 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReasoning Models Can be Accurately Pruned Via Chain-of-Thought Reconstruction
Sep 15, 2025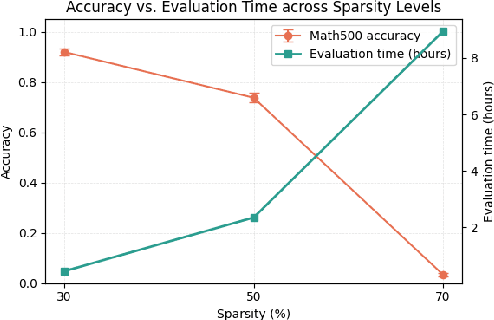
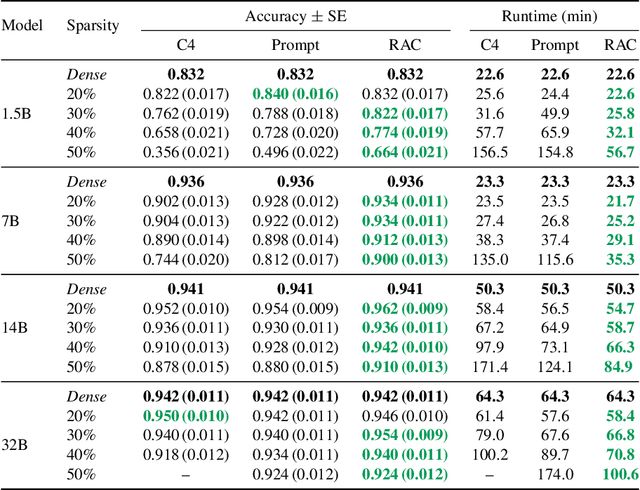
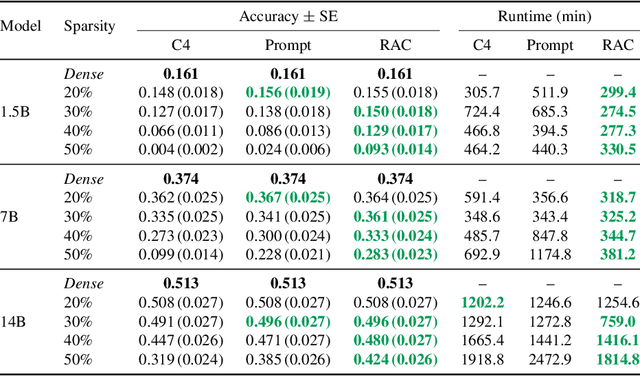
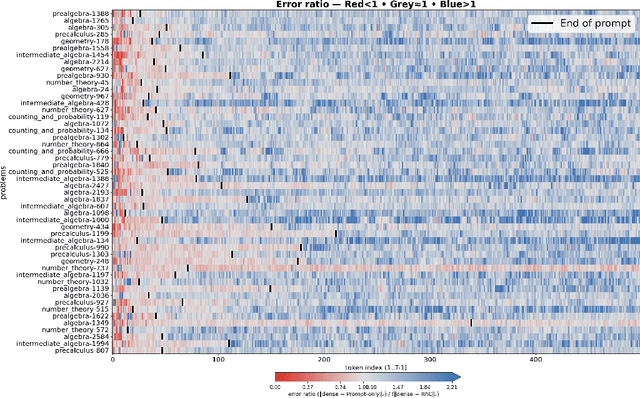
Reasoning language models such as DeepSeek-R1 produce long chain-of-thought traces during inference time which make them costly to deploy at scale. We show that using compression techniques such as neural network pruning produces greater performance loss than in typical language modeling tasks, and in some cases can make the model slower since they cause the model to produce more thinking tokens but with worse performance. We show that this is partly due to the fact that standard LLM pruning methods often focus on input reconstruction, whereas reasoning is a decode-dominated task. We introduce a simple, drop-in fix: during pruning we jointly reconstruct activations from the input and the model's on-policy chain-of-thought traces. This "Reasoning-Aware Compression" (RAC) integrates seamlessly into existing pruning workflows such as SparseGPT, and boosts their performance significantly. Code reproducing the results in the paper can be found at: https://github.com/RyanLucas3/RAC
Preserving Deep Representations In One-Shot Pruning: A Hessian-Free Second-Order Optimization Framework
Nov 27, 2024



We present SNOWS, a one-shot post-training pruning framework aimed at reducing the cost of vision network inference without retraining. Current leading one-shot pruning methods minimize layer-wise least squares reconstruction error which does not take into account deeper network representations. We propose to optimize a more global reconstruction objective. This objective accounts for nonlinear activations deep in the network to obtain a better proxy for the network loss. This nonlinear objective leads to a more challenging optimization problem -- we demonstrate it can be solved efficiently using a specialized second-order optimization framework. A key innovation of our framework is the use of Hessian-free optimization to compute exact Newton descent steps without needing to compute or store the full Hessian matrix. A distinct advantage of SNOWS is that it can be readily applied on top of any sparse mask derived from prior methods, readjusting their weights to exploit nonlinearities in deep feature representations. SNOWS obtains state-of-the-art results on various one-shot pruning benchmarks including residual networks and Vision Transformers (ViT/B-16 and ViT/L-16, 86m and 304m parameters respectively).
Certified Robust Neural Networks: Generalization and Corruption Resistance
Mar 03, 2023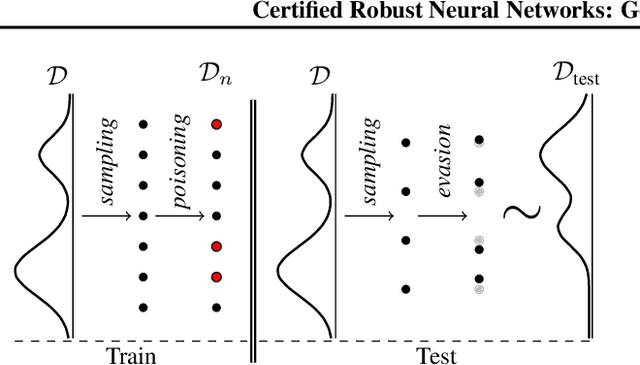

