 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Exploration-Analysis-Disambiguation Reasoning Framework for Word Sense Disambiguation with Low-Parameter LLMs
Mar 05, 2026Word Sense Disambiguation (WSD) remains a key challenge in Natural Language Processing (NLP), especially when dealing with rare or domain-specific senses that are often misinterpreted. While modern high-parameter Large Language Models (LLMs) such as GPT-4-Turbo have shown state-of-the-art WSD performance, their computational and energy demands limit scalability. This study investigates whether low-parameter LLMs (<4B parameters) can achieve comparable results through fine-tuning strategies that emphasize reasoning-driven sense identification. Using the FEWS dataset augmented with semi-automated, rationale-rich annotations, we fine-tune eight small-scale open-source LLMs (e.g. Gemma and Qwen). Our results reveal that Chain-of-Thought (CoT)-based reasoning combined with neighbour-word analysis achieves performance comparable to GPT-4-Turbo in zero-shot settings. Importantly, Gemma-3-4B and Qwen-3-4B models consistently outperform all medium-parameter baselines and state-of-the-art models on FEWS, with robust generalization to unseen senses. Furthermore, evaluation on the unseen "Fool Me If You Can'' dataset confirms strong cross-domain adaptability without task-specific fine-tuning. This work demonstrates that with carefully crafted reasoning-centric fine-tuning, low-parameter LLMs can deliver accurate WSD while substantially reducing computational and energy demands.
Bridging Lexical Ambiguity and Vision: A Mini Review on Visual Word Sense Disambiguation
Feb 01, 2026This paper offers a mini review of Visual Word Sense Disambiguation (VWSD), which is a multimodal extension of traditional Word Sense Disambiguation (WSD). VWSD helps tackle lexical ambiguity in vision-language tasks. While conventional WSD depends only on text and lexical resources, VWSD uses visual cues to find the right meaning of ambiguous words with minimal text input. The review looks at developments from early multimodal fusion methods to new frameworks that use contrastive models like CLIP, diffusion-based text-to-image generation, and large language model (LLM) support. Studies from 2016 to 2025 are examined to show the growth of VWSD through feature-based, graph-based, and contrastive embedding techniques. It focuses on prompt engineering, fine-tuning, and adapting to multiple languages. Quantitative results show that CLIP-based fine-tuned models and LLM-enhanced VWSD systems consistently perform better than zero-shot baselines, achieving gains of up to 6-8\% in Mean Reciprocal Rank (MRR). However, challenges still exist, such as limitations in context, model bias toward common meanings, a lack of multilingual datasets, and the need for better evaluation frameworks. The analysis highlights the growing overlap of CLIP alignment, diffusion generation, and LLM reasoning as the future path for strong, context-aware, and multilingual disambiguation systems.
Can Small Language Models Handle Context-Summarized Multi-Turn Customer-Service QA? A Synthetic Data-Driven Comparative Evaluation
Jan 31, 2026Customer-service question answering (QA) systems increasingly rely on conversational language understanding. While Large Language Models (LLMs) achieve strong performance, their high computational cost and deployment constraints limit practical use in resource-constrained environments. Small Language Models (SLMs) provide a more efficient alternative, yet their effectiveness for multi-turn customer-service QA remains underexplored, particularly in scenarios requiring dialogue continuity and contextual understanding. This study investigates instruction-tuned SLMs for context-summarized multi-turn customer-service QA, using a history summarization strategy to preserve essential conversational state. We also introduce a conversation stage-based qualitative analysis to evaluate model behavior across different phases of customer-service interactions. Nine instruction-tuned low-parameterized SLMs are evaluated against three commercial LLMs using lexical and semantic similarity metrics alongside qualitative assessments, including human evaluation and LLM-as-a-judge methods. Results show notable variation across SLMs, with some models demonstrating near-LLM performance, while others struggle to maintain dialogue continuity and contextual alignment. These findings highlight both the potential and current limitations of low-parameterized language models for real-world customer-service QA systems.
