 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNews Category Dataset
Oct 06, 2022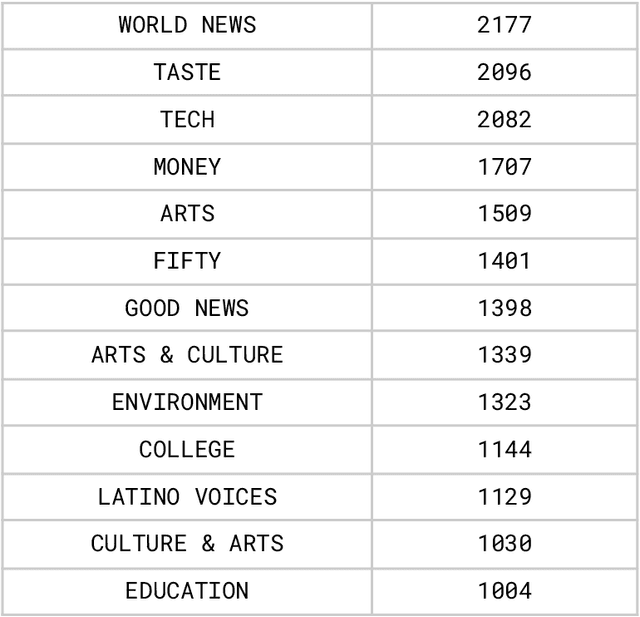
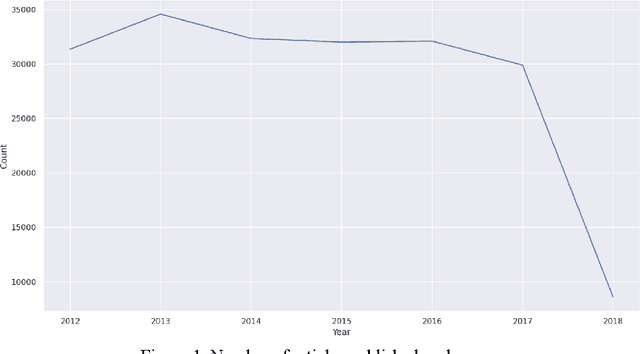
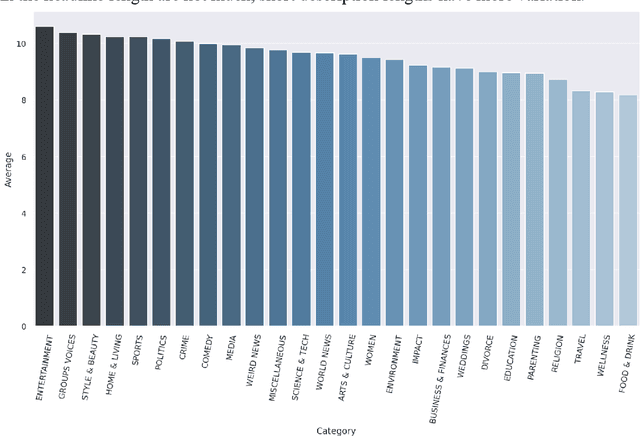

People rely on news to know what is happening around the world and inform their daily lives. In today's world, when the proliferation of fake news is rampant, having a large-scale and high-quality source of authentic news articles with the published category information is valuable to learning authentic news' Natural Language syntax and semantics. As part of this work, we present a News Category Dataset that contains around 210k news headlines from the year 2012 to 2022 obtained from HuffPost, along with useful metadata to enable various NLP tasks. In this paper, we also produce some novel insights from the dataset and describe various existing and potential applications of our dataset.
