 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVLM: Task-agnostic Video-Language Model Pre-training for Video Understanding
May 20, 2021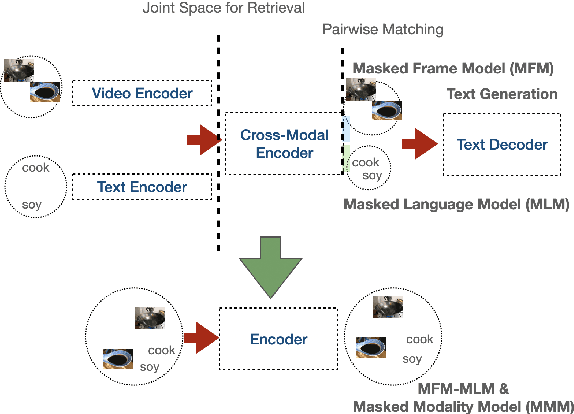

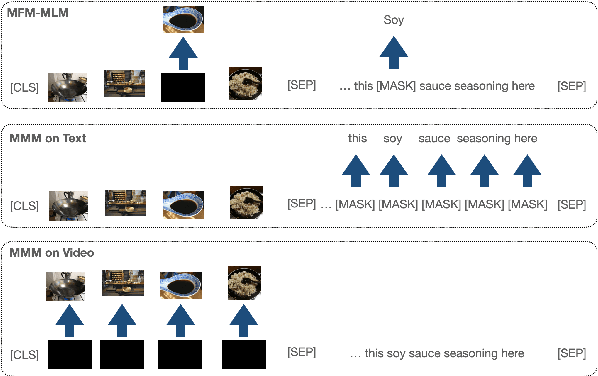
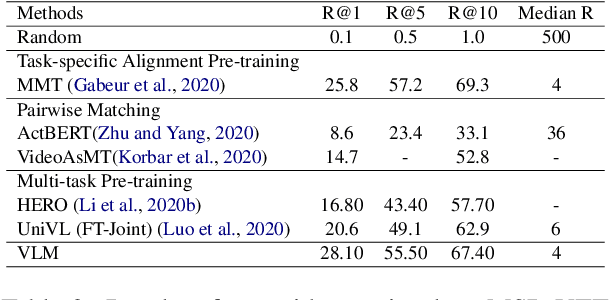
We present a simplified, task-agnostic multi-modal pre-training approach that can accept either video or text input, or both for a variety of end tasks. Existing pre-training are task-specific by adopting either a single cross-modal encoder that requires both modalities, limiting their use for retrieval-style end tasks or more complex multitask learning with two unimodal encoders, limiting early cross-modal fusion. We instead introduce new pretraining masking schemes that better mix across modalities (e.g. by forcing masks for text to predict the closest video embeddings) while also maintaining separability (e.g. unimodal predictions are sometimes required, without using all the input). Experimental results show strong performance across a wider range of tasks than any previous methods, often outperforming task-specific pre-training.
Sarcasm Detection using Hybrid Neural Network
Aug 20, 2019

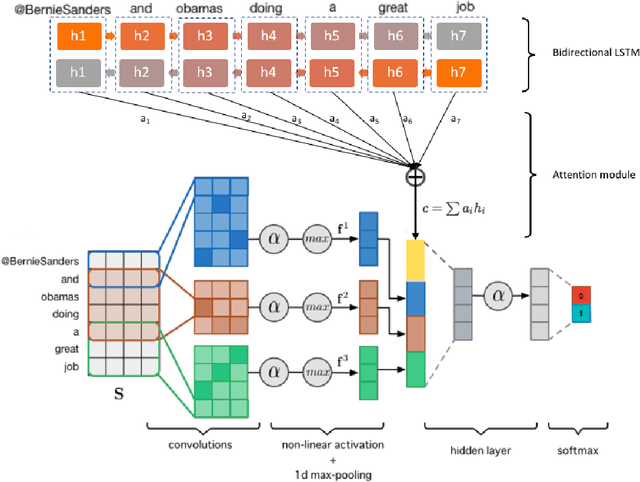

Sarcasm Detection has enjoyed great interest from the research community, however the task of predicting sarcasm in a text remains an elusive problem for machines. Past studies mostly make use of twitter datasets collected using hashtag based supervision but such datasets are noisy in terms of labels and language. To overcome these shortcoming, we introduce a new dataset which contains news headlines from a sarcastic news website and a real news website. Next, we propose a hybrid Neural Network architecture with attention mechanism which provides insights about what actually makes sentences sarcastic. Through experiments, we show that the proposed model improves upon the baseline by ~ 5% in terms of classification accuracy.