 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Multimodal Word Discovery based on Double Articulation Analysis with Co-occurrence cues
Paper and Code
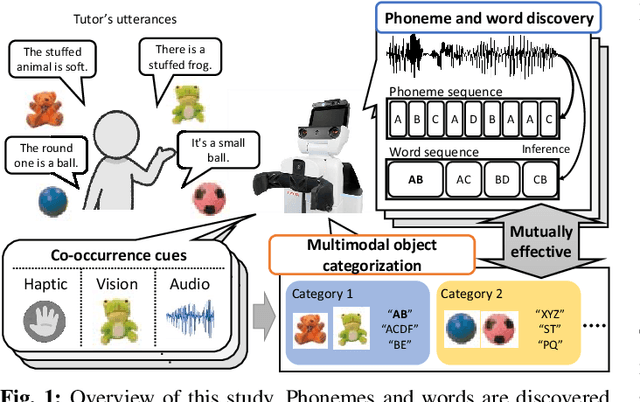
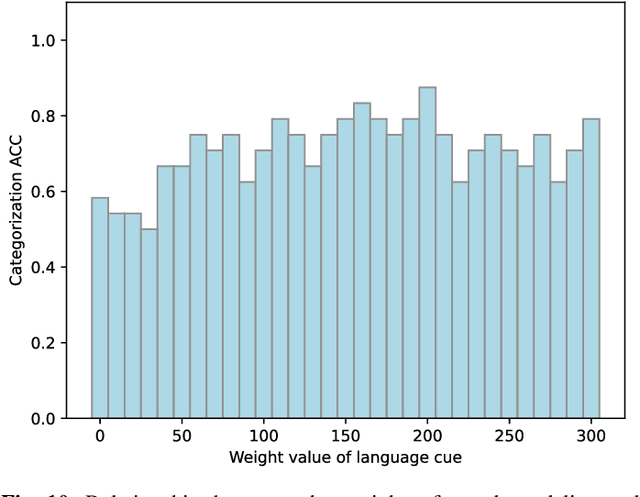
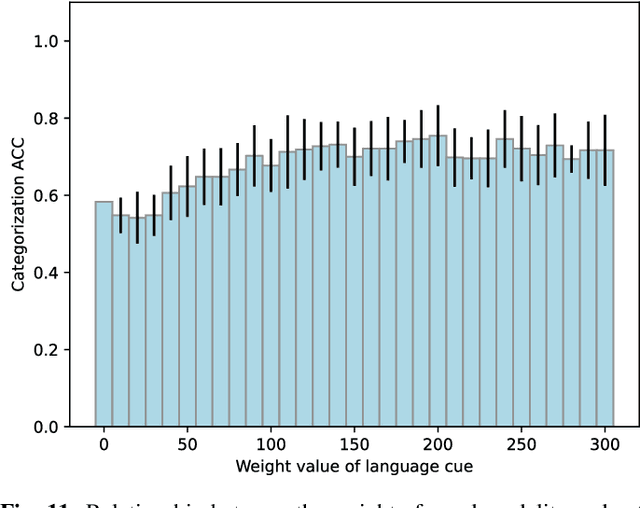
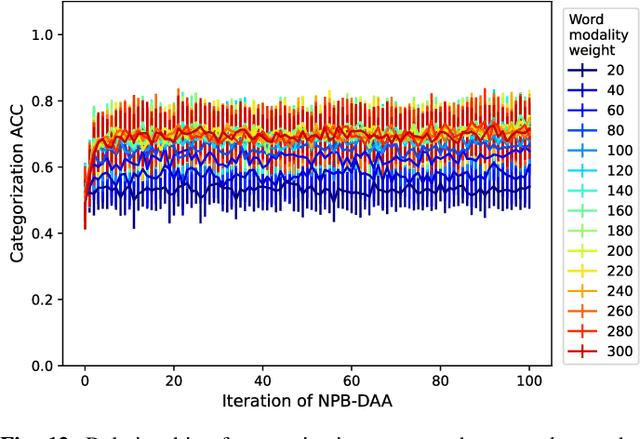
Human infants acquire their verbal lexicon from minimal prior knowledge of language based on the statistical properties of phonological distributions and the co-occurrence of other sensory stimuli. In this study, we propose a novel fully unsupervised learning method discovering speech units by utilizing phonological information as a distributional cue and object information as a co-occurrence cue. The proposed method can not only (1) acquire words and phonemes from speech signals using unsupervised learning, but can also (2) utilize object information based on multiple modalities (i.e., vision, tactile, and auditory) simultaneously. The proposed method is based on the Nonparametric Bayesian Double Articulation Analyzer (NPB-DAA) discovering phonemes and words from phonological features, and Multimodal Latent Dirichlet Allocation (MLDA) categorizing multimodal information obtained from objects. In the experiment, the proposed method showed higher word discovery performance than the baseline methods. In particular, words that expressed the characteristics of the object (i.e., words corresponding to nouns and adjectives) were segmented accurately. Furthermore, we examined how learning performance is affected by differences in the importance of linguistic information. When the weight of the word modality was increased, the performance was further improved compared to the fixed condition.