Hotel Recommendation System
Aug 21, 2019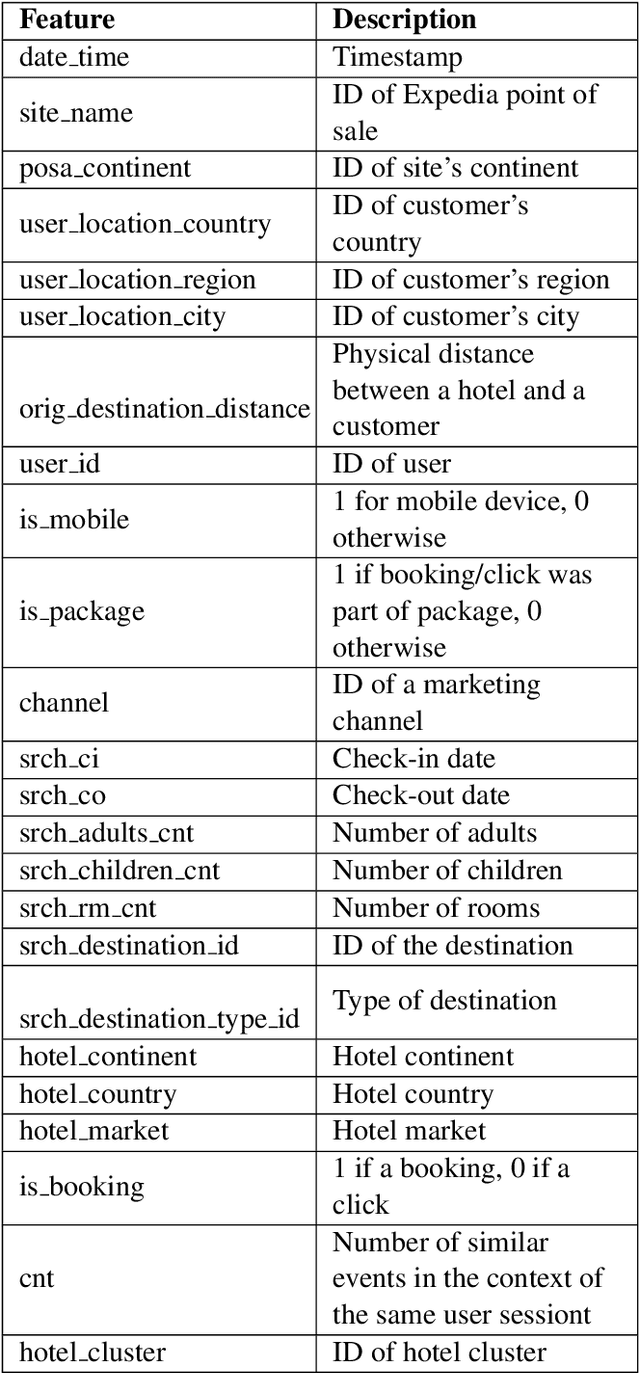
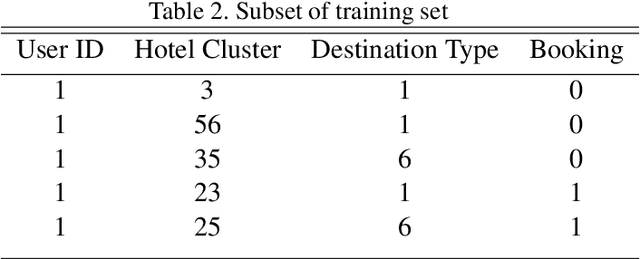
One of the first things to do while planning a trip is to book a good place to stay. Booking a hotel online can be an overwhelming task with thousands of hotels to choose from, for every destination. Motivated by the importance of these situations, we decided to work on the task of recommending hotels to users. We used Expedia's hotel recommendation dataset, which has a variety of features that helped us achieve a deep understanding of the process that makes a user choose certain hotels over others. The aim of this hotel recommendation task is to predict and recommend five hotel clusters to a user that he/she is more likely to book given hundred distinct clusters.
