 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Univariate Flagging Algorithm (UFA): a Fully-Automated Approach for Identifying Optimal Thresholds in Data
Apr 12, 2016
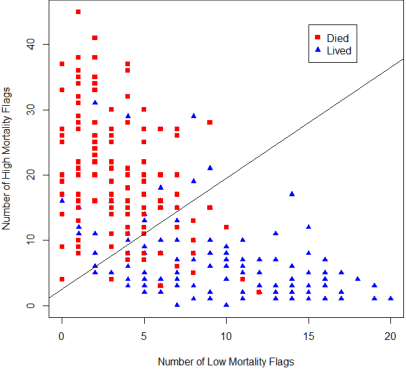
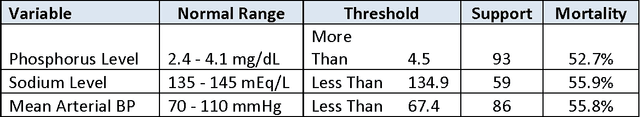
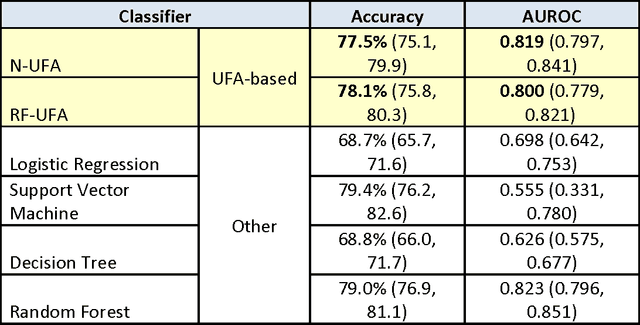
In many data classification problems, there is no linear relationship between an explanatory and the dependent variables. Instead, there may be ranges of the input variable for which the observed outcome is signficantly more or less likely. This paper describes an algorithm for automatic detection of such thresholds, called the Univariate Flagging Algorithm (UFA). The algorithm searches for a separation that optimizes the difference between separated areas while providing the maximum support. We evaluate its performance using three examples and demonstrate that thresholds identified by the algorithm align well with visual inspection and subject matter expertise. We also introduce two classification approaches that use UFA and show that the performance attained on unseen test data is equal to or better than that of more traditional classifiers. We demonstrate that the proposed algorithm is robust against missing data and noise, is scalable, and is easy to interpret and visualize. It is also well suited for problems where incidence of the target is low.