 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXEngine: Optimal Tensor Rematerialization for Neural Networks in Heterogeneous Environments
Dec 19, 2022
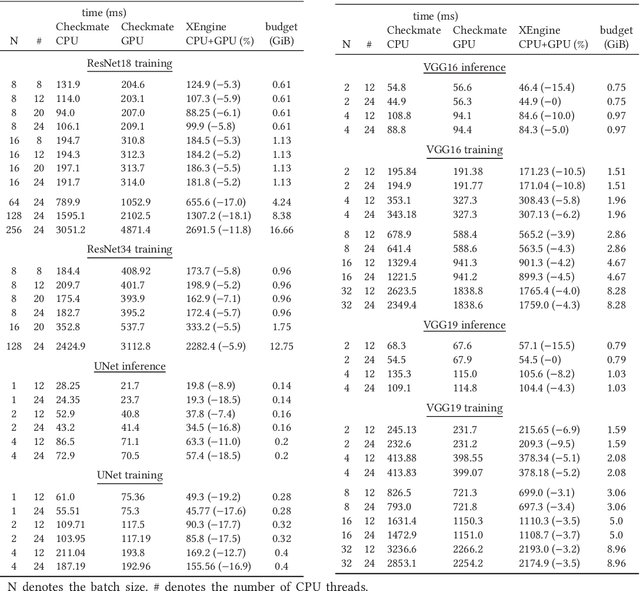
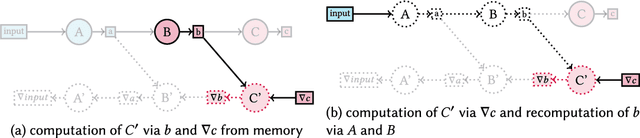
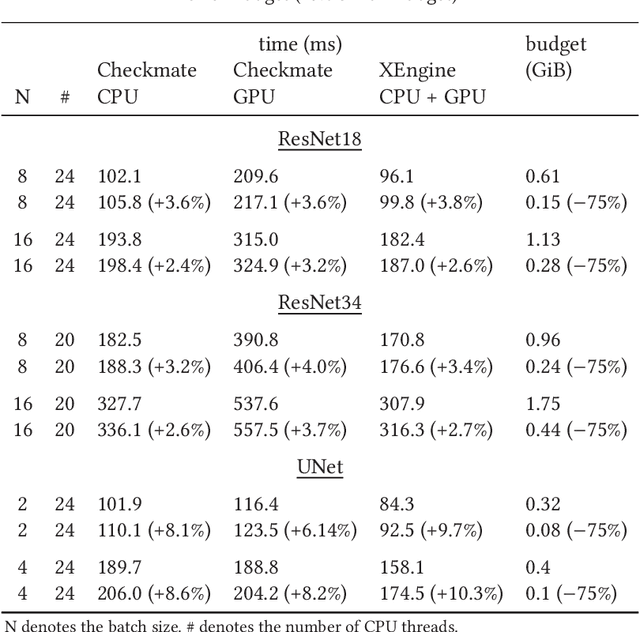
Memory efficiency is crucial in training deep learning networks on resource-restricted devices. During backpropagation, forward tensors are used to calculate gradients. Despite the option of keeping those dependencies in memory until they are reused in backpropagation, some forward tensors can be discarded and recomputed later from saved tensors, so-called checkpoints. This allows, in particular, for resource-constrained heterogeneous environments to make use of all available compute devices. Unfortunately, the definition of these checkpoints is a non-trivial problem and poses a challenge to the programmer - improper or excessive recomputations negate the benefit of checkpointing. In this article, we present XEngine, an approach that schedules network operators to heterogeneous devices in low memory environments by determining checkpoints and recomputations of tensors. Our approach selects suitable resources per timestep and operator and optimizes the end-to-end time for neural networks taking the memory limitation of each device into account. For this, we formulate a mixed-integer quadratic program (MIQP) to schedule operators of deep learning networks on heterogeneous systems. We compare our MIQP solver XEngine against Checkmate, a mixed-integer linear programming (MILP) approach that solves recomputation on a single device. Our solver finds solutions that are up to 22.5 % faster than the fastest Checkmate schedule in which the network is computed exclusively on a single device. We also find valid schedules for networks making use of both central processing units and graphics processing units if memory limitations do not allow scheduling exclusively to the graphics processing unit.