 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClaim2Vec: Embedding Fact-Check Claims for Multilingual Similarity and Clustering
Apr 10, 2026Recurrent claims present a major challenge for automated fact-checking systems designed to combat misinformation, especially in multilingual settings. While tasks such as claim matching and fact-checked claim retrieval aim to address this problem by linking claim pairs, the broader challenge of effectively representing groups of similar claims that can be resolved with the same fact-check via claim clustering remains relatively underexplored. To address this gap, we introduce Claim2Vec, the first multilingual embedding model optimized to represent fact-check claims as vectors in an improved semantic embedding space. We fine-tune a multilingual encoder using contrastive learning with similar multilingual claim pairs. Experiments on the claim clustering task using three datasets, 14 multilingual embedding models, and 7 clustering algorithms demonstrate that Claim2Vec significantly improves clustering performance. Specifically, it enhances both cluster label alignment and the geometric structure of the embedding space across different cluster configurations. Our multilingual analysis shows that clusters containing multiple languages benefit from fine-tuning, demonstrating cross-lingual knowledge transfer.
ContextClaim: A Context-Driven Paradigm for Verifiable Claim Detection
Mar 31, 2026Verifiable claim detection asks whether a claim expresses a factual statement that can, in principle, be assessed against external evidence. As an early filtering stage in automated fact-checking, it plays an important role in reducing the burden on downstream verification components. However, existing approaches to claim detection, whether based on check-worthiness or verifiability, rely solely on the claim text itself. This is a notable limitation for verifiable claim detection in particular, where determining whether a claim is checkable may benefit from knowing what entities and events it refers to and whether relevant information exists to support verification. Inspired by the established role of evidence retrieval in later-stage claim verification, we propose Context-Driven Claim Detection (ContextClaim), a paradigm that advances retrieval to the detection stage. ContextClaim extracts entity mentions from the input claim, retrieves relevant information from Wikipedia as a structured knowledge source, and employs large language models to produce concise contextual summaries for downstream classification. We evaluate ContextClaim on two datasets covering different topics and text genres, the CheckThat! 2022 COVID-19 Twitter dataset and the PoliClaim political debate dataset, across encoder-only and decoder-only models under fine-tuning, zero-shot, and few-shot settings. Results show that context augmentation can improve verifiable claim detection, although its effectiveness varies across domains, model architectures, and learning settings. Through component analysis, human evaluation, and error analysis, we further examine when and why the retrieved context contributes to more reliable verifiability judgments.
MultiCaption: Detecting disinformation using multilingual visual claims
Jan 16, 2026Online disinformation poses an escalating threat to society, driven increasingly by the rapid spread of misleading content across both multimedia and multilingual platforms. While automated fact-checking methods have advanced in recent years, their effectiveness remains constrained by the scarcity of datasets that reflect these real-world complexities. To address this gap, we first present MultiCaption, a new dataset specifically designed for detecting contradictions in visual claims. Pairs of claims referring to the same image or video were labeled through multiple strategies to determine whether they contradict each other. The resulting dataset comprises 11,088 visual claims in 64 languages, offering a unique resource for building and evaluating misinformation-detection systems in truly multimodal and multilingual environments. We then provide comprehensive experiments using transformer-based architectures, natural language inference models, and large language models, establishing strong baselines for future research. The results show that MultiCaption is more challenging than standard NLI tasks, requiring task-specific finetuning for strong performance. Moreover, the gains from multilingual training and testing highlight the dataset's potential for building effective multilingual fact-checking pipelines without relying on machine translation.
MultiClaimNet: A Massively Multilingual Dataset of Fact-Checked Claim Clusters
Mar 28, 2025In the context of fact-checking, claims are often repeated across various platforms and in different languages, which can benefit from a process that reduces this redundancy. While retrieving previously fact-checked claims has been investigated as a solution, the growing number of unverified claims and expanding size of fact-checked databases calls for alternative, more efficient solutions. A promising solution is to group claims that discuss the same underlying facts into clusters to improve claim retrieval and validation. However, research on claim clustering is hindered by the lack of suitable datasets. To bridge this gap, we introduce \textit{MultiClaimNet}, a collection of three multilingual claim cluster datasets containing claims in 86 languages across diverse topics. Claim clusters are formed automatically from claim-matching pairs with limited manual intervention. We leverage two existing claim-matching datasets to form the smaller datasets within \textit{MultiClaimNet}. To build the larger dataset, we propose and validate an approach involving retrieval of approximate nearest neighbors to form candidate claim pairs and an automated annotation of claim similarity using large language models. This larger dataset contains 85.3K fact-checked claims written in 78 languages. We further conduct extensive experiments using various clustering techniques and sentence embedding models to establish baseline performance. Our datasets and findings provide a strong foundation for scalable claim clustering, contributing to efficient fact-checking pipelines.
