 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Tsetlin Machine with Multigranular Clauses
Paper and Code
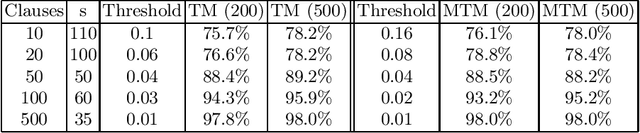
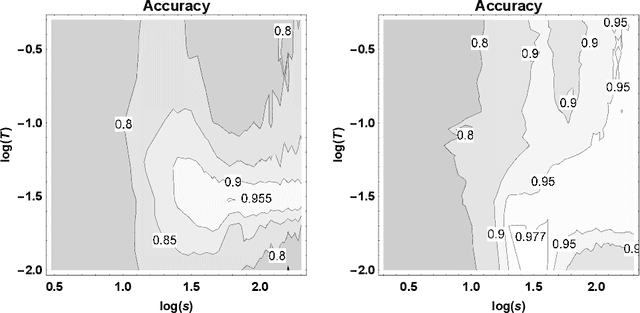
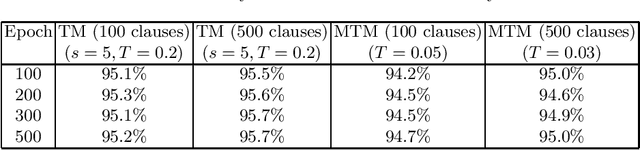
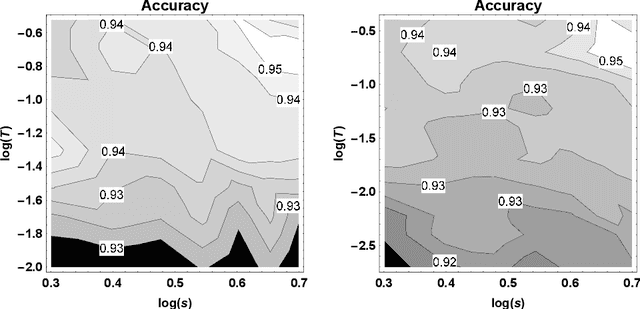
The recently introduced Tsetlin Machine (TM) has provided competitive pattern recognition accuracy in several benchmarks, however, requires a 3-dimensional hyperparameter search. In this paper, we introduce the Multigranular Tsetlin Machine (MTM). The MTM eliminates the specificity hyperparameter, used by the TM to control the granularity of the conjunctive clauses that it produces for recognizing patterns. Instead of using a fixed global specificity, we encode varying specificity as part of the clauses, rendering the clauses multigranular. This makes it easier to configure the TM because the dimensionality of the hyperparameter search space is reduced to only two dimensions. Indeed, it turns out that there is significantly less hyperparameter tuning involved in applying the MTM to new problems. Further, we demonstrate empirically that the MTM provides similar performance to what is achieved with a finely specificity-optimized TM, by comparing their performance on both synthetic and real-world datasets.