 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMMS: Multi-Modal Multi-Surface Interactive Segmentation
Sep 16, 2025In this paper, we present a method to interactively create segmentation masks on the basis of user clicks. We pay particular attention to the segmentation of multiple surfaces that are simultaneously present in the same image. Since these surfaces may be heavily entangled and adjacent, we also present a novel extended evaluation metric that accounts for the challenges of this scenario. Additionally, the presented method is able to use multi-modal inputs to facilitate the segmentation task. At the center of this method is a network architecture which takes as input an RGB image, a number of non-RGB modalities, an erroneous mask, and encoded clicks. Based on this input, the network predicts an improved segmentation mask. We design our architecture such that it adheres to two conditions: (1) The RGB backbone is only available as a black-box. (2) To reduce the response time, we want our model to integrate the interaction-specific information after the image feature extraction and the multi-modal fusion. We refer to the overall task as Multi-Modal Multi-Surface interactive segmentation (MMMS). We are able to show the effectiveness of our multi-modal fusion strategy. Using additional modalities, our system reduces the NoC@90 by up to 1.28 clicks per surface on average on DeLiVER and up to 1.19 on MFNet. On top of this, we are able to show that our RGB-only baseline achieves competitive, and in some cases even superior performance when tested in a classical, single-mask interactive segmentation scenario.
CoPa-SG: Dense Scene Graphs with Parametric and Proto-Relations
Jun 26, 20252D scene graphs provide a structural and explainable framework for scene understanding. However, current work still struggles with the lack of accurate scene graph data. To overcome this data bottleneck, we present CoPa-SG, a synthetic scene graph dataset with highly precise ground truth and exhaustive relation annotations between all objects. Moreover, we introduce parametric and proto-relations, two new fundamental concepts for scene graphs. The former provides a much more fine-grained representation than its traditional counterpart by enriching relations with additional parameters such as angles or distances. The latter encodes hypothetical relations in a scene graph and describes how relations would form if new objects are placed in the scene. Using CoPa-SG, we compare the performance of various scene graph generation models. We demonstrate how our new relation types can be integrated in downstream applications to enhance planning and reasoning capabilities.
Towards Ball Spin and Trajectory Analysis in Table Tennis Broadcast Videos via Physically Grounded Synthetic-to-Real Transfer
Apr 28, 2025Analyzing a player's technique in table tennis requires knowledge of the ball's 3D trajectory and spin. While, the spin is not directly observable in standard broadcasting videos, we show that it can be inferred from the ball's trajectory in the video. We present a novel method to infer the initial spin and 3D trajectory from the corresponding 2D trajectory in a video. Without ground truth labels for broadcast videos, we train a neural network solely on synthetic data. Due to the choice of our input data representation, physically correct synthetic training data, and using targeted augmentations, the network naturally generalizes to real data. Notably, these simple techniques are sufficient to achieve generalization. No real data at all is required for training. To the best of our knowledge, we are the first to present a method for spin and trajectory prediction in simple monocular broadcast videos, achieving an accuracy of 92.0% in spin classification and a 2D reprojection error of 0.19% of the image diagonal.