Sarcasm Detection using Hybrid Neural Network
Aug 20, 2019

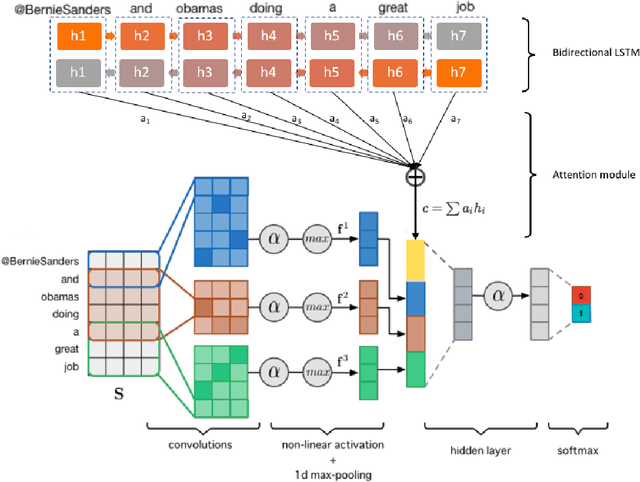

Sarcasm Detection has enjoyed great interest from the research community, however the task of predicting sarcasm in a text remains an elusive problem for machines. Past studies mostly make use of twitter datasets collected using hashtag based supervision but such datasets are noisy in terms of labels and language. To overcome these shortcoming, we introduce a new dataset which contains news headlines from a sarcastic news website and a real news website. Next, we propose a hybrid Neural Network architecture with attention mechanism which provides insights about what actually makes sentences sarcastic. Through experiments, we show that the proposed model improves upon the baseline by ~ 5% in terms of classification accuracy.
Fine-Grained Spoiler Detection from Large-Scale Review Corpora
May 31, 2019
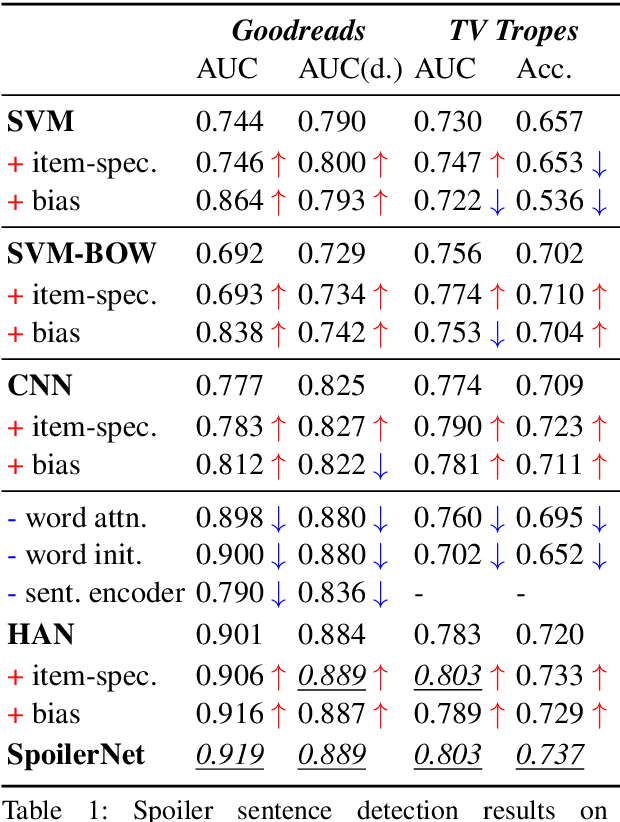
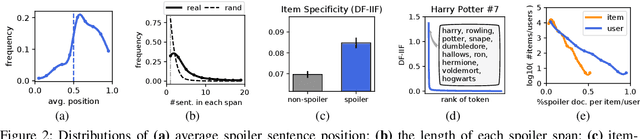

This paper presents computational approaches for automatically detecting critical plot twists in reviews of media products. First, we created a large-scale book review dataset that includes fine-grained spoiler annotations at the sentence-level, as well as book and (anonymized) user information. Second, we carefully analyzed this dataset, and found that: spoiler language tends to be book-specific; spoiler distributions vary greatly across books and review authors; and spoiler sentences tend to jointly appear in the latter part of reviews. Third, inspired by these findings, we developed an end-to-end neural network architecture to detect spoiler sentences in review corpora. Quantitative and qualitative results demonstrate that the proposed method substantially outperforms existing baselines.