 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Multimodal Word Discovery based on Double Articulation Analysis with Co-occurrence cues
Jan 18, 2022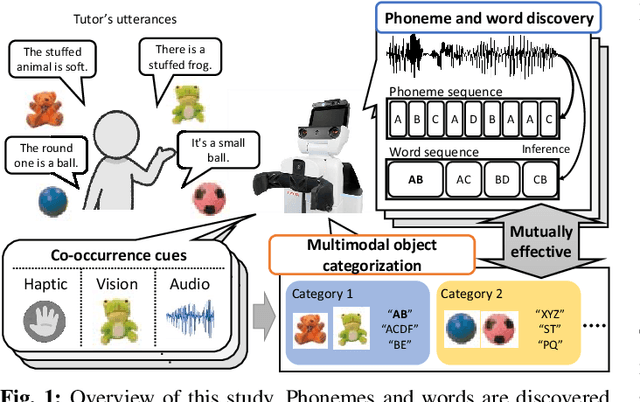
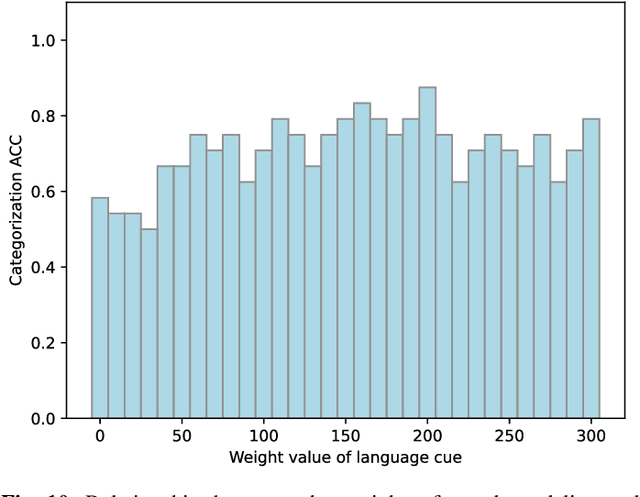
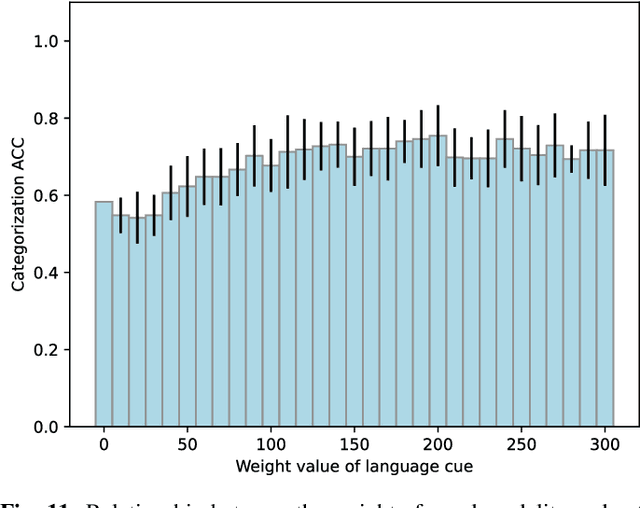
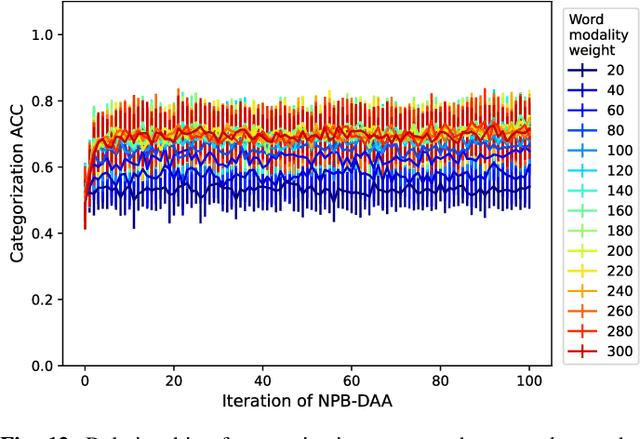
Human infants acquire their verbal lexicon from minimal prior knowledge of language based on the statistical properties of phonological distributions and the co-occurrence of other sensory stimuli. In this study, we propose a novel fully unsupervised learning method discovering speech units by utilizing phonological information as a distributional cue and object information as a co-occurrence cue. The proposed method can not only (1) acquire words and phonemes from speech signals using unsupervised learning, but can also (2) utilize object information based on multiple modalities (i.e., vision, tactile, and auditory) simultaneously. The proposed method is based on the Nonparametric Bayesian Double Articulation Analyzer (NPB-DAA) discovering phonemes and words from phonological features, and Multimodal Latent Dirichlet Allocation (MLDA) categorizing multimodal information obtained from objects. In the experiment, the proposed method showed higher word discovery performance than the baseline methods. In particular, words that expressed the characteristics of the object (i.e., words corresponding to nouns and adjectives) were segmented accurately. Furthermore, we examined how learning performance is affected by differences in the importance of linguistic information. When the weight of the word modality was increased, the performance was further improved compared to the fixed condition.
