 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep learning automates Cobb angle measurement compared with multi-expert observers
Mar 18, 2024Scoliosis, a prevalent condition characterized by abnormal spinal curvature leading to deformity, requires precise assessment methods for effective diagnosis and management. The Cobb angle is a widely used scoliosis quantification method that measures the degree of curvature between the tilted vertebrae. Yet, manual measuring of Cobb angles is time-consuming and labor-intensive, fraught with significant interobserver and intraobserver variability. To address these challenges and the lack of interpretability found in certain existing automated methods, we have created fully automated software that not only precisely measures the Cobb angle but also provides clear visualizations of these measurements. This software integrates deep neural network-based spine region detection and segmentation, spine centerline identification, pinpointing the most significantly tilted vertebrae, and direct visualization of Cobb angles on the original images. Upon comparison with the assessments of 7 expert readers, our algorithm exhibited a mean deviation in Cobb angle measurements of 4.17 degrees, notably surpassing the manual approach's average intra-reader discrepancy of 5.16 degrees. The algorithm also achieved intra-class correlation coefficients (ICC) exceeding 0.96 and Pearson correlation coefficients above 0.944, reflecting robust agreement with expert assessments and superior measurement reliability. Through the comprehensive reader study and statistical analysis, we believe this algorithm not only ensures a higher consensus with expert readers but also enhances interpretability and reproducibility during assessments. It holds significant promise for clinical application, potentially aiding physicians in more accurate scoliosis assessment and diagnosis, thereby improving patient care.
A recurrent connectionist model of melody perception : An exploration using TRACX2
Nov 21, 2023Are similar, or even identical, mechanisms used in the computational modeling of speech segmentation, serial image processing and music processing? We address this question by exploring how TRACX2, (French et al., 2011; French \& Cottrell, 2014; Mareschal \& French, 2017), a recognition-based, recursive connectionist autoencoder model of chunking and sequence segmentation, which has successfully simulated speech and serial-image processing, might be applied to elementary melody perception. The model, a three-layer autoencoder that recognizes ''chunks'' of short sequences of intervals that have been frequently encountered on input, is trained on the tone intervals of melodically simple French children's songs. It dynamically incorporates the internal representations of these chunks into new input. Its internal representations cluster in a manner that is consistent with ''human-recognizable'' melodic categories. TRACX2 is sensitive to both contour and proximity information in the musical chunks that it encounters in its input. It shows the ''end-of-word'' superiority effect demonstrated by Saffran et al. (1999) for short musical phrases. The overall findings suggest that the recursive autoassociative chunking mechanism, as implemented in TRACX2, may be a general segmentation and chunking mechanism, underlying not only word-and imagechunking, but also elementary melody processing.
SuperMask: Generating High-resolution object masks from multi-view, unaligned low-resolution MRIs
Mar 13, 2023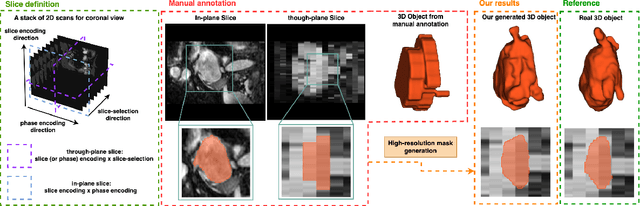

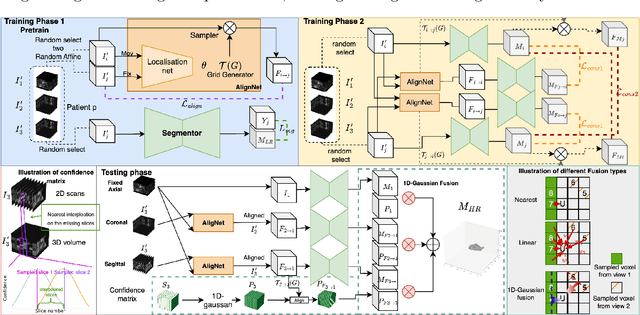
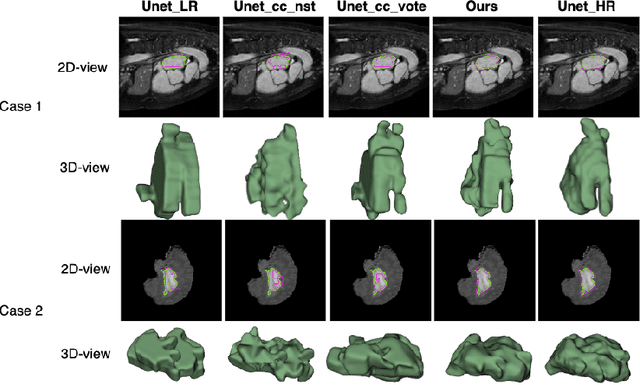
Three-dimensional segmentation in magnetic resonance images (MRI), which reflects the true shape of the objects, is challenging since high-resolution isotropic MRIs are rare and typical MRIs are anisotropic, with the out-of-plane dimension having a much lower resolution. A potential remedy to this issue lies in the fact that often multiple sequences are acquired on different planes. However, in practice, these sequences are not orthogonal to each other, limiting the applicability of many previous solutions to reconstruct higher-resolution images from multiple lower-resolution ones. We propose a weakly-supervised deep learning-based solution to generating high-resolution masks from multiple low-resolution images. Our method combines segmentation and unsupervised registration networks by introducing two new regularizations to make registration and segmentation reinforce each other. Finally, we introduce a multi-view fusion method to generate high-resolution target object masks. The experimental results on two datasets show the superiority of our methods. Importantly, the advantage of not using high-resolution images in the training process makes our method applicable to a wide variety of MRI segmentation tasks.