Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural text normalization leveraging similarities of strings and sounds
Nov 04, 2020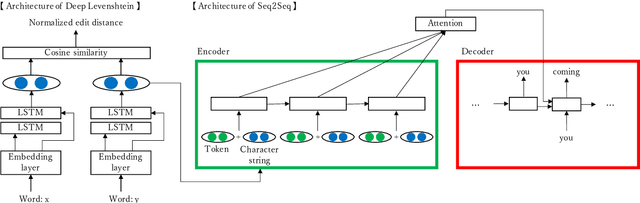

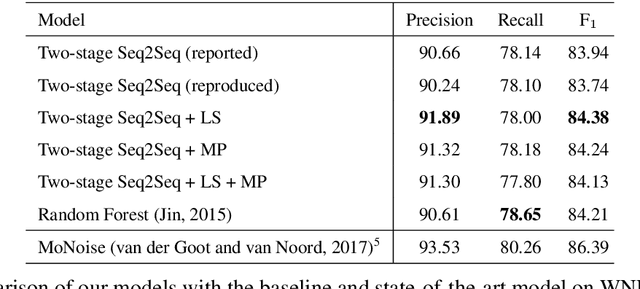
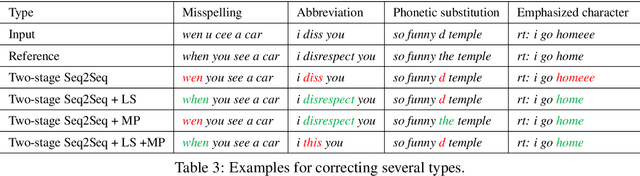
We propose neural models that can normalize text by considering the similarities of word strings and sounds. We experimentally compared a model that considers the similarities of both word strings and sounds, a model that considers only the similarity of word strings or of sounds, and a model without the similarities as a baseline. Results showed that leveraging the word string similarity succeeded in dealing with misspellings and abbreviations, and taking into account the sound similarity succeeded in dealing with phonetic substitutions and emphasized characters. So that the proposed models achieved higher F$_1$ scores than the baseline.
* 6 pages, accepted to COLING2020
Via