Efficient 2D to Full 3D Human Pose Uplifting including Joint Rotations
Apr 14, 2025
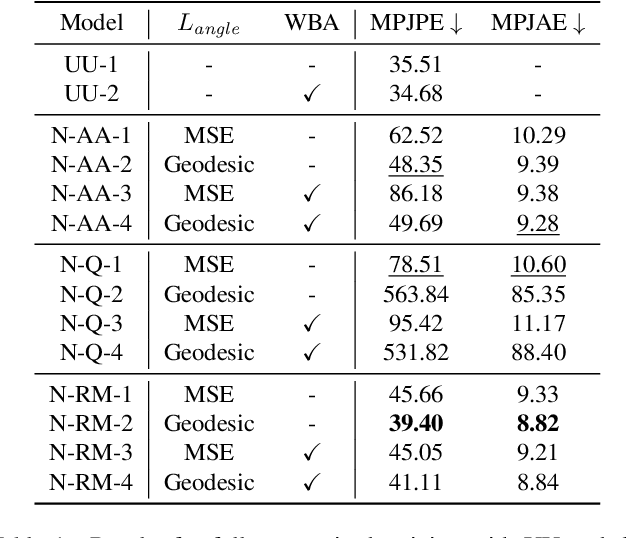
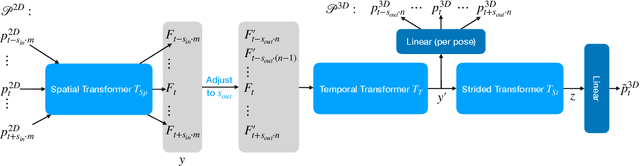
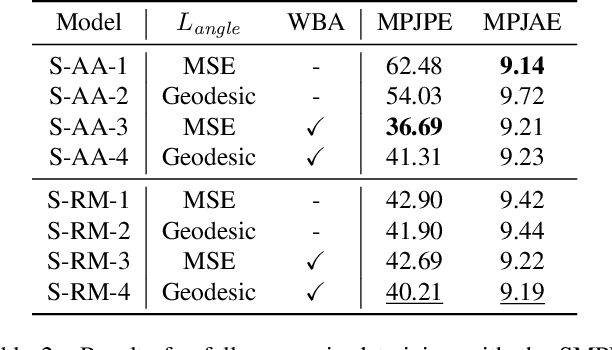
In sports analytics, accurately capturing both the 3D locations and rotations of body joints is essential for understanding an athlete's biomechanics. While Human Mesh Recovery (HMR) models can estimate joint rotations, they often exhibit lower accuracy in joint localization compared to 3D Human Pose Estimation (HPE) models. Recent work addressed this limitation by combining a 3D HPE model with inverse kinematics (IK) to estimate both joint locations and rotations. However, IK is computationally expensive. To overcome this, we propose a novel 2D-to-3D uplifting model that directly estimates 3D human poses, including joint rotations, in a single forward pass. We investigate multiple rotation representations, loss functions, and training strategies - both with and without access to ground truth rotations. Our models achieve state-of-the-art accuracy in rotation estimation, are 150 times faster than the IK-based approach, and surpass HMR models in joint localization precision.
SkipClick: Combining Quick Responses and Low-Level Features for Interactive Segmentation in Winter Sports Contexts
Jan 14, 2025In this paper, we present a novel architecture for interactive segmentation in winter sports contexts. The field of interactive segmentation deals with the prediction of high-quality segmentation masks by informing the network about the objects position with the help of user guidance. In our case the guidance consists of click prompts. For this task, we first present a baseline architecture which is specifically geared towards quickly responding after each click. Afterwards, we motivate and describe a number of architectural modifications which improve the performance when tasked with segmenting winter sports equipment on the WSESeg dataset. With regards to the average NoC@85 metric on the WSESeg classes, we outperform SAM and HQ-SAM by 2.336 and 7.946 clicks, respectively. When applied to the HQSeg-44k dataset, our system delivers state-of-the-art results with a NoC@90 of 6.00 and NoC@95 of 9.89. In addition to that, we test our model on a novel dataset containing masks for humans during skiing.
