Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNews Category Dataset
Paper and Code
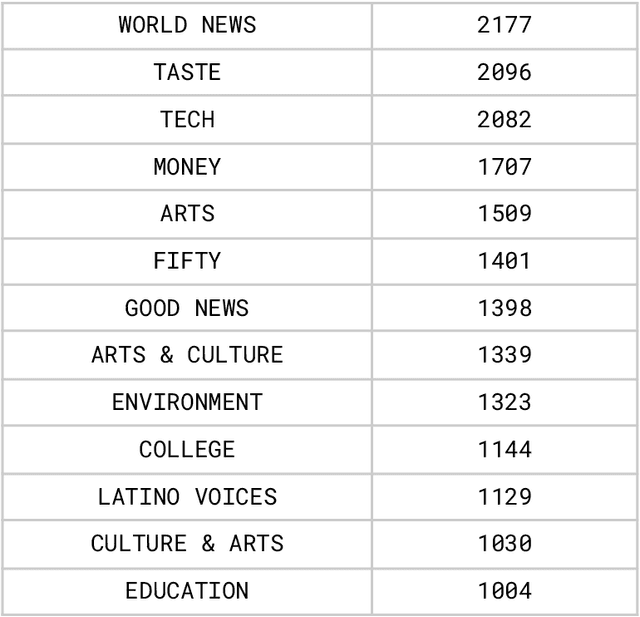
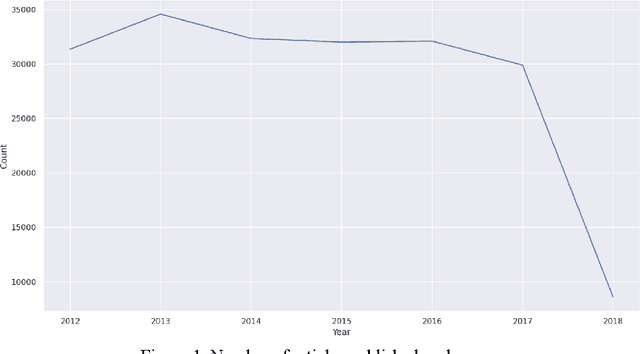
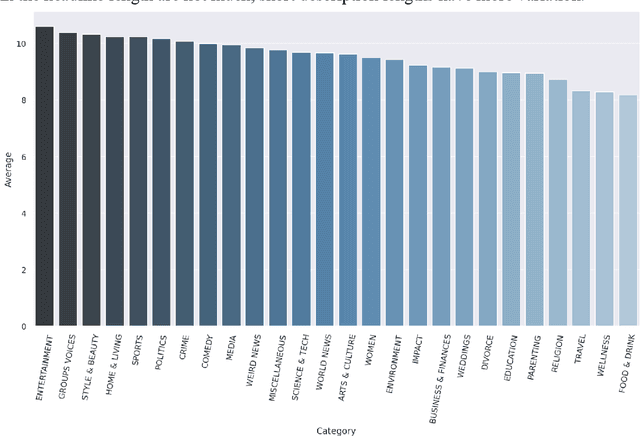

People rely on news to know what is happening around the world and inform their daily lives. In today's world, when the proliferation of fake news is rampant, having a large-scale and high-quality source of authentic news articles with the published category information is valuable to learning authentic news' Natural Language syntax and semantics. As part of this work, we present a News Category Dataset that contains around 210k news headlines from the year 2012 to 2022 obtained from HuffPost, along with useful metadata to enable various NLP tasks. In this paper, we also produce some novel insights from the dataset and describe various existing and potential applications of our dataset.
* correction of a missing citation
View paper on