 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Keypoint Detection and Description Network Based on the Vessel Structure for Multi-Modal Retinal Image Registration
Jan 06, 2022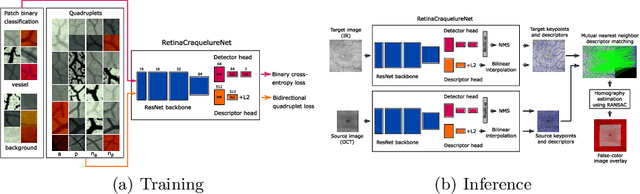

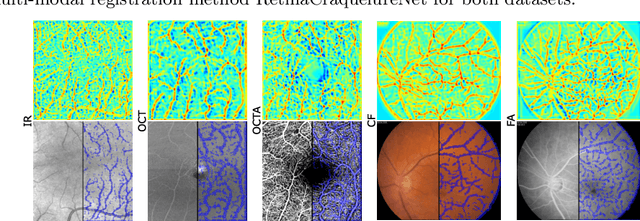

Ophthalmological imaging utilizes different imaging systems, such as color fundus, infrared, fluorescein angiography, optical coherence tomography (OCT) or OCT angiography. Multiple images with different modalities or acquisition times are often analyzed for the diagnosis of retinal diseases. Automatically aligning the vessel structures in the images by means of multi-modal registration can support the ophthalmologists in their work. Our method uses a convolutional neural network to extract features of the vessel structure in multi-modal retinal images. We jointly train a keypoint detection and description network on small patches using a classification and a cross-modal descriptor loss function and apply the network to the full image size in the test phase. Our method demonstrates the best registration performance on our and a public multi-modal dataset in comparison to competing methods.