Harnessing Event Sensory Data for Error Pattern Prediction in Vehicles: A Language Model Approach
Dec 17, 2024



In this paper, we draw an analogy between processing natural languages and processing multivariate event streams from vehicles in order to predict $\textit{when}$ and $\textit{what}$ error pattern is most likely to occur in the future for a given car. Our approach leverages the temporal dynamics and contextual relationships of our event data from a fleet of cars. Event data is composed of discrete values of error codes as well as continuous values such as time and mileage. Modelled by two causal Transformers, we can anticipate vehicle failures and malfunctions before they happen. Thus, we introduce $\textit{CarFormer}$, a Transformer model trained via a new self-supervised learning strategy, and $\textit{EPredictor}$, an autoregressive Transformer decoder model capable of predicting $\textit{when}$ and $\textit{what}$ error pattern will most likely occur after some error code apparition. Despite the challenges of high cardinality of event types, their unbalanced frequency of appearance and limited labelled data, our experimental results demonstrate the excellent predictive ability of our novel model. Specifically, with sequences of $160$ error codes on average, our model is able with only half of the error codes to achieve $80\%$ F1 score for predicting $\textit{what}$ error pattern will occur and achieves an average absolute error of $58.4 \pm 13.2$h $\textit{when}$ forecasting the time of occurrence, thus enabling confident predictive maintenance and enhancing vehicle safety.
WSESeg: Introducing a Dataset for the Segmentation of Winter Sports Equipment with a Baseline for Interactive Segmentation
Jul 12, 2024



In this paper we introduce a new dataset containing instance segmentation masks for ten different categories of winter sports equipment, called WSESeg (Winter Sports Equipment Segmentation). Furthermore, we carry out interactive segmentation experiments on said dataset to explore possibilities for efficient further labeling. The SAM and HQ-SAM models are conceptualized as foundation models for performing user guided segmentation. In order to measure their claimed generalization capability we evaluate them on WSESeg. Since interactive segmentation offers the benefit of creating easily exploitable ground truth data during test-time, we are going to test various online adaptation methods for the purpose of exploring potentials for improvements without having to fine-tune the models explicitly. Our experiments show that our adaptation methods drastically reduce the Failure Rate (FR) and Number of Clicks (NoC) metrics, which generally leads faster to better interactive segmentation results.
Segformer++: Efficient Token-Merging Strategies for High-Resolution Semantic Segmentation
May 23, 2024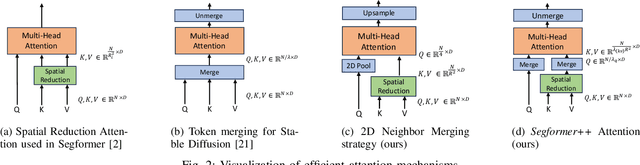

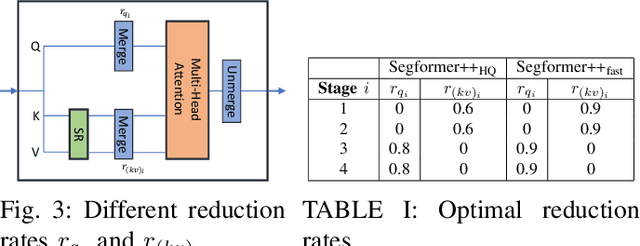
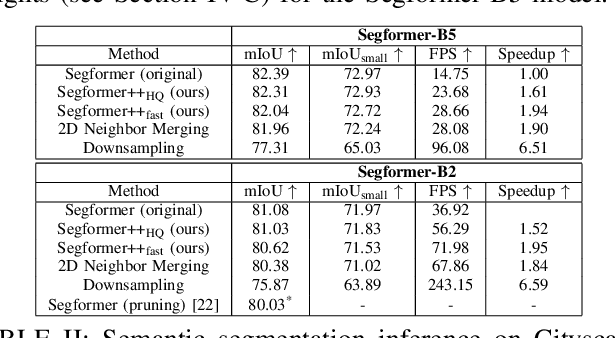
Utilizing transformer architectures for semantic segmentation of high-resolution images is hindered by the attention's quadratic computational complexity in the number of tokens. A solution to this challenge involves decreasing the number of tokens through token merging, which has exhibited remarkable enhancements in inference speed, training efficiency, and memory utilization for image classification tasks. In this paper, we explore various token merging strategies within the framework of the Segformer architecture and perform experiments on multiple semantic segmentation and human pose estimation datasets. Notably, without model re-training, we, for example, achieve an inference acceleration of 61% on the Cityscapes dataset while maintaining the mIoU performance. Consequently, this paper facilitates the deployment of transformer-based architectures on resource-constrained devices and in real-time applications.
