 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQUIET-SR: Quantum Image Enhancement Transformer for Single Image Super-Resolution
Mar 11, 2025



Recent advancements in Single-Image Super-Resolution (SISR) using deep learning have significantly improved image restoration quality. However, the high computational cost of processing high-resolution images due to the large number of parameters in classical models, along with the scalability challenges of quantum algorithms for image processing, remains a major obstacle. In this paper, we propose the Quantum Image Enhancement Transformer for Super-Resolution (QUIET-SR), a hybrid framework that extends the Swin transformer architecture with a novel shifted quantum window attention mechanism, built upon variational quantum neural networks. QUIET-SR effectively captures complex residual mappings between low-resolution and high-resolution images, leveraging quantum attention mechanisms to enhance feature extraction and image restoration while requiring a minimal number of qubits, making it suitable for the Noisy Intermediate-Scale Quantum (NISQ) era. We evaluate our framework in MNIST (30.24 PSNR, 0.989 SSIM), FashionMNIST (29.76 PSNR, 0.976 SSIM) and the MedMNIST dataset collection, demonstrating that QUIET-SR achieves PSNR and SSIM scores comparable to state-of-the-art methods while using fewer parameters. These findings highlight the potential of scalable variational quantum machine learning models for SISR, marking a step toward practical quantum-enhanced image super-resolution.
MQFL-FHE: Multimodal Quantum Federated Learning Framework with Fully Homomorphic Encryption
Nov 30, 2024
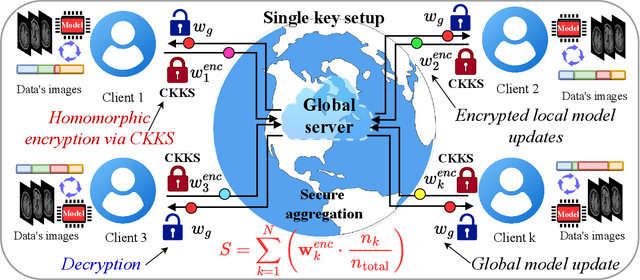
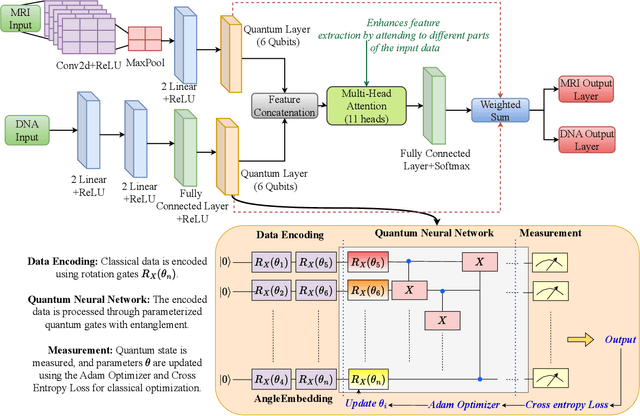

The integration of fully homomorphic encryption (FHE) in federated learning (FL) has led to significant advances in data privacy. However, during the aggregation phase, it often results in performance degradation of the aggregated model, hindering the development of robust representational generalization. In this work, we propose a novel multimodal quantum federated learning framework that utilizes quantum computing to counteract the performance drop resulting from FHE. For the first time in FL, our framework combines a multimodal quantum mixture of experts (MQMoE) model with FHE, incorporating multimodal datasets for enriched representation and task-specific learning. Our MQMoE framework enhances performance on multimodal datasets and combined genomics and brain MRI scans, especially for underrepresented categories. Our results also demonstrate that the quantum-enhanced approach mitigates the performance degradation associated with FHE and improves classification accuracy across diverse datasets, validating the potential of quantum interventions in enhancing privacy in FL.
Federated Learning with Quantum Computing and Fully Homomorphic Encryption: A Novel Computing Paradigm Shift in Privacy-Preserving ML
Sep 19, 2024


The widespread deployment of products powered by machine learning models is raising concerns around data privacy and information security worldwide. To address this issue, Federated Learning was first proposed as a privacy-preserving alternative to conventional methods that allow multiple learning clients to share model knowledge without disclosing private data. A complementary approach known as Fully Homomorphic Encryption (FHE) is a quantum-safe cryptographic system that enables operations to be performed on encrypted weights. However, implementing mechanisms such as these in practice often comes with significant computational overhead and can expose potential security threats. Novel computing paradigms, such as analog, quantum, and specialized digital hardware, present opportunities for implementing privacy-preserving machine learning systems while enhancing security and mitigating performance loss. This work instantiates these ideas by applying the FHE scheme to a Federated Learning Neural Network architecture that integrates both classical and quantum layers.
AQ-PINNs: Attention-Enhanced Quantum Physics-Informed Neural Networks for Carbon-Efficient Climate Modeling
Sep 03, 2024

