 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXEngine: Optimal Tensor Rematerialization for Neural Networks in Heterogeneous Environments
Dec 19, 2022
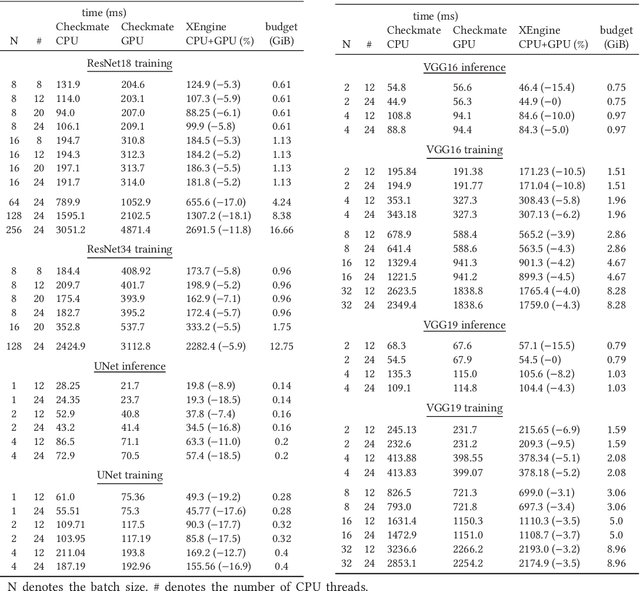
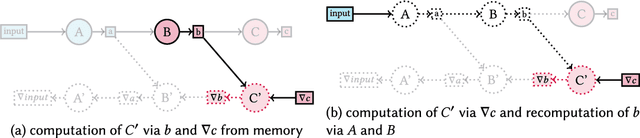
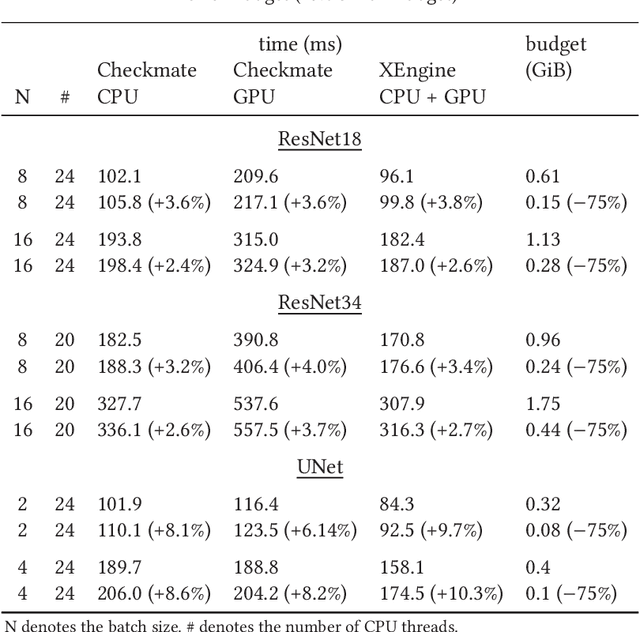
Memory efficiency is crucial in training deep learning networks on resource-restricted devices. During backpropagation, forward tensors are used to calculate gradients. Despite the option of keeping those dependencies in memory until they are reused in backpropagation, some forward tensors can be discarded and recomputed later from saved tensors, so-called checkpoints. This allows, in particular, for resource-constrained heterogeneous environments to make use of all available compute devices. Unfortunately, the definition of these checkpoints is a non-trivial problem and poses a challenge to the programmer - improper or excessive recomputations negate the benefit of checkpointing. In this article, we present XEngine, an approach that schedules network operators to heterogeneous devices in low memory environments by determining checkpoints and recomputations of tensors. Our approach selects suitable resources per timestep and operator and optimizes the end-to-end time for neural networks taking the memory limitation of each device into account. For this, we formulate a mixed-integer quadratic program (MIQP) to schedule operators of deep learning networks on heterogeneous systems. We compare our MIQP solver XEngine against Checkmate, a mixed-integer linear programming (MILP) approach that solves recomputation on a single device. Our solver finds solutions that are up to 22.5 % faster than the fastest Checkmate schedule in which the network is computed exclusively on a single device. We also find valid schedules for networks making use of both central processing units and graphics processing units if memory limitations do not allow scheduling exclusively to the graphics processing unit.
