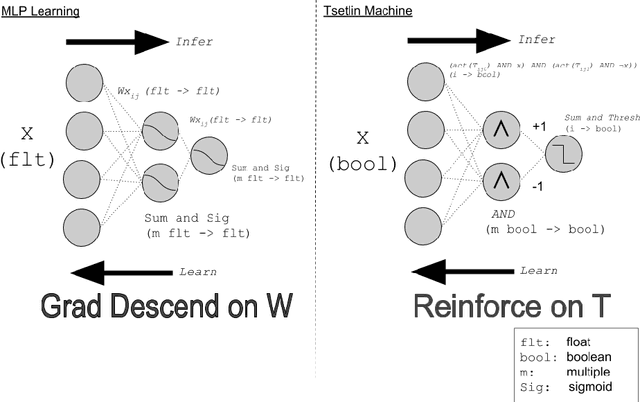
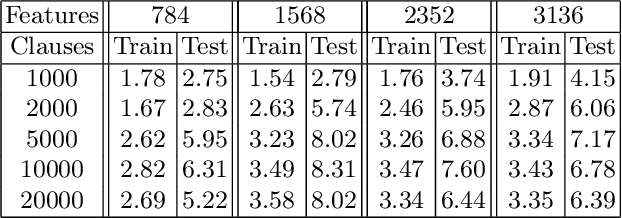
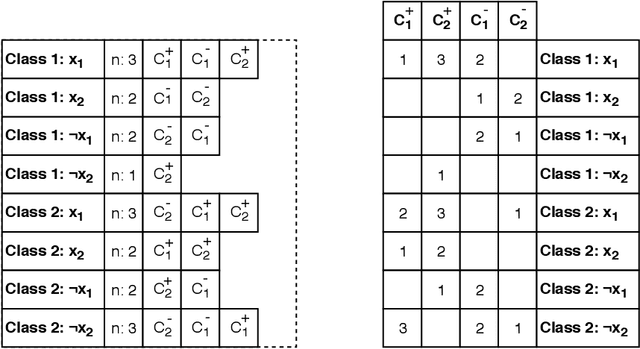
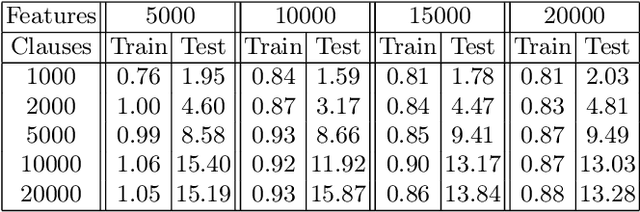
The Tsetlin Machine (TM) is a machine learning algorithm founded on the classical Tsetlin Automaton (TA) and game theory. It further leverages frequent pattern mining and resource allocation principles to extract common patterns in the data, rather than relying on minimizing output error, which is prone to overfitting. Unlike the intertwined nature of pattern representation in neural networks, a TM decomposes problems into self-contained patterns, represented as conjunctive clauses. The clause outputs, in turn, are combined into a classification decision through summation and thresholding, akin to a logistic regression function, however, with binary weights and a unit step output function. In this paper, we exploit this hierarchical structure by introducing a novel algorithm that avoids evaluating the clauses exhaustively. Instead we use a simple look-up table that indexes the clauses on the features that falsify them. In this manner, we can quickly evaluate a large number of clauses through falsification, simply by iterating through the features and using the look-up table to eliminate those clauses that are falsified. The look-up table is further structured so that it facilitates constant time updating, thus supporting use also during learning. We report up to 15 times faster classification and three times faster learning on MNIST and Fashion-MNIST image classification, and IMDb sentiment analysis.