The growing computational demands of artificial intelligence (AI) in addressing climate change raise significant concerns about inefficiencies and environmental impact, as highlighted by the Jevons paradox. We propose an attention-enhanced quantum physics-informed neural networks model (AQ-PINNs) to tackle these challenges. This approach integrates quantum computing techniques into physics-informed neural networks (PINNs) for climate modeling, aiming to enhance predictive accuracy in fluid dynamics governed by the Navier-Stokes equations while reducing the computational burden and carbon footprint. By harnessing variational quantum multi-head self-attention mechanisms, our AQ-PINNs achieve a 51.51% reduction in model parameters compared to classical multi-head self-attention methods while maintaining comparable convergence and loss. It also employs quantum tensor networks to enhance representational capacity, which can lead to more efficient gradient computations and reduced susceptibility to barren plateaus. Our AQ-PINNs represent a crucial step towards more sustainable and effective climate modeling solutions.
QADQN: Quantum Attention Deep Q-Network for Financial Market Prediction
Aug 06, 2024Financial market prediction and optimal trading strategy development remain challenging due to market complexity and volatility. Our research in quantum finance and reinforcement learning for decision-making demonstrates the approach of quantum-classical hybrid algorithms to tackling real-world financial challenges. In this respect, we corroborate the concept with rigorous backtesting and validate the framework's performance under realistic market conditions, by including fixed transaction cost per trade. This paper introduces a Quantum Attention Deep Q-Network (QADQN) approach to address these challenges through quantum-enhanced reinforcement learning. Our QADQN architecture uses a variational quantum circuit inside a traditional deep Q-learning framework to take advantage of possible quantum advantages in decision-making. We gauge the QADQN agent's performance on historical data from major market indices, including the S&P 500. We evaluate the agent's learning process by examining its reward accumulation and the effectiveness of its experience replay mechanism. Our empirical results demonstrate the QADQN's superior performance, achieving better risk-adjusted returns with Sortino ratios of 1.28 and 1.19 for non-overlapping and overlapping test periods respectively, indicating effective downside risk management.
Uncertainty in Automated Ontology Matching: Lessons Learned from an Empirical Experimentation
Oct 18, 2023



Data integration is considered a classic research field and a pressing need within the information science community. Ontologies play a critical role in such a process by providing well-consolidated support to link and semantically integrate datasets via interoperability. This paper approaches data integration from an application perspective, looking at techniques based on ontology matching. An ontology-based process may only be considered adequate by assuming manual matching of different sources of information. However, since the approach becomes unrealistic once the system scales up, automation of the matching process becomes a compelling need. Therefore, we have conducted experiments on actual data with the support of existing tools for automatic ontology matching from the scientific community. Even considering a relatively simple case study (i.e., the spatio-temporal alignment of global indicators), outcomes clearly show significant uncertainty resulting from errors and inaccuracies along the automated matching process. More concretely, this paper aims to test on real-world data a bottom-up knowledge-building approach, discuss the lessons learned from the experimental results of the case study, and draw conclusions about uncertainty and uncertainty management in an automated ontology matching process. While the most common evaluation metrics clearly demonstrate the unreliability of fully automated matching solutions, properly designed semi-supervised approaches seem to be mature for a more generalized application.
Accurate prediction of international trade flows: Leveraging knowledge graphs and their embeddings
Oct 17, 2023



Knowledge representation (KR) is vital in designing symbolic notations to represent real-world facts and facilitate automated decision-making tasks. Knowledge graphs (KGs) have emerged so far as a popular form of KR, offering a contextual and human-like representation of knowledge. In international economics, KGs have proven valuable in capturing complex interactions between commodities, companies, and countries. By putting the gravity model, which is a common economic framework, into the process of building KGs, important factors that affect trade relationships can be taken into account, making it possible to predict international trade patterns. This paper proposes an approach that leverages Knowledge Graph embeddings for modeling international trade, focusing on link prediction using embeddings. Thus, valuable insights are offered to policymakers, businesses, and economists, enabling them to anticipate the effects of changes in the international trade system. Moreover, the integration of traditional machine learning methods with KG embeddings, such as decision trees and graph neural networks are also explored. The research findings demonstrate the potential for improving prediction accuracy and provide insights into embedding explainability in knowledge representation. The paper also presents a comprehensive analysis of the influence of embedding methods on other intelligent algorithms.
Towards Unveiling the Ontology Key Features Altering Reasoner Performances
Sep 29, 2015


Reasoning with ontologies is one of the core fields of research in Description Logics. A variety of efficient reasoner with highly optimized algorithms have been developed to allow inference tasks on expressive ontology languages such as OWL(DL). However, reasoner reported computing times have exceeded and sometimes fall behind the expected theoretical values. From an empirical perspective, it is not yet well understood, which particular aspects in the ontology are reasoner performance degrading factors. In this paper, we conducted an investigation about state of art works that attempted to portray potential correlation between reasoner empirical behaviour and particular ontological features. These works were analysed and then broken down into categories. Further, we proposed a set of ontology features covering a broad range of structural and syntactic ontology characteristics. We claim that these features are good indicators of the ontology hardness level against reasoning tasks.