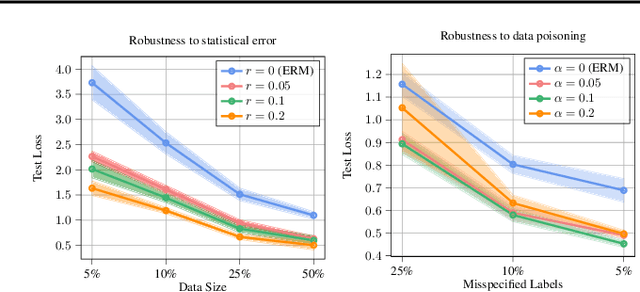

Adversarial training aims to reduce the problematic susceptibility of modern neural networks to small data perturbations. Surprisingly, overfitting is a major concern in adversarial training of neural networks despite being mostly absent in standard training. We provide here theoretical evidence for this peculiar ``robust overfitting'' phenomenon. Subsequently, we advance a novel loss function which we show both theoretically as well as empirically to enjoy a certified level of robustness against data evasion and poisoning attacks while ensuring guaranteed generalization. We indicate through careful numerical experiments that our resulting holistic robust (HR) training procedure yields SOTA performance in terms of adversarial error loss. Finally, we indicate that HR training can be interpreted as a direct extension of adversarial training and comes with a negligible additional computational burden.
Adaptive Learning on Time Series: Method and Financial Applications
Nov 17, 2021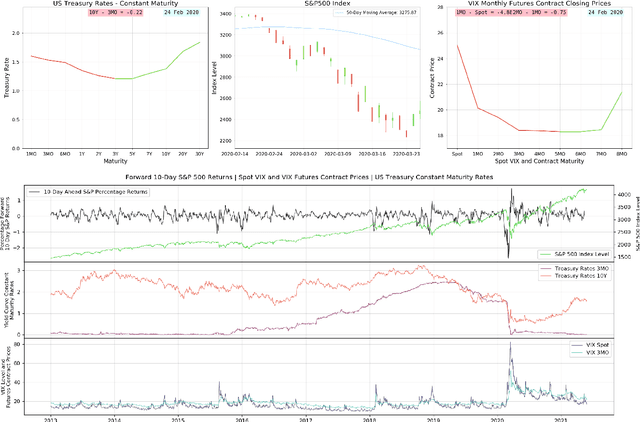
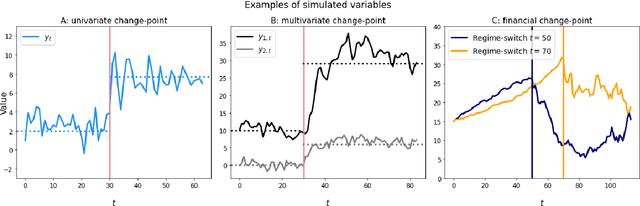
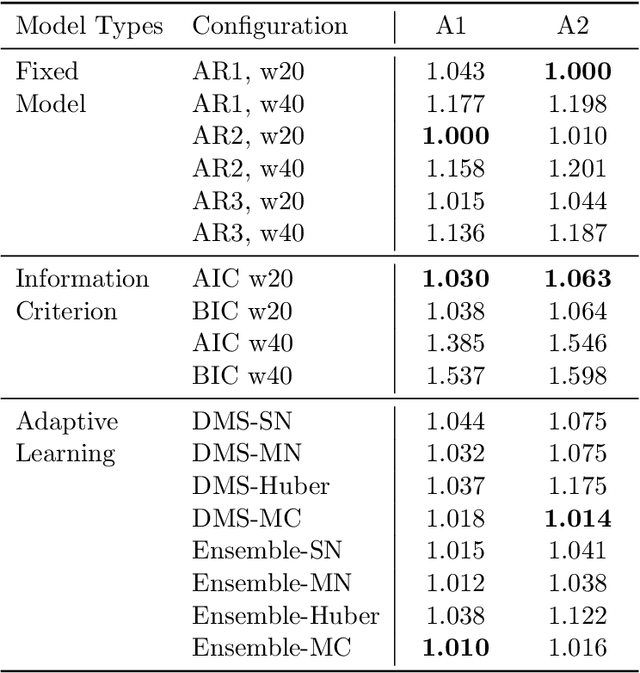
We formally introduce a time series statistical learning method, called Adaptive Learning, capable of handling model selection, out-of-sample forecasting and interpretation in a noisy environment. Through simulation studies we demonstrate that the method can outperform traditional model selection techniques such as AIC and BIC in the presence of regime-switching, as well as facilitating window size determination when the Data Generating Process is time-varying. Empirically, we use the method to forecast S&P 500 returns across multiple forecast horizons, employing information from the VIX Curve and the Yield Curve. We find that Adaptive Learning models are generally on par with, if not better than, the best of the parametric models a posteriori, evaluated in terms of MSE, while also outperforming under cross validation. We present a financial application of the learning results and an interpretation of the learning regime during the 2020 market crash. These studies can be extended in both a statistical direction and in terms of financial applications.