 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArtificial Intelligence and Natural Language Processing and Understanding in Space: Four ESA Case Studies
Oct 07, 2022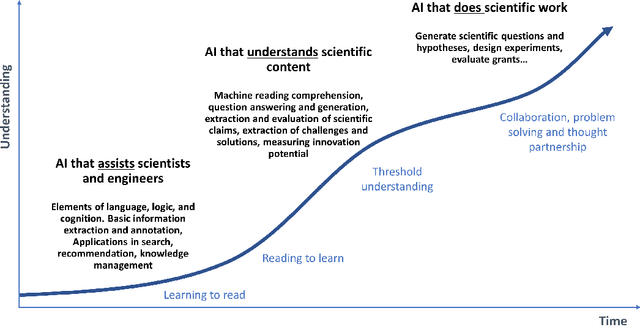
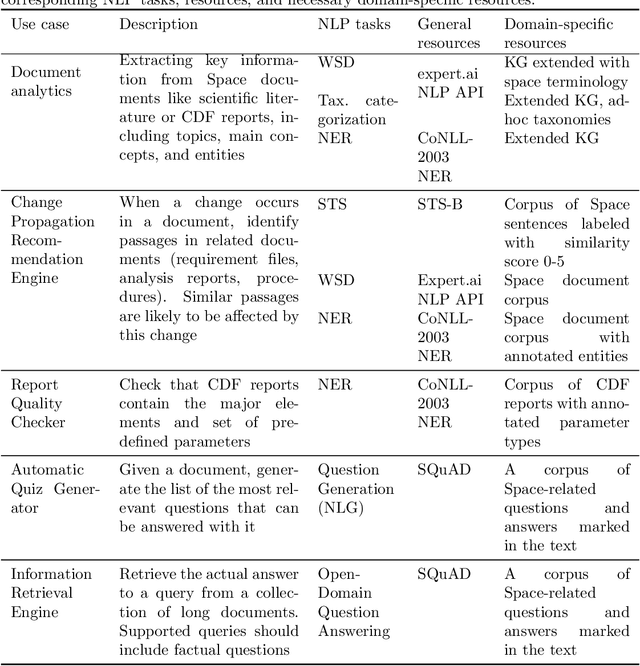
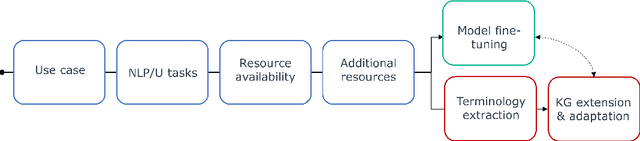
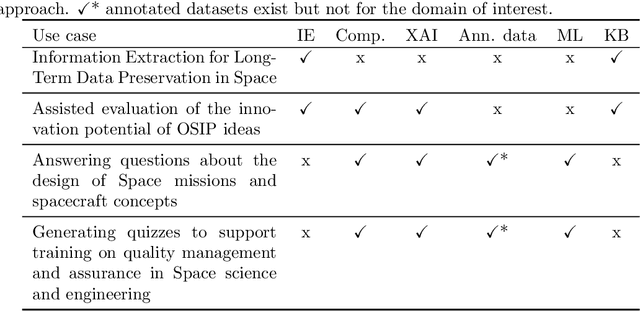
The European Space Agency is well known as a powerful force for scientific discovery in numerous areas related to Space. The amount and depth of the knowledge produced throughout the different missions carried out by ESA and their contribution to scientific progress is enormous, involving large collections of documents like scientific publications, feasibility studies, technical reports, and quality management procedures, among many others. Through initiatives like the Open Space Innovation Platform, ESA also acts as a hub for new ideas coming from the wider community across different challenges, contributing to a virtuous circle of scientific discovery and innovation. Handling such wealth of information, of which large part is unstructured text, is a colossal task that goes beyond human capabilities, hence requiring automation. In this paper, we present a methodological framework based on artificial intelligence and natural language processing and understanding to automatically extract information from Space documents, generating value from it, and illustrate such framework through several case studies implemented across different functional areas of ESA, including Mission Design, Quality Assurance, Long-Term Data Preservation, and the Open Space Innovation Platform. In doing so, we demonstrate the value of these technologies in several tasks ranging from effortlessly searching and recommending Space information to automatically determining how innovative an idea can be, answering questions about Space, and generating quizzes regarding quality procedures. Each of these accomplishments represents a step forward in the application of increasingly intelligent AI systems in Space, from structuring and facilitating information access to intelligent systems capable to understand and reason with such information.