StarGAN-based Emotional Voice Conversion for Japanese Phrases
Apr 05, 2021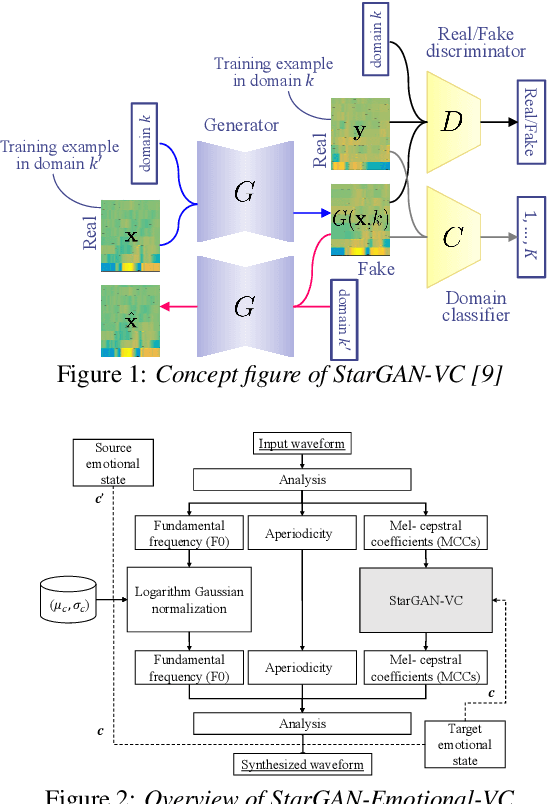
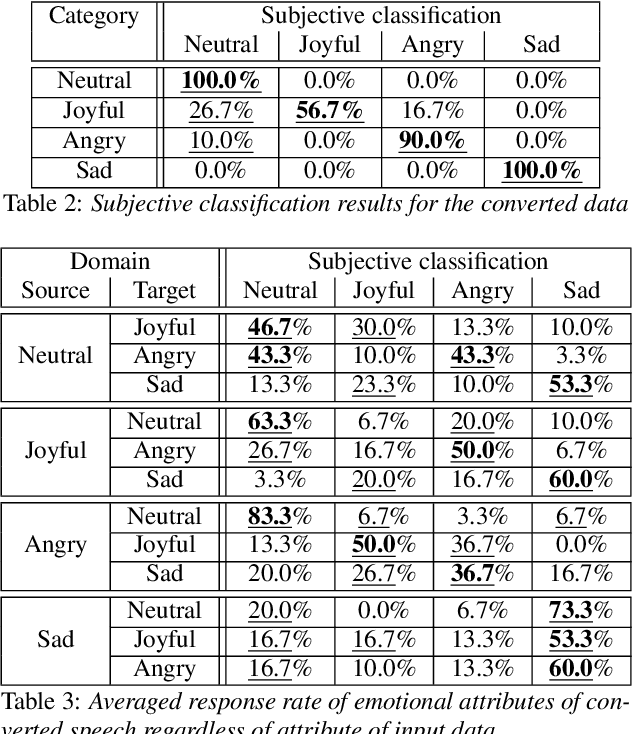
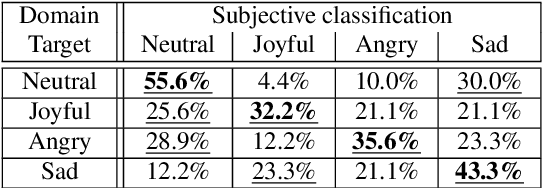
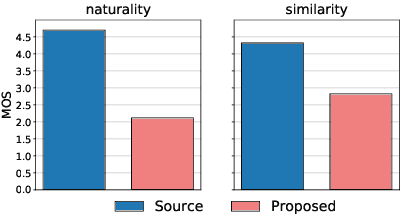
This paper shows that StarGAN-VC, a spectral envelope transformation method for non-parallel many-to-many voice conversion (VC), is capable of emotional VC (EVC). Although StarGAN-VC has been shown to enable speaker identity conversion, its capability for EVC for Japanese phrases has not been clarified. In this paper, we describe the direct application of StarGAN-VC to an EVC task with minimal fundamental frequency and aperiodicity processing. Through subjective evaluation experiments, we evaluated the performance of our StarGAN-EVC system in terms of its ability to achieve EVC for Japanese phrases. The subjective evaluation is conducted in terms of subjective classification and mean opinion score of neutrality and similarity. In addition, the interdependence between the source and target emotional domains was investigated from the perspective of the quality of EVC.
Double Articulation Analyzer with Prosody for Unsupervised Word and Phoneme Discovery
Mar 15, 2021Infants acquire words and phonemes from unsegmented speech signals using segmentation cues, such as distributional, prosodic, and co-occurrence cues. Many pre-existing computational models that represent the process tend to focus on distributional or prosodic cues. This paper proposes a nonparametric Bayesian probabilistic generative model called the prosodic hierarchical Dirichlet process-hidden language model (Prosodic HDP-HLM). Prosodic HDP-HLM, an extension of HDP-HLM, considers both prosodic and distributional cues within a single integrative generative model. We conducted three experiments on different types of datasets, and demonstrate the validity of the proposed method. The results show that the Prosodic DAA successfully uses prosodic cues and outperforms a method that solely uses distributional cues. The main contributions of this study are as follows: 1) We develop a probabilistic generative model for time series data including prosody that potentially has a double articulation structure; 2) We propose the Prosodic DAA by deriving the inference procedure for Prosodic HDP-HLM and show that Prosodic DAA can discover words directly from continuous human speech signals using statistical information and prosodic information in an unsupervised manner; 3) We show that prosodic cues contribute to word segmentation more in naturally distributed case words, i.e., they follow Zipf's law.