Entity-aware Cross-lingual Claim Detection for Automated Fact-checking
Mar 20, 2025



Identifying claims requiring verification is a critical task in automated fact-checking, especially given the proliferation of misinformation on social media platforms. Despite significant progress in the task, there remain open challenges such as dealing with multilingual and multimodal data prevalent in online discourse. Addressing the multilingual challenge, recent efforts have focused on fine-tuning pre-trained multilingual language models. While these models can handle multiple languages, their ability to effectively transfer cross-lingual knowledge for detecting claims spreading on social media remains under-explored. In this paper, we introduce EX-Claim, an entity-aware cross-lingual claim detection model that generalizes well to handle claims written in any language. The model leverages entity information derived from named entity recognition and entity linking techniques to improve the language-level performance of both seen and unseen languages during training. Extensive experiments conducted on three datasets from different social media platforms demonstrate that our proposed model significantly outperforms the baselines, across 27 languages, and achieves the highest rate of knowledge transfer, even with limited training data.
FactFinders at CheckThat! 2024: Refining Check-worthy Statement Detection with LLMs through Data Pruning
Jun 26, 2024The rapid dissemination of information through social media and the Internet has posed a significant challenge for fact-checking, among others in identifying check-worthy claims that fact-checkers should pay attention to, i.e. filtering claims needing fact-checking from a large pool of sentences. This challenge has stressed the need to focus on determining the priority of claims, specifically which claims are worth to be fact-checked. Despite advancements in this area in recent years, the application of large language models (LLMs), such as GPT, has only recently drawn attention in studies. However, many open-source LLMs remain underexplored. Therefore, this study investigates the application of eight prominent open-source LLMs with fine-tuning and prompt engineering to identify check-worthy statements from political transcriptions. Further, we propose a two-step data pruning approach to automatically identify high-quality training data instances for effective learning. The efficiency of our approach is demonstrated through evaluations on the English language dataset as part of the check-worthiness estimation task of CheckThat! 2024. Further, the experiments conducted with data pruning demonstrate that competitive performance can be achieved with only about 44\% of the training data. Our team ranked first in the check-worthiness estimation task in the English language.
AI Insights: A Case Study on Utilizing ChatGPT Intelligence for Research Paper Analysis
Mar 05, 2024



This paper discusses the effectiveness of leveraging Chatbot: Generative Pre-trained Transformer (ChatGPT) versions 3.5 and 4 for analyzing research papers for effective writing of scientific literature surveys. The study selected the \textit{Application of Artificial Intelligence in Breast Cancer Treatment} as the research topic. Research papers related to this topic were collected from three major publication databases Google Scholar, Pubmed, and Scopus. ChatGPT models were used to identify the category, scope, and relevant information from the research papers for automatic identification of relevant papers related to Breast Cancer Treatment (BCT), organization of papers according to scope, and identification of key information for survey paper writing. Evaluations performed using ground truth data annotated using subject experts reveal, that GPT-4 achieves 77.3\% accuracy in identifying the research paper categories and 50\% of the papers were correctly identified by GPT-4 for their scopes. Further, the results demonstrate that GPT-4 can generate reasons for its decisions with an average of 27\% new words, and 67\% of the reasons given by the model were completely agreeable to the subject experts.