The Weighted Tsetlin Machine: Compressed Representations with Weighted Clauses
Jan 14, 2020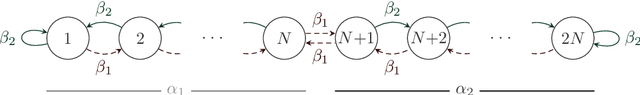

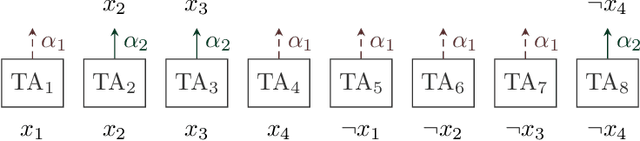
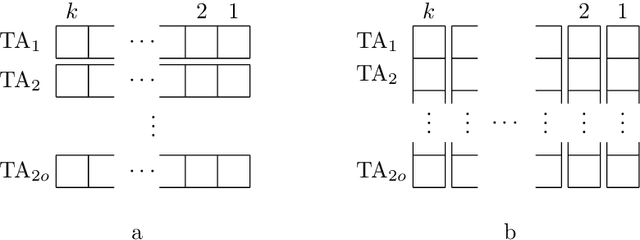
The Tsetlin Machine (TM) is an interpretable mechanism for pattern recognition that constructs conjunctive clauses from data. The clauses capture frequent patterns with high discriminating power, providing increasing expression power with each additional clause. However, the resulting accuracy gain comes at the cost of linear growth in computation time and memory usage. In this paper, we present the Weighted Tsetlin Machine (WTM), which reduces computation time and memory usage by weighting the clauses. Real-valued weighting allows one clause to replace multiple, and supports fine-tuning the impact of each clause. Our novel scheme simultaneously learns both the composition of the clauses and their weights. Furthermore, we increase training efficiency by replacing $k$ Bernoulli trials of success probability $p$ with a uniform sample of average size $p k$, the size drawn from a binomial distribution. In our empirical evaluation, the WTM achieved the same accuracy as the TM on MNIST, IMDb, and Connect-4, requiring only $1/4$, $1/3$, and $1/50$ of the clauses, respectively. With the same number of clauses, the WTM outperformed the TM, obtaining peak test accuracies of respectively $98.63\%$, $90.37\%$, and $87.91\%$. Finally, our novel sampling scheme reduced sample generation time by a factor of $7$.
A Tsetlin Machine with Multigranular Clauses
Sep 16, 2019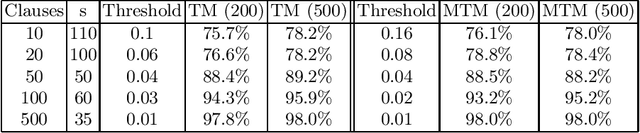
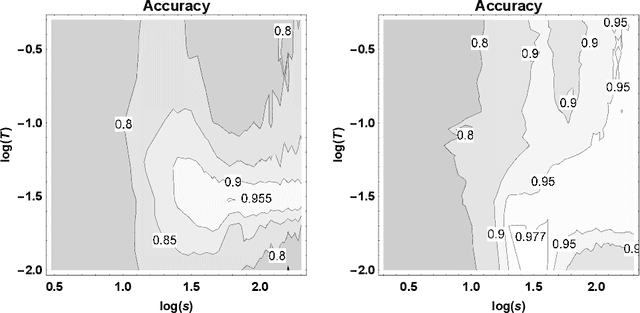
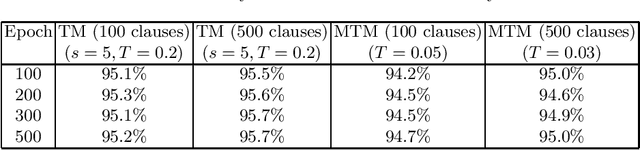
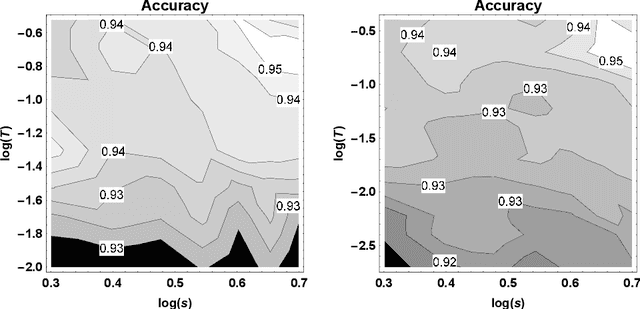
The recently introduced Tsetlin Machine (TM) has provided competitive pattern recognition accuracy in several benchmarks, however, requires a 3-dimensional hyperparameter search. In this paper, we introduce the Multigranular Tsetlin Machine (MTM). The MTM eliminates the specificity hyperparameter, used by the TM to control the granularity of the conjunctive clauses that it produces for recognizing patterns. Instead of using a fixed global specificity, we encode varying specificity as part of the clauses, rendering the clauses multigranular. This makes it easier to configure the TM because the dimensionality of the hyperparameter search space is reduced to only two dimensions. Indeed, it turns out that there is significantly less hyperparameter tuning involved in applying the MTM to new problems. Further, we demonstrate empirically that the MTM provides similar performance to what is achieved with a finely specificity-optimized TM, by comparing their performance on both synthetic and real-world datasets.