A Low-Resource Speech-Driven NLP Pipeline for Sinhala Dyslexia Assistance
Oct 06, 2025Dyslexia in adults remains an under-researched and under-served area, particularly in non-English-speaking contexts, despite its significant impact on personal and professional lives. This work addresses that gap by focusing on Sinhala, a low-resource language with limited tools for linguistic accessibility. We present an assistive system explicitly designed for Sinhala-speaking adults with dyslexia. The system integrates Whisper for speech-to-text conversion, SinBERT, an open-sourced fine-tuned BERT model trained for Sinhala to identify common dyslexic errors, and a combined mT5 and Mistral-based model to generate corrected text. Finally, the output is converted back to speech using gTTS, creating a complete multimodal feedback loop. Despite the challenges posed by limited Sinhala-language datasets, the system achieves 0.66 transcription accuracy and 0.7 correction accuracy with 0.65 overall system accuracy. These results demonstrate both the feasibility and effectiveness of the approach. Ultimately, this work highlights the importance of inclusive Natural Language Processing (NLP) technologies in underrepresented languages and showcases a practical
A Systematic Decade Review of Trip Route Planning with Travel Time Estimation based on User Preferences and Behavior
Mar 30, 2025This paper systematically explores the advancements in adaptive trip route planning and travel time estimation (TTE) through Artificial Intelligence (AI). With the increasing complexity of urban transportation systems, traditional navigation methods often struggle to accommodate dynamic user preferences, real-time traffic conditions, and scalability requirements. This study explores the contributions of established AI techniques, including Machine Learning (ML), Reinforcement Learning (RL), and Graph Neural Networks (GNNs), alongside emerging methodologies like Meta-Learning, Explainable AI (XAI), Generative AI, and Federated Learning. In addition to highlighting these innovations, the paper identifies critical challenges such as ethical concerns, computational scalability, and effective data integration, which must be addressed to advance the field. The paper concludes with recommendations for leveraging AI to build efficient, transparent, and sustainable navigation systems.
IndoNLP 2025: Shared Task on Real-Time Reverse Transliteration for Romanized Indo-Aryan languages
Jan 15, 2025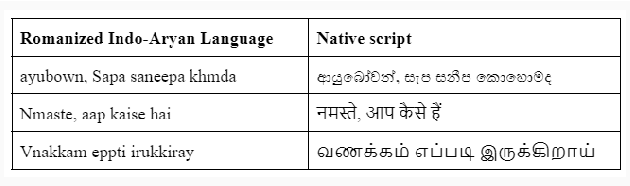



The paper overviews the shared task on Real-Time Reverse Transliteration for Romanized Indo-Aryan languages. It focuses on the reverse transliteration of low-resourced languages in the Indo-Aryan family to their native scripts. Typing Romanized Indo-Aryan languages using ad-hoc transliterals and achieving accurate native scripts are complex and often inaccurate processes with the current keyboard systems. This task aims to introduce and evaluate a real-time reverse transliterator that converts Romanized Indo-Aryan languages to their native scripts, improving the typing experience for users. Out of 11 registered teams, four teams participated in the final evaluation phase with transliteration models for Sinhala, Hindi and Malayalam. These proposed solutions not only solve the issue of ad-hoc transliteration but also empower low-resource language usability in the digital arena.
EmoScan: Automatic Screening of Depression Symptoms in Romanized Sinhala Tweets
Mar 28, 2024This work explores the utilization of Romanized Sinhala social media data to identify individuals at risk of depression. A machine learning-based framework is presented for the automatic screening of depression symptoms by analyzing language patterns, sentiment, and behavioural cues within a comprehensive dataset of social media posts. The research has been carried out to compare the suitability of Neural Networks over the classical machine learning techniques. The proposed Neural Network with an attention layer which is capable of handling long sequence data, attains a remarkable accuracy of 93.25% in detecting depression symptoms, surpassing current state-of-the-art methods. These findings underscore the efficacy of this approach in pinpointing individuals in need of proactive interventions and support. Mental health professionals, policymakers, and social media companies can gain valuable insights through the proposed model. Leveraging natural language processing techniques and machine learning algorithms, this work offers a promising pathway for mental health screening in the digital era. By harnessing the potential of social media data, the framework introduces a proactive method for recognizing and assisting individuals at risk of depression. In conclusion, this research contributes to the advancement of proactive interventions and support systems for mental health, thereby influencing both research and practical applications in the field.
A Survey on Lexical Ambiguity Detection and Word Sense Disambiguation
Mar 24, 2024This paper explores techniques that focus on understanding and resolving ambiguity in language within the field of natural language processing (NLP), highlighting the complexity of linguistic phenomena such as polysemy and homonymy and their implications for computational models. Focusing extensively on Word Sense Disambiguation (WSD), it outlines diverse approaches ranging from deep learning techniques to leveraging lexical resources and knowledge graphs like WordNet. The paper introduces cutting-edge methodologies like word sense extension (WSE) and neuromyotonic approaches, enhancing disambiguation accuracy by predicting new word senses. It examines specific applications in biomedical disambiguation and language specific optimisation and discusses the significance of cognitive metaphors in discourse analysis. The research identifies persistent challenges in the field, such as the scarcity of sense annotated corpora and the complexity of informal clinical texts. It concludes by suggesting future directions, including using large language models, visual WSD, and multilingual WSD systems, emphasising the ongoing evolution in addressing lexical complexities in NLP. This thinking perspective highlights the advancement in this field to enable computers to understand language more accurately.