 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeState-Denoised Recurrent Neural Networks
May 28, 2018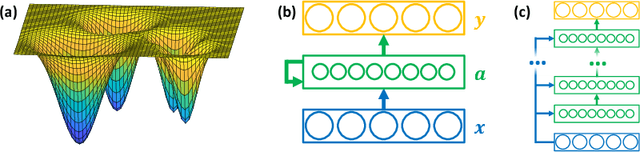
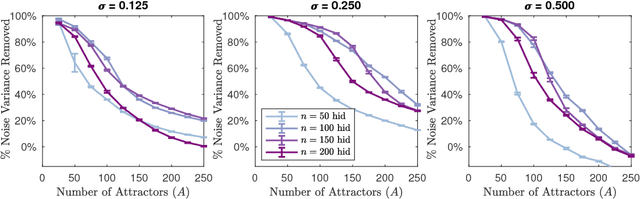
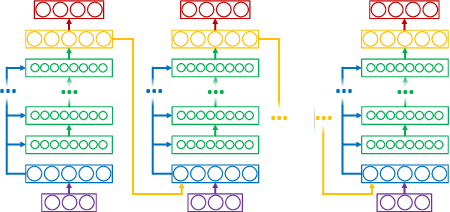
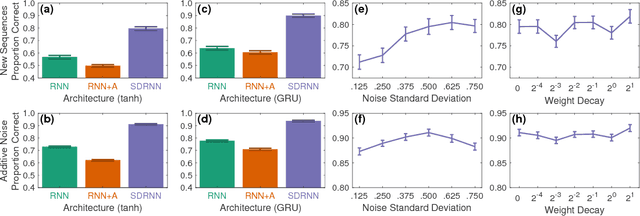
Recurrent neural networks (RNNs) are difficult to train on sequence processing tasks, not only because input noise may be amplified through feedback, but also because any inaccuracy in the weights has similar consequences as input noise. We describe a method for denoising the hidden state during training to achieve more robust representations thereby improving generalization performance. Attractor dynamics are incorporated into the hidden state to `clean up' representations at each step of a sequence. The attractor dynamics are trained through an auxillary denoising loss to recover previously experienced hidden states from noisy versions of those states. This state-denoised recurrent neural network {SDRNN} performs multiple steps of internal processing for each external sequence step. On a range of tasks, we show that the SDRNN outperforms a generic RNN as well as a variant of the SDRNN with attractor dynamics on the hidden state but without the auxillary loss. We argue that attractor dynamics---and corresponding connectivity constraints---are an essential component of the deep learning arsenal and should be invoked not only for recurrent networks but also for improving deep feedforward nets and intertask transfer.
Discrete Event, Continuous Time RNNs
Oct 11, 2017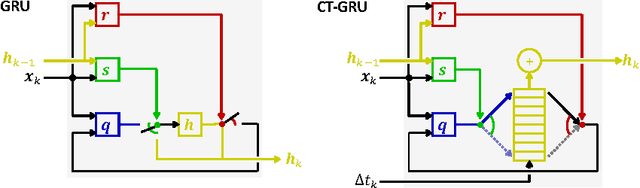
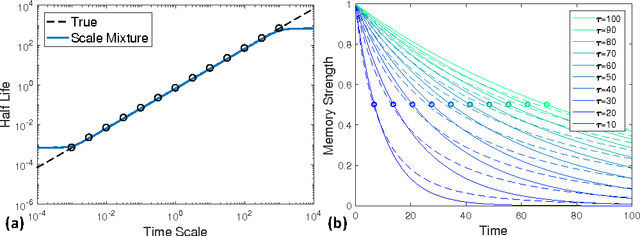
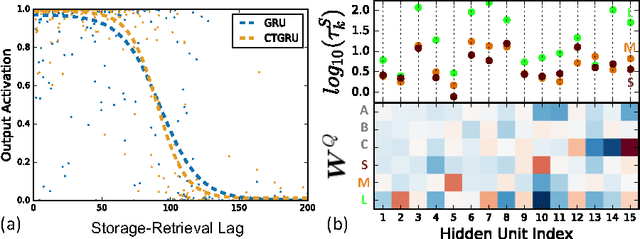

We investigate recurrent neural network architectures for event-sequence processing. Event sequences, characterized by discrete observations stamped with continuous-valued times of occurrence, are challenging due to the potentially wide dynamic range of relevant time scales as well as interactions between time scales. We describe four forms of inductive bias that should benefit architectures for event sequences: temporal locality, position and scale homogeneity, and scale interdependence. We extend the popular gated recurrent unit (GRU) architecture to incorporate these biases via intrinsic temporal dynamics, obtaining a continuous-time GRU. The CT-GRU arises by interpreting the gates of a GRU as selecting a time scale of memory, and the CT-GRU generalizes the GRU by incorporating multiple time scales of memory and performing context-dependent selection of time scales for information storage and retrieval. Event time-stamps drive decay dynamics of the CT-GRU, whereas they serve as generic additional inputs to the GRU. Despite the very different manner in which the two models consider time, their performance on eleven data sets we examined is essentially identical. Our surprising results point both to the robustness of GRU and LSTM architectures for handling continuous time, and to the potency of incorporating continuous dynamics into neural architectures.
How deep is knowledge tracing?
Jun 21, 2016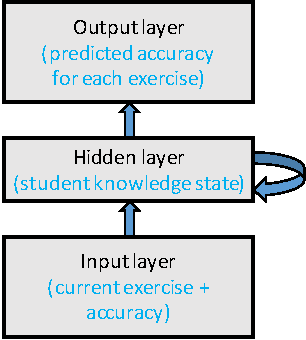
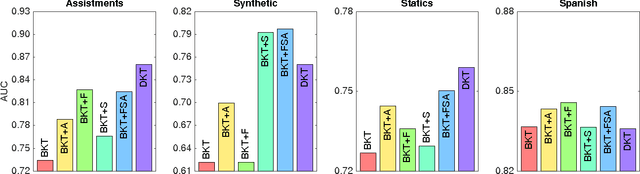
In theoretical cognitive science, there is a tension between highly structured models whose parameters have a direct psychological interpretation and highly complex, general-purpose models whose parameters and representations are difficult to interpret. The former typically provide more insight into cognition but the latter often perform better. This tension has recently surfaced in the realm of educational data mining, where a deep learning approach to predicting students' performance as they work through a series of exercises---termed deep knowledge tracing or DKT---has demonstrated a stunning performance advantage over the mainstay of the field, Bayesian knowledge tracing or BKT. In this article, we attempt to understand the basis for DKT's advantage by considering the sources of statistical regularity in the data that DKT can leverage but which BKT cannot. We hypothesize four forms of regularity that BKT fails to exploit: recency effects, the contextualized trial sequence, inter-skill similarity, and individual variation in ability. We demonstrate that when BKT is extended to allow it more flexibility in modeling statistical regularities---using extensions previously proposed in the literature---BKT achieves a level of performance indistinguishable from that of DKT. We argue that while DKT is a powerful, useful, general-purpose framework for modeling student learning, its gains do not come from the discovery of novel representations---the fundamental advantage of deep learning. To answer the question posed in our title, knowledge tracing may be a domain that does not require `depth'; shallow models like BKT can perform just as well and offer us greater interpretability and explanatory power.