 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow deep is knowledge tracing?
Jun 21, 2016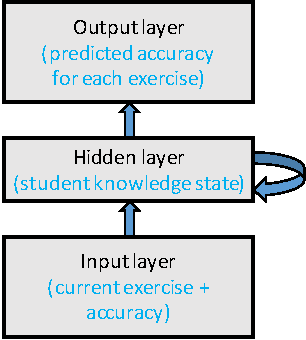
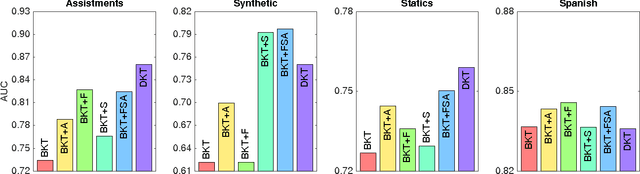
In theoretical cognitive science, there is a tension between highly structured models whose parameters have a direct psychological interpretation and highly complex, general-purpose models whose parameters and representations are difficult to interpret. The former typically provide more insight into cognition but the latter often perform better. This tension has recently surfaced in the realm of educational data mining, where a deep learning approach to predicting students' performance as they work through a series of exercises---termed deep knowledge tracing or DKT---has demonstrated a stunning performance advantage over the mainstay of the field, Bayesian knowledge tracing or BKT. In this article, we attempt to understand the basis for DKT's advantage by considering the sources of statistical regularity in the data that DKT can leverage but which BKT cannot. We hypothesize four forms of regularity that BKT fails to exploit: recency effects, the contextualized trial sequence, inter-skill similarity, and individual variation in ability. We demonstrate that when BKT is extended to allow it more flexibility in modeling statistical regularities---using extensions previously proposed in the literature---BKT achieves a level of performance indistinguishable from that of DKT. We argue that while DKT is a powerful, useful, general-purpose framework for modeling student learning, its gains do not come from the discovery of novel representations---the fundamental advantage of deep learning. To answer the question posed in our title, knowledge tracing may be a domain that does not require `depth'; shallow models like BKT can perform just as well and offer us greater interpretability and explanatory power.