Crisis talk: analysis of the public debate around the energy crisis and cost of living
Feb 28, 2024A prominent media topic in the UK in the early 2020s is the energy crisis affecting the UK and most of Europe. It brings into a single public debate issues of energy dependency and sustainability, fair distribution of economic burdens and cost of living, as well as climate change, risk, and sustainability. In this paper, we investigate the public discourse around the energy crisis and cost of living to identify how these pivotal and contradictory issues are reconciled in this debate and to identify which social actors are involved and the role they play. We analyse a document corpus retrieved from UK newspapers from January 2014 to March 2023. We apply a variety of natural language processing and data visualisation techniques to identify key topics, novel trends, critical social actors, and the role they play in the debate, along with the sentiment associated with those actors and topics. We combine automated techniques with manual discourse analysis to explore and validate the insights revealed in this study. The findings verify the utility of these techniques by providing a flexible and scalable pipeline for discourse analysis and providing critical insights for cost of living - energy crisis nexus research.
Claim Detection for Automated Fact-checking: A Survey on Monolingual, Multilingual and Cross-Lingual Research
Jan 23, 2024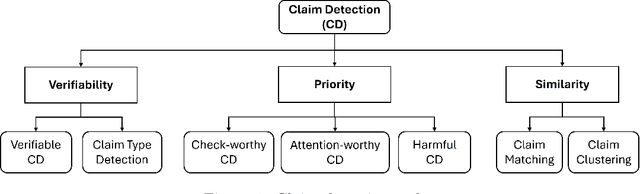
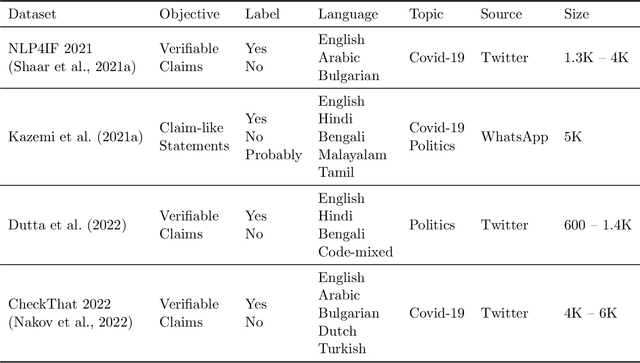
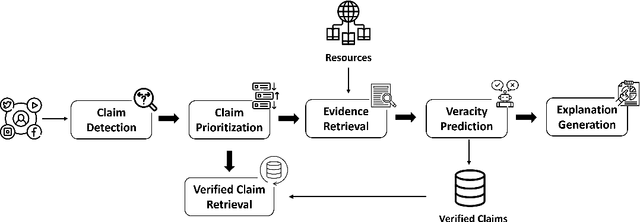

Automated fact-checking has drawn considerable attention over the past few decades due to the increase in the diffusion of misinformation on online platforms. This is often carried out as a sequence of tasks comprising (i) the detection of sentences circulating in online platforms which constitute claims needing verification, followed by (ii) the verification process of those claims. This survey focuses on the former, by discussing existing efforts towards detecting claims needing fact-checking, with a particular focus on multilingual data and methods. This is a challenging and fertile direction where existing methods are yet far from matching human performance due to the profoundly challenging nature of the issue. Especially, the dissemination of information across multiple social platforms, articulated in multiple languages and modalities demands more generalized solutions for combating misinformation. Focusing on multilingual misinformation, we present a comprehensive survey of existing multilingual claim detection research. We present state-of-the-art multilingual claim detection research categorized into three key factors of the problem, verifiability, priority, and similarity. Further, we present a detailed overview of the existing multilingual datasets along with the challenges and suggest possible future advancements.
Synergizing Machine Learning & Symbolic Methods: A Survey on Hybrid Approaches to Natural Language Processing
Jan 22, 2024



The advancement of machine learning and symbolic approaches have underscored their strengths and weaknesses in Natural Language Processing (NLP). While machine learning approaches are powerful in identifying patterns in data, they often fall short in learning commonsense and the factual knowledge required for the NLP tasks. Meanwhile, the symbolic methods excel in representing knowledge-rich data. However, they struggle to adapt dynamic data and generalize the knowledge. Bridging these two paradigms through hybrid approaches enables the alleviation of weaknesses in both while preserving their strengths. Recent studies extol the virtues of this union, showcasing promising results in a wide range of NLP tasks. In this paper, we present an overview of hybrid approaches used for NLP. Specifically, we delve into the state-of-the-art hybrid approaches used for a broad spectrum of NLP tasks requiring natural language understanding, generation, and reasoning. Furthermore, we discuss the existing resources available for hybrid approaches for NLP along with the challenges, offering a roadmap for future directions.