FLOWER: A comprehensive dataflow compiler for high-level synthesis
Dec 14, 2021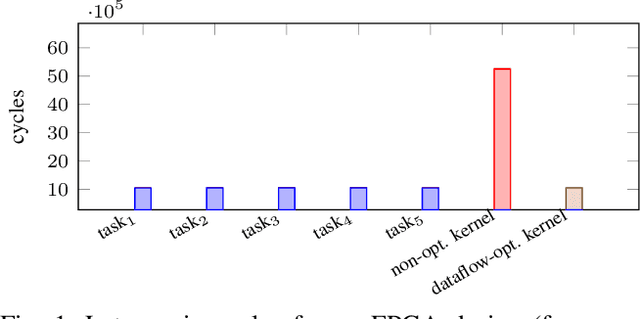
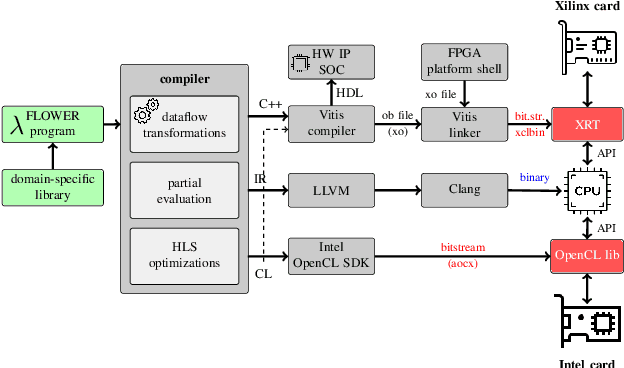
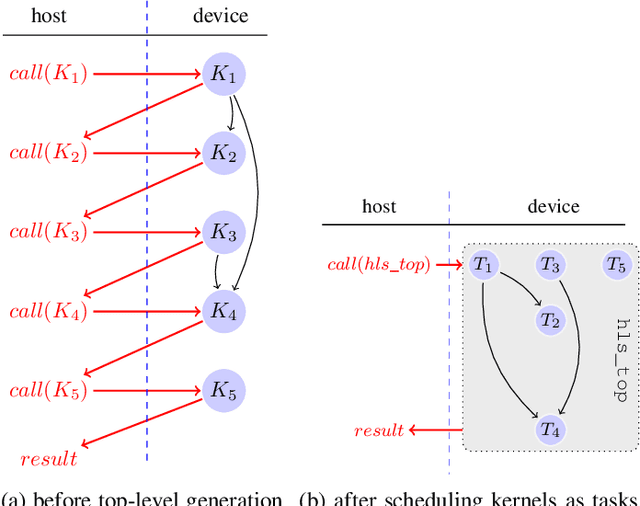
FPGAs have found their way into data centers as accelerator cards, making reconfigurable computing more accessible for high-performance applications. At the same time, new high-level synthesis compilers like Xilinx Vitis and runtime libraries such as XRT attract software programmers into the reconfigurable domain. While software programmers are familiar with task-level and data-parallel programming, FPGAs often require different types of parallelism. For example, data-driven parallelism is mandatory to obtain satisfactory hardware designs for pipelined dataflow architectures. However, software programmers are often not acquainted with dataflow architectures - resulting in poor hardware designs. In this work we present FLOWER, a comprehensive compiler infrastructure that provides automatic canonical transformations for high-level synthesis from a domain-specific library. This allows programmers to focus on algorithm implementations rather than low-level optimizations for dataflow architectures. We show that FLOWER allows to synthesize efficient implementations for high-performance streaming applications targeting System-on-Chip and FPGA accelerator cards, in the context of image processing and computer vision.
Parallel Multi-Hypothesis Algorithm for Criticality Estimation in Traffic and Collision Avoidance
May 14, 2020
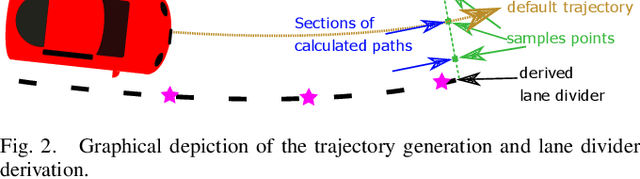
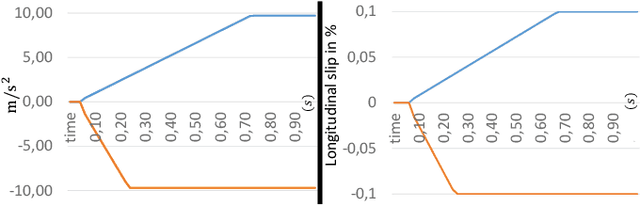
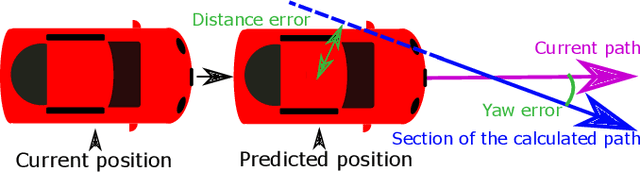
Due to the current developments towards autonomous driving and vehicle active safety, there is an increasing necessity for algorithms that are able to perform complex criticality predictions in real-time. Being able to process multi-object traffic scenarios aids the implementation of a variety of automotive applications such as driver assistance systems for collision prevention and mitigation as well as fall-back systems for autonomous vehicles. We present a fully model-based algorithm with a parallelizable architecture. The proposed algorithm can evaluate the criticality of complex, multi-modal (vehicles and pedestrians) traffic scenarios by simulating millions of trajectory combinations and detecting collisions between objects. The algorithm is able to estimate upcoming criticality at very early stages, demonstrating its potential for vehicle safety-systems and autonomous driving applications. An implementation on an embedded system in a test vehicle proves in a prototypical manner the compatibility of the algorithm with the hardware possibilities of modern cars. For a complex traffic scenario with 11 dynamic objects, more than 86 million pose combinations are evaluated in 21 ms on the GPU of a Drive PX~2.