A Review and Efficient Implementation of Scene Graph Generation Metrics
Apr 15, 2024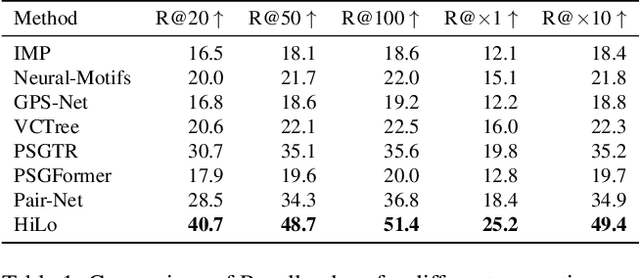
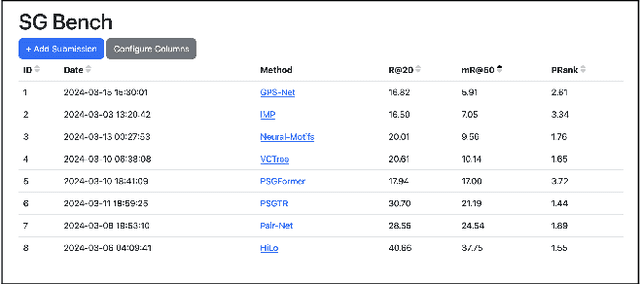
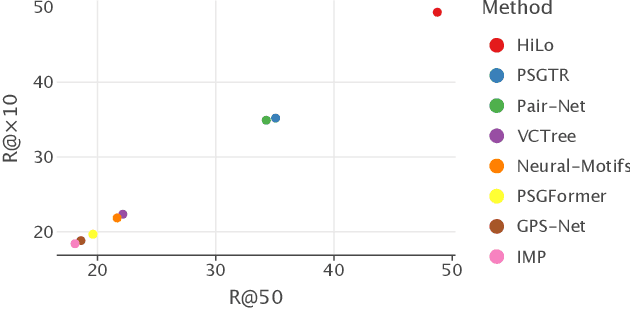
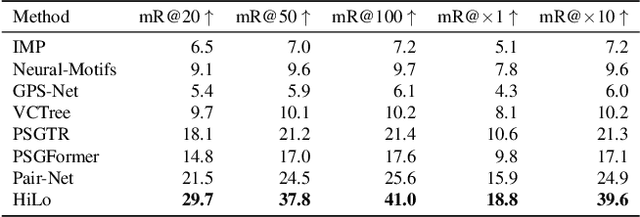
Scene graph generation has emerged as a prominent research field in computer vision, witnessing significant advancements in the recent years. However, despite these strides, precise and thorough definitions for the metrics used to evaluate scene graph generation models are lacking. In this paper, we address this gap in the literature by providing a review and precise definition of commonly used metrics in scene graph generation. Our comprehensive examination clarifies the underlying principles of these metrics and can serve as a reference or introduction to scene graph metrics. Furthermore, to facilitate the usage of these metrics, we introduce a standalone Python package called SGBench that efficiently implements all defined metrics, ensuring their accessibility to the research community. Additionally, we present a scene graph benchmarking web service, that enables researchers to compare scene graph generation methods and increase visibility of new methods in a central place. All of our code can be found at https://lorjul.github.io/sgbench/.
