 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient estimation of weighted cumulative treatment effects by double/debiased machine learning
May 03, 2023In empirical studies with time-to-event outcomes, investigators often leverage observational data to conduct causal inference on the effect of exposure when randomized controlled trial data is unavailable. Model misspecification and lack of overlap are common issues in observational studies, and they often lead to inconsistent and inefficient estimators of the average treatment effect. Estimators targeting overlap weighted effects have been proposed to address the challenge of poor overlap, and methods enabling flexible machine learning for nuisance models address model misspecification. However, the approaches that allow machine learning for nuisance models have not been extended to the setting of weighted average treatment effects for time-to-event outcomes when there is poor overlap. In this work, we propose a class of one-step cross-fitted double/debiased machine learning estimators for the weighted cumulative causal effect as a function of restriction time. We prove that the proposed estimators are consistent, asymptotically linear, and reach semiparametric efficiency bounds under regularity conditions. Our simulations show that the proposed estimators using nonparametric machine learning nuisance models perform as well as established methods that require correctly-specified parametric nuisance models, illustrating that our estimators mitigate the need for oracle parametric nuisance models. We apply the proposed methods to real-world observational data from a UK primary care database to compare the effects of anti-diabetic drugs on cancer clinical outcomes.
The Univariate Flagging Algorithm (UFA): a Fully-Automated Approach for Identifying Optimal Thresholds in Data
Apr 12, 2016
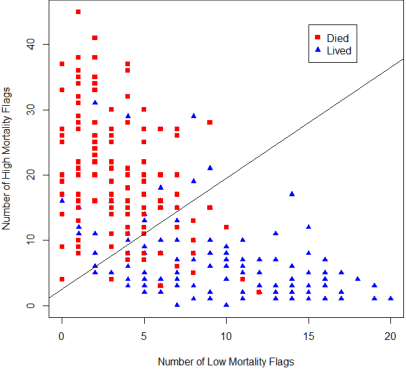
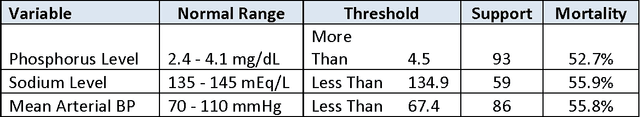
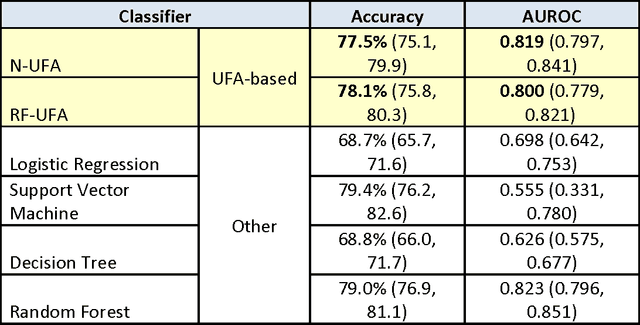
In many data classification problems, there is no linear relationship between an explanatory and the dependent variables. Instead, there may be ranges of the input variable for which the observed outcome is signficantly more or less likely. This paper describes an algorithm for automatic detection of such thresholds, called the Univariate Flagging Algorithm (UFA). The algorithm searches for a separation that optimizes the difference between separated areas while providing the maximum support. We evaluate its performance using three examples and demonstrate that thresholds identified by the algorithm align well with visual inspection and subject matter expertise. We also introduce two classification approaches that use UFA and show that the performance attained on unseen test data is equal to or better than that of more traditional classifiers. We demonstrate that the proposed algorithm is robust against missing data and noise, is scalable, and is easy to interpret and visualize. It is also well suited for problems where incidence of the target is low.