 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn open access NLP dataset for Arabic dialects : Data collection, labeling, and model construction
Paper and Code
Feb 07, 2021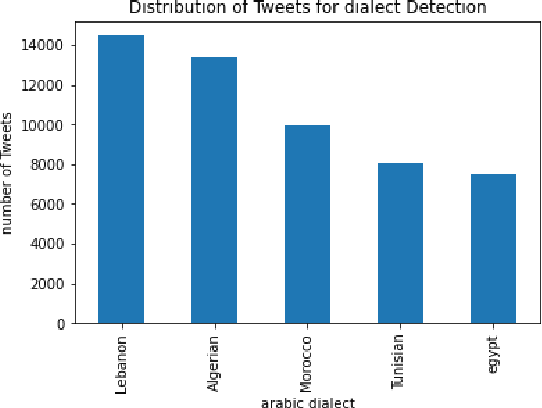
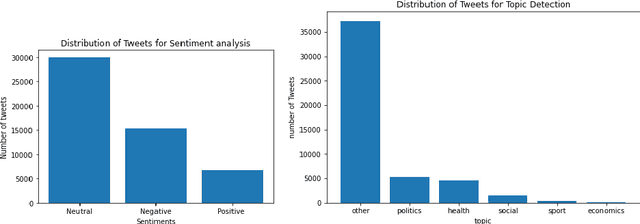

Natural Language Processing (NLP) is today a very active field of research and innovation. Many applications need however big sets of data for supervised learning, suitably labelled for the training purpose. This includes applications for the Arabic language and its national dialects. However, such open access labeled data sets in Arabic and its dialects are lacking in the Data Science ecosystem and this lack can be a burden to innovation and research in this field. In this work, we present an open data set of social data content in several Arabic dialects. This data was collected from the Twitter social network and consists on +50K twits in five (5) national dialects. Furthermore, this data was labeled for several applications, namely dialect detection, topic detection and sentiment analysis. We publish this data as an open access data to encourage innovation and encourage other works in the field of NLP for Arabic dialects and social media. A selection of models were built using this data set and are presented in this paper along with their performances.