 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHomotopy Parametric Simplex Method for Sparse Learning
Nov 27, 2017



High dimensional sparse learning has imposed a great computational challenge to large scale data analysis. In this paper, we are interested in a broad class of sparse learning approaches formulated as linear programs parametrized by a {\em regularization factor}, and solve them by the parametric simplex method (PSM). Our parametric simplex method offers significant advantages over other competing methods: (1) PSM naturally obtains the complete solution path for all values of the regularization parameter; (2) PSM provides a high precision dual certificate stopping criterion; (3) PSM yields sparse solutions through very few iterations, and the solution sparsity significantly reduces the computational cost per iteration. Particularly, we demonstrate the superiority of PSM over various sparse learning approaches, including Dantzig selector for sparse linear regression, LAD-Lasso for sparse robust linear regression, CLIME for sparse precision matrix estimation, sparse differential network estimation, and sparse Linear Programming Discriminant (LPD) analysis. We then provide sufficient conditions under which PSM always outputs sparse solutions such that its computational performance can be significantly boosted. Thorough numerical experiments are provided to demonstrate the outstanding performance of the PSM method.
Optimization for Compressed Sensing: the Simplex Method and Kronecker Sparsification
Dec 16, 2013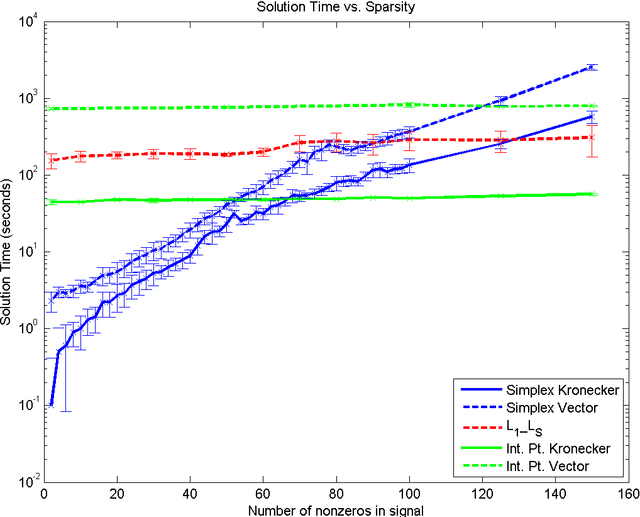
In this paper we present two new approaches to efficiently solve large-scale compressed sensing problems. These two ideas are independent of each other and can therefore be used either separately or together. We consider all possibilities. For the first approach, we note that the zero vector can be taken as the initial basic (infeasible) solution for the linear programming problem and therefore, if the true signal is very sparse, some variants of the simplex method can be expected to take only a small number of pivots to arrive at a solution. We implemented one such variant and demonstrate a dramatic improvement in computation time on very sparse signals. The second approach requires a redesigned sensing mechanism in which the vector signal is stacked into a matrix. This allows us to exploit the Kronecker compressed sensing (KCS) mechanism. We show that the Kronecker sensing requires stronger conditions for perfect recovery compared to the original vector problem. However, the Kronecker sensing, modeled correctly, is a much sparser linear optimization problem. Hence, algorithms that benefit from sparse problem representation, such as interior-point methods, can solve the Kronecker sensing problems much faster than the corresponding vector problem. In our numerical studies, we demonstrate a ten-fold improvement in the computation time.