 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-supervised Learning in Network-Structured Data via Total Variation Minimization
Jan 28, 2019
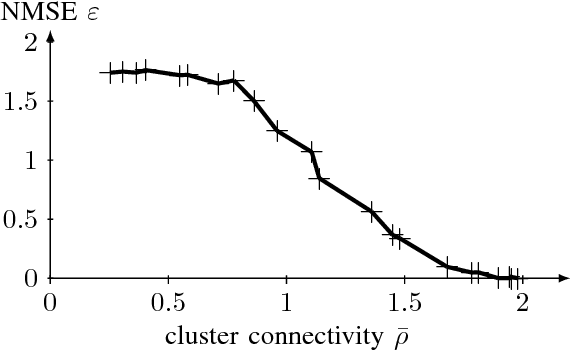
We propose and analyze a method for semi-supervised learning from partially-labeled network-structured data. Our approach is based on a graph signal recovery interpretation under a clustering hypothesis that labels of data points belonging to the same well-connected subset (cluster) are similar valued. This lends naturally to learning the labels by total variation (TV) minimization, which we solve by applying a recently proposed primal-dual method for non-smooth convex optimization. The resulting algorithm allows for a highly scalable implementation using message passing over the underlying empirical graph, which renders the algorithm suitable for big data applications. By applying tools of compressed sensing, we derive a sufficient condition on the underlying network structure such that TV minimization recovers clusters in the empirical graph of the data. In particular, we show that the proposed primal-dual method amounts to maximizing network flows over the empirical graph of the dataset. Moreover, the learning accuracy of the proposed algorithm is linked to the set of network flows between data points having known labels. The effectiveness and scalability of our approach is verified by numerical experiments.
Semi-Supervised Learning via Sparse Label Propagation
May 15, 2017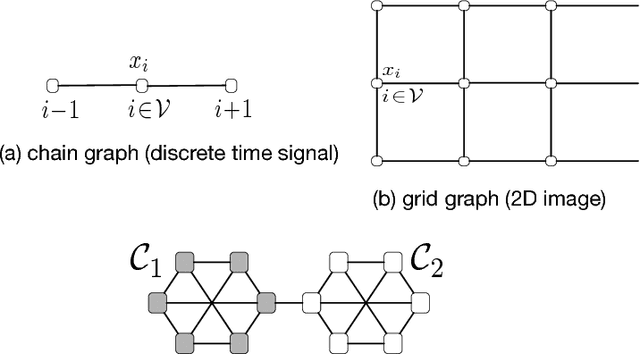
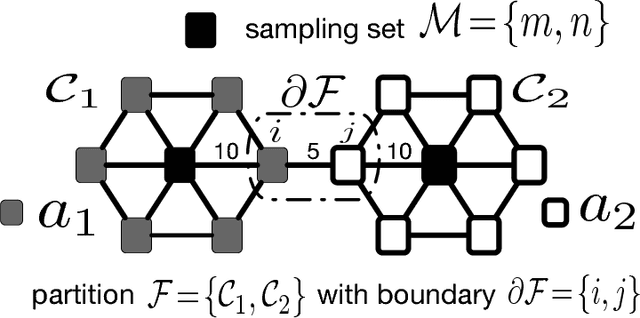
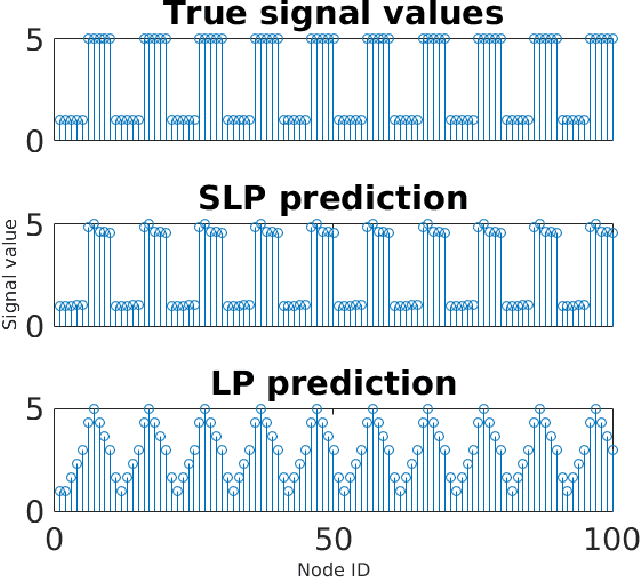
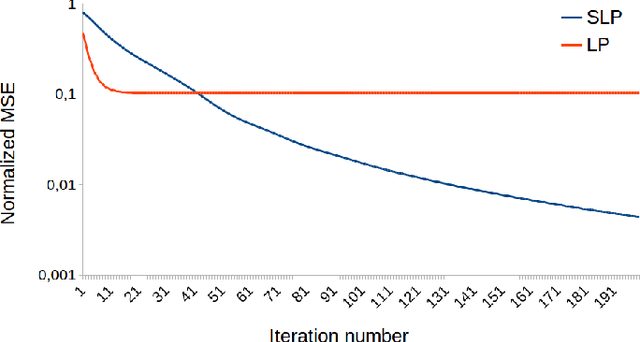
This work proposes a novel method for semi-supervised learning from partially labeled massive network-structured datasets, i.e., big data over networks. We model the underlying hypothesis, which relates data points to labels, as a graph signal, defined over some graph (network) structure intrinsic to the dataset. Following the key principle of supervised learning, i.e., similar inputs yield similar outputs, we require the graph signals induced by labels to have small total variation. Accordingly, we formulate the problem of learning the labels of data points as a non-smooth convex optimization problem which amounts to balancing between the empirical loss, i.e., the discrepancy with some partially available label information, and the smoothness quantified by the total variation of the learned graph signal. We solve this optimization problem by appealing to a recently proposed preconditioned variant of the popular primal-dual method by Pock and Chambolle, which results in a sparse label propagation algorithm. This learning algorithm allows for a highly scalable implementation as message passing over the underlying data graph. By applying concepts of compressed sensing to the learning problem, we are also able to provide a transparent sufficient condition on the underlying network structure such that accurate learning of the labels is possible. We also present an implementation of the message passing formulation allows for a highly scalable implementation in big data frameworks.