 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge-Data Fusion Based Source-Free Semi-Supervised Domain Adaptation for Seizure Subtype Classification
Nov 29, 2024Electroencephalogram (EEG)-based seizure subtype classification enhances clinical diagnosis efficiency. Source-free semi-supervised domain adaptation (SF-SSDA), which transfers a pre-trained model to a new dataset with no source data and limited labeled target data, can be used for privacy-preserving seizure subtype classification. This paper considers two challenges in SF-SSDA for EEG-based seizure subtype classification: 1) How to effectively fuse both raw EEG data and expert knowledge in classifier design? 2) How to align the source and target domain distributions for SF-SSDA? We propose a Knowledge-Data Fusion based SF-SSDA approach, KDF-MutualSHOT, for EEG-based seizure subtype classification. In source model training, KDF uses Jensen-Shannon Divergence to facilitate mutual learning between a feature-driven Decision Tree-based model and a data-driven Transformer-based model. To adapt KDF to a new target dataset, an SF-SSDA algorithm, MutualSHOT, is developed, which features a consistency-based pseudo-label selection strategy. Experiments on the public TUSZ and CHSZ datasets demonstrated that KDF-MutualSHOT outperformed other supervised and source-free domain adaptation approaches in cross-subject seizure subtype classification.
Transfer Learning for Brain-Computer Interfaces: A Complete Pipeline
Jul 03, 2020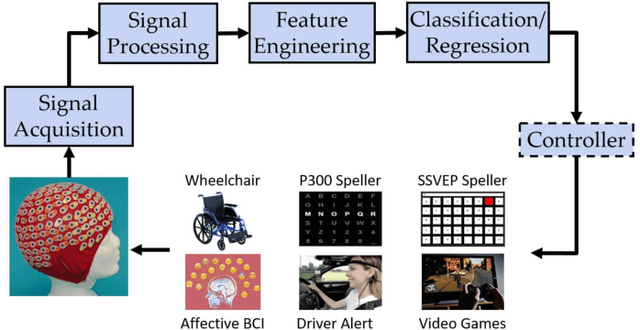
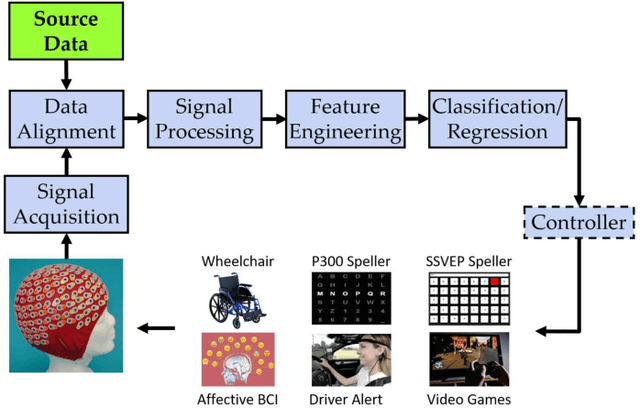
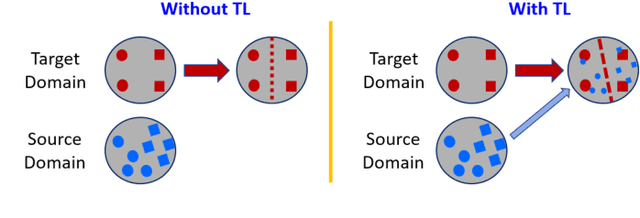
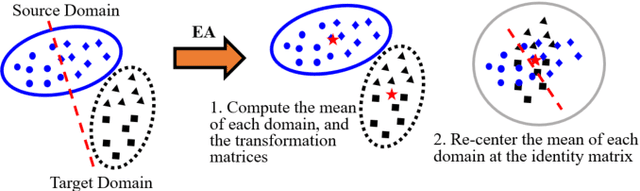
Transfer learning (TL) has been widely used in electroencephalogram (EEG) based brain-computer interfaces (BCIs) to reduce the calibration effort for a new subject, and demonstrated promising performance. After EEG signal acquisition, a closed-loop EEG-based BCI system also includes signal processing, feature engineering, and classification/regression blocks before sending out the control signal, whereas previous approaches only considered TL in one or two such components. This paper proposes that TL could be considered in all three components (signal processing, feature engineering, and classification/regression). Furthermore, it is also very important to specifically add a data alignment component before signal processing to make the data from different subjects more consistent, and hence to facilitate subsequential TL. Offline calibration experiments on two MI datasets verified our proposal. Especially, integrating data alignment and sophisticated TL approaches can significantly improve the classification performance, and hence greatly reduce the calibration effort.