 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSinFoS: A Parallel Dataset for Translating Sinhala Figures of Speech
Feb 09, 2026Figures of Speech (FoS) consist of multi-word phrases that are deeply intertwined with culture. While Neural Machine Translation (NMT) performs relatively well with the figurative expressions of high-resource languages, it often faces challenges when dealing with low-resource languages like Sinhala due to limited available data. To address this limitation, we introduce a corpus of 2,344 Sinhala figures of speech with cultural and cross-lingual annotations. We examine this dataset to classify the cultural origins of the figures of speech and to identify their cross-lingual equivalents. Additionally, we have developed a binary classifier to differentiate between two types of FOS in the dataset, achieving an accuracy rate of approximately 92%. We also evaluate the performance of existing LLMs on this dataset. Our findings reveal significant shortcomings in the current capabilities of LLMs, as these models often struggle to accurately convey idiomatic meanings. By making this dataset publicly available, we offer a crucial benchmark for future research in low-resource NLP and culturally aware machine translation.
A Comprehensive Benchmark of Language Models on Unicode and Romanized Sinhala
Jan 21, 2026The performance of Language Models (LMs) on lower-resource, morphologically rich languages like Sinhala remains under-explored, particularly for Romanized Sinhala, which is prevalent in digital communication. This paper presents a comprehensive benchmark of modern LMs on a diverse corpus of Unicode and Romanized Sinhala. We evaluate open-source models using perplexity, a measure of how well a model predicts a text, and leading closed-source models via a qualitative analysis of sentence completion. Our findings reveal that the Mistral-Nemo-Base-2407 model achieves the strongest predictive performance on Unicode text and the Mistral-7B-v0.3 model for Romanized text. The results also highlight the strong all-around performance of the Llama-3.1-8B model for both scripts. Furthermore, a significant performance disparity exists among closed-source models: Gemini-1.5-pro and DeepSeek excel at Unicode generation, whereas Claude-3.5-Sonnet is superior at handling Romanized text. These results provide an essential guide for practitioners selecting models for Sinhala-specific applications and highlight the critical role of training data in handling script variations.
A Hybrid Architecture with Efficient Fine Tuning for Abstractive Patent Document Summarization
Mar 13, 2025


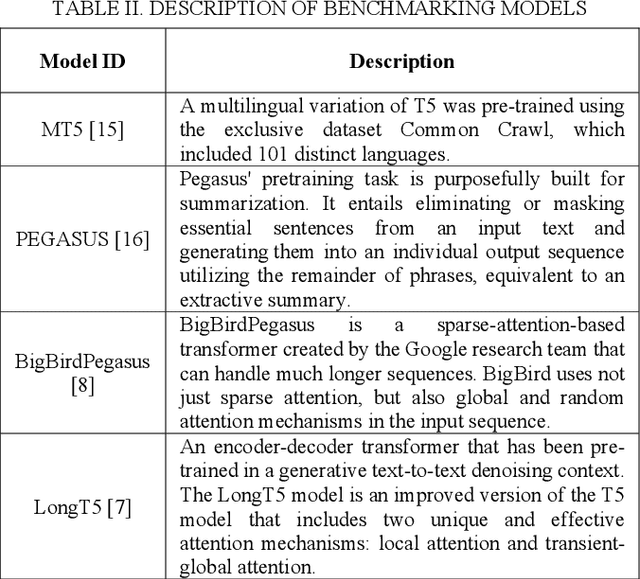
Automatic patent summarization approaches that help in the patent analysis and comprehension procedure are in high demand due to the colossal growth of innovations. The development of natural language processing (NLP), text mining, and deep learning has notably amplified the efficacy of text summarization models for abundant types of documents. Summarizing patent text remains a pertinent challenge due to the labyrinthine writing style of these documents, which includes technical and legal intricacies. Additionally, these patent document contents are considerably lengthier than archetypal documents, which intricates the process of extracting pertinent information for summarization. Embodying extractive and abstractive text summarization methodologies into a hybrid framework, this study proposes a system for efficiently creating abstractive summaries of patent records. The procedure involves leveraging the LexRank graph-based algorithm to retrieve the important sentences from input parent texts, then utilizing a Bidirectional Auto-Regressive Transformer (BART) model that has been fine-tuned using Low-Ranking Adaptation (LoRA) for producing text summaries. This is accompanied by methodical testing and evaluation strategies. Furthermore, the author employed certain meta-learning techniques to achieve Domain Generalization (DG) of the abstractive component across multiple patent fields.
Advancements in Natural Language Processing for Automatic Text Summarization
Feb 27, 2025