Enabling FAIR Research in Earth Science through Research Objects
Sep 27, 2018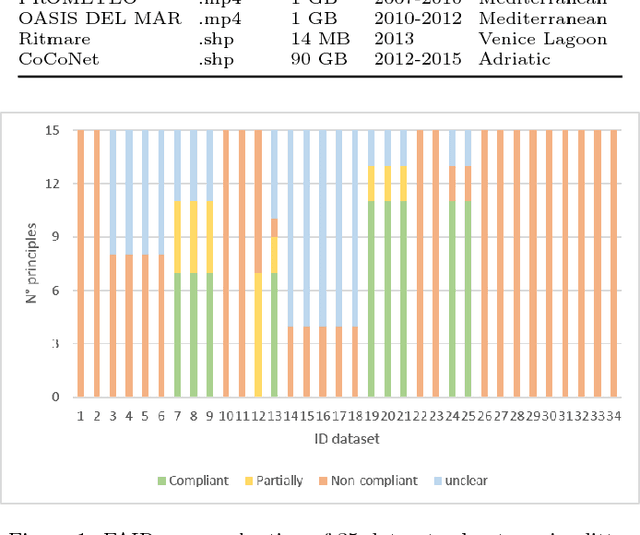
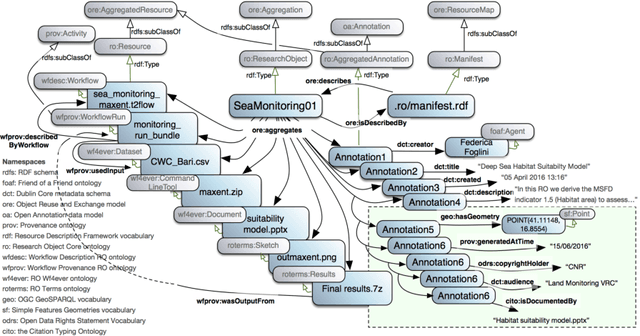
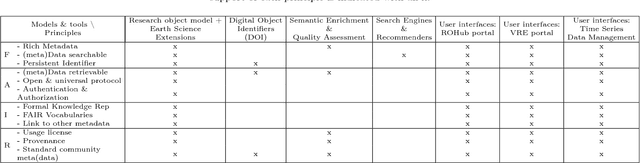
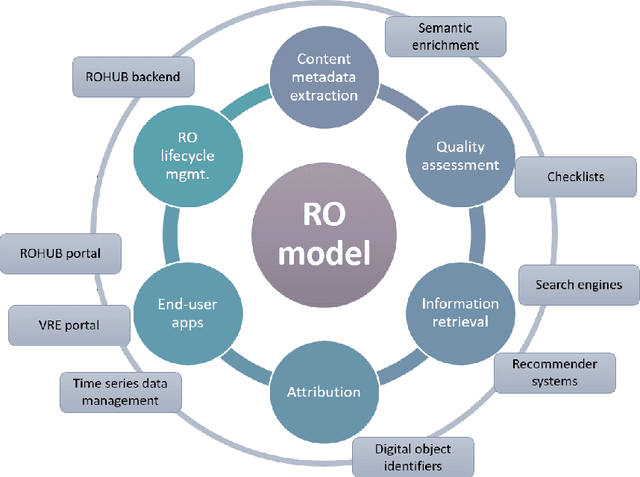
Data-intensive science communities are progressively adopting FAIR practices that enhance the visibility of scientific breakthroughs and enable reuse. At the core of this movement, research objects contain and describe scientific information and resources in a way compliant with the FAIR principles and sustain the development of key infrastructure and tools. This paper provides an account of the challenges, experiences and solutions involved in the adoption of FAIR around research objects over several Earth Science disciplines. During this journey, our work has been comprehensive, with outcomes including: an extended research object model adapted to the needs of earth scientists; the provisioning of digital object identifiers (DOI) to enable persistent identification and to give due credit to authors; the generation of content-based, semantically rich, research object metadata through natural language processing, enhancing visibility and reuse through recommendation systems and third-party search engines; and various types of checklists that provide a compact representation of research object quality as a key enabler of scientific reuse. All these results have been integrated in ROHub, a platform that provides research object management functionality to a wealth of applications and interfaces across different scientific communities. To monitor and quantify the community uptake of research objects, we have defined indicators and obtained measures via ROHub that are also discussed herein.