Adapting the Segment Anything Model During Usage in Novel Situations
Apr 12, 2024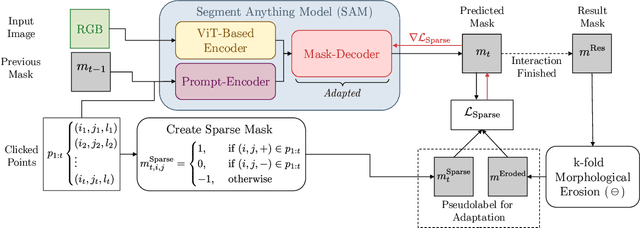
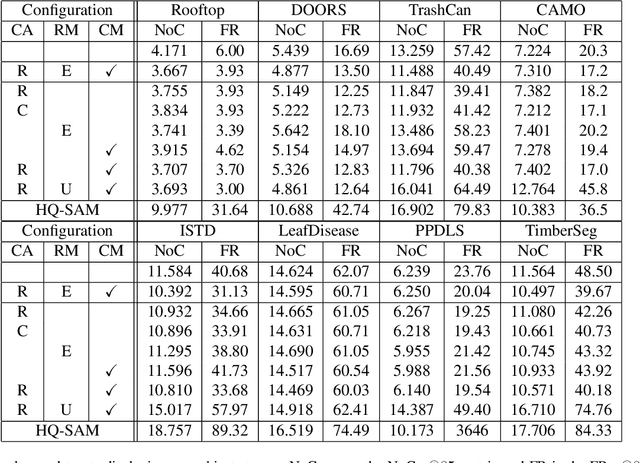
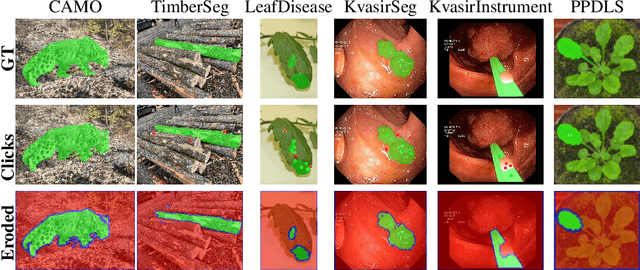
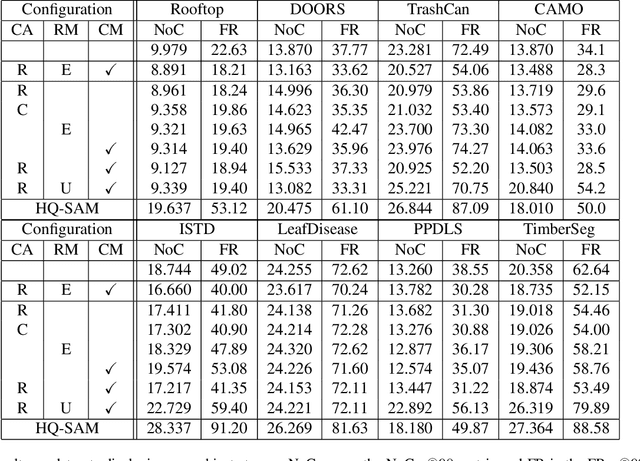
The interactive segmentation task consists in the creation of object segmentation masks based on user interactions. The most common way to guide a model towards producing a correct segmentation consists in clicks on the object and background. The recently published Segment Anything Model (SAM) supports a generalized version of the interactive segmentation problem and has been trained on an object segmentation dataset which contains 1.1B masks. Though being trained extensively and with the explicit purpose of serving as a foundation model, we show significant limitations of SAM when being applied for interactive segmentation on novel domains or object types. On the used datasets, SAM displays a failure rate $\text{FR}_{30}@90$ of up to $72.6 \%$. Since we still want such foundation models to be immediately applicable, we present a framework that can adapt SAM during immediate usage. For this we will leverage the user interactions and masks, which are constructed during the interactive segmentation process. We use this information to generate pseudo-labels, which we use to compute a loss function and optimize a part of the SAM model. The presented method causes a relative reduction of up to $48.1 \%$ in the $\text{FR}_{20}@85$ and $46.6 \%$ in the $\text{FR}_{30}@90$ metrics.