The substantial growth of textual content in diverse domains and platforms has led to a considerable need for Automatic Text Summarization (ATS) techniques that aid in the process of text analysis. The effectiveness of text summarization models has been significantly enhanced in a variety of technical domains because of advancements in Natural Language Processing (NLP) and Deep Learning (DL). Despite this, the process of summarizing textual information continues to be significantly constrained by the intricate writing styles of a variety of texts, which involve a range of technical complexities. Text summarization techniques can be broadly categorized into two main types: abstractive summarization and extractive summarization. Extractive summarization involves directly extracting sentences, phrases, or segments of text from the content without making any changes. On the other hand, abstractive summarization is achieved by reconstructing the sentences, phrases, or segments from the original text using linguistic analysis. Through this study, a linguistically diverse categorizations of text summarization approaches have been addressed in a constructive manner. In this paper, the authors explored existing hybrid techniques that have employed both extractive and abstractive methodologies. In addition, the pros and cons of various approaches discussed in the literature are also investigated. Furthermore, the authors conducted a comparative analysis on different techniques and matrices to evaluate the generated summaries using language generation models. This survey endeavors to provide a comprehensive overview of ATS by presenting the progression of language processing regarding this task through a breakdown of diverse systems and architectures accompanied by technical and mathematical explanations of their operations.
* 11 pages, 9 figures, ICCS 2024
IndoNLP 2025: Shared Task on Real-Time Reverse Transliteration for Romanized Indo-Aryan languages
Jan 15, 2025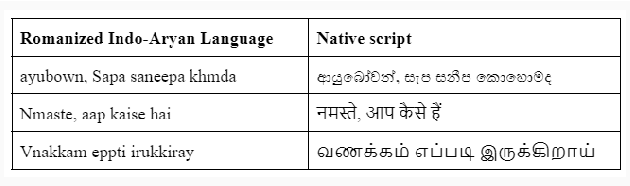



The paper overviews the shared task on Real-Time Reverse Transliteration for Romanized Indo-Aryan languages. It focuses on the reverse transliteration of low-resourced languages in the Indo-Aryan family to their native scripts. Typing Romanized Indo-Aryan languages using ad-hoc transliterals and achieving accurate native scripts are complex and often inaccurate processes with the current keyboard systems. This task aims to introduce and evaluate a real-time reverse transliterator that converts Romanized Indo-Aryan languages to their native scripts, improving the typing experience for users. Out of 11 registered teams, four teams participated in the final evaluation phase with transliteration models for Sinhala, Hindi and Malayalam. These proposed solutions not only solve the issue of ad-hoc transliteration but also empower low-resource language usability in the digital arena.
CBR-RAG: Case-Based Reasoning for Retrieval Augmented Generation in LLMs for Legal Question Answering
Apr 04, 2024



Retrieval-Augmented Generation (RAG) enhances Large Language Model (LLM) output by providing prior knowledge as context to input. This is beneficial for knowledge-intensive and expert reliant tasks, including legal question-answering, which require evidence to validate generated text outputs. We highlight that Case-Based Reasoning (CBR) presents key opportunities to structure retrieval as part of the RAG process in an LLM. We introduce CBR-RAG, where CBR cycle's initial retrieval stage, its indexing vocabulary, and similarity knowledge containers are used to enhance LLM queries with contextually relevant cases. This integration augments the original LLM query, providing a richer prompt. We present an evaluation of CBR-RAG, and examine different representations (i.e. general and domain-specific embeddings) and methods of comparison (i.e. inter, intra and hybrid similarity) on the task of legal question-answering. Our results indicate that the context provided by CBR's case reuse enforces similarity between relevant components of the questions and the evidence base leading to significant improvements in the quality of generated answers.