 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen data for Moroccan license plates for OCR applications : data collection, labeling, and model construction
Apr 16, 2021

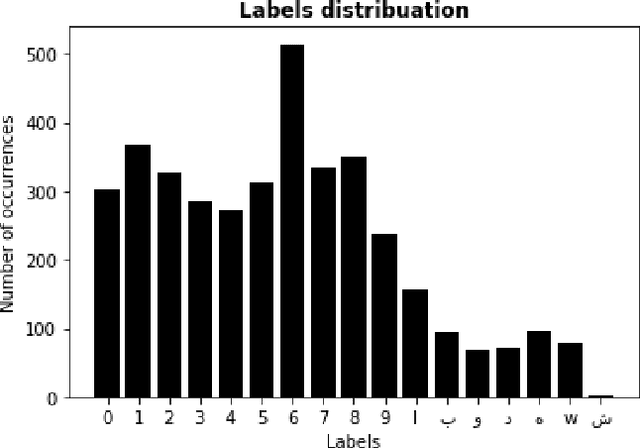

Significant number of researches have been developed recently around intelligent system for traffic management, especially, OCR based license plate recognition, as it is considered as a main step for any automatic traffic management system. Good quality data sets are increasingly needed and produced by the research community to improve the performance of those algorithms. Furthermore, a special need of data is noted for countries having special characters on their licence plates, like Morocco, where Arabic Alphabet is used. In this work, we present a labeled open data set of circulation plates taken in Morocco, for different type of vehicles, namely cars, trucks and motorcycles. This data was collected manually and consists of 705 unique and different images. Furthermore this data was labeled for plate segmentation and for matriculation number OCR. Also, As we show in this paper, the data can be enriched using data augmentation techniques to create training sets with few thousands of images for different machine leaning and AI applications. We present and compare a set of models built on this data. Also, we publish this data as an open access data to encourage innovation and applications in the field of OCR and image processing for traffic control and other applications for transportation and heterogeneous vehicle management.
An open access NLP dataset for Arabic dialects : Data collection, labeling, and model construction
Feb 07, 2021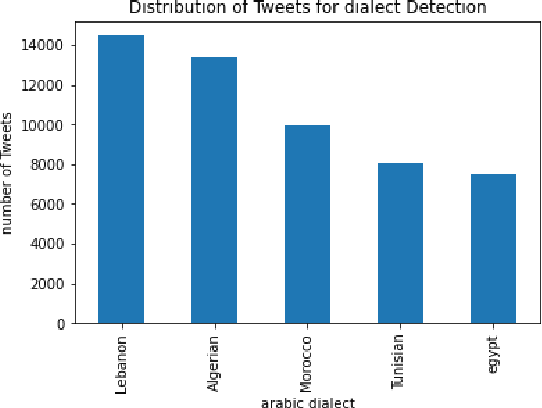
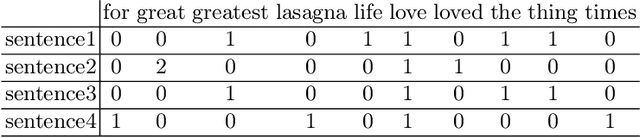
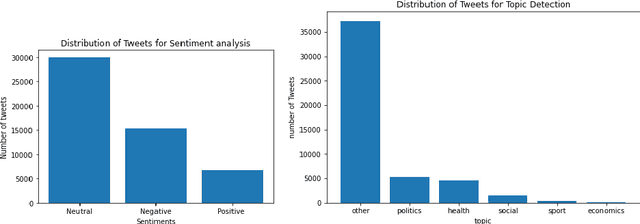

Natural Language Processing (NLP) is today a very active field of research and innovation. Many applications need however big sets of data for supervised learning, suitably labelled for the training purpose. This includes applications for the Arabic language and its national dialects. However, such open access labeled data sets in Arabic and its dialects are lacking in the Data Science ecosystem and this lack can be a burden to innovation and research in this field. In this work, we present an open data set of social data content in several Arabic dialects. This data was collected from the Twitter social network and consists on +50K twits in five (5) national dialects. Furthermore, this data was labeled for several applications, namely dialect detection, topic detection and sentiment analysis. We publish this data as an open access data to encourage innovation and encourage other works in the field of NLP for Arabic dialects and social media. A selection of models were built using this data set and are presented in this paper along with their performances.