 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMammo-Mamba: A Hybrid State-Space and Transformer Architecture with Sequential Mixture of Experts for Multi-View Mammography
Jul 23, 2025Breast cancer (BC) remains one of the leading causes of cancer-related mortality among women, despite recent advances in Computer-Aided Diagnosis (CAD) systems. Accurate and efficient interpretation of multi-view mammograms is essential for early detection, driving a surge of interest in Artificial Intelligence (AI)-powered CAD models. While state-of-the-art multi-view mammogram classification models are largely based on Transformer architectures, their computational complexity scales quadratically with the number of image patches, highlighting the need for more efficient alternatives. To address this challenge, we propose Mammo-Mamba, a novel framework that integrates Selective State-Space Models (SSMs), transformer-based attention, and expert-driven feature refinement into a unified architecture. Mammo-Mamba extends the MambaVision backbone by introducing the Sequential Mixture of Experts (SeqMoE) mechanism through its customized SecMamba block. The SecMamba is a modified MambaVision block that enhances representation learning in high-resolution mammographic images by enabling content-adaptive feature refinement. These blocks are integrated into the deeper stages of MambaVision, allowing the model to progressively adjust feature emphasis through dynamic expert gating, effectively mitigating the limitations of traditional Transformer models. Evaluated on the CBIS-DDSM benchmark dataset, Mammo-Mamba achieves superior classification performance across all key metrics while maintaining computational efficiency.
AutoRad-Lung: A Radiomic-Guided Prompting Autoregressive Vision-Language Model for Lung Nodule Malignancy Prediction
Mar 26, 2025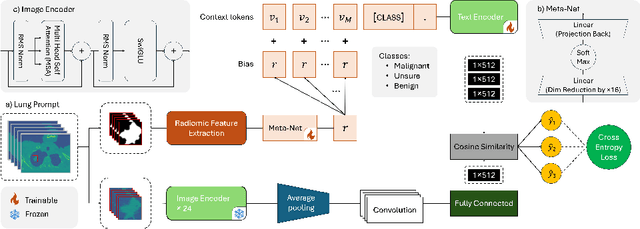
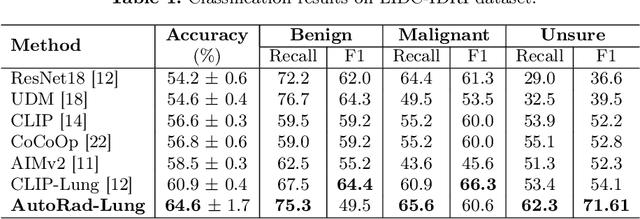
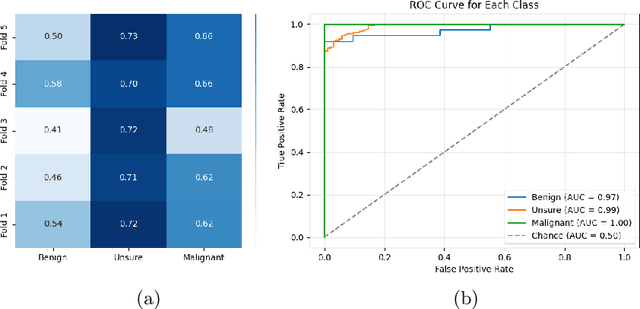
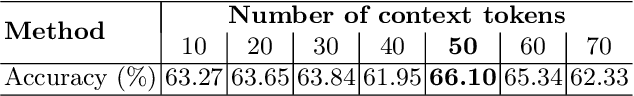
Lung cancer remains one of the leading causes of cancer-related mortality worldwide. A crucial challenge for early diagnosis is differentiating uncertain cases with similar visual characteristics and closely annotation scores. In clinical practice, radiologists rely on quantitative, hand-crafted Radiomic features extracted from Computed Tomography (CT) images, while recent research has primarily focused on deep learning solutions. More recently, Vision-Language Models (VLMs), particularly Contrastive Language-Image Pre-Training (CLIP)-based models, have gained attention for their ability to integrate textual knowledge into lung cancer diagnosis. While CLIP-Lung models have shown promising results, we identified the following potential limitations: (a) dependence on radiologists' annotated attributes, which are inherently subjective and error-prone, (b) use of textual information only during training, limiting direct applicability at inference, and (c) Convolutional-based vision encoder with randomly initialized weights, which disregards prior knowledge. To address these limitations, we introduce AutoRad-Lung, which couples an autoregressively pre-trained VLM, with prompts generated from hand-crafted Radiomics. AutoRad-Lung uses the vision encoder of the Large-Scale Autoregressive Image Model (AIMv2), pre-trained using a multi-modal autoregressive objective. Given that lung tumors are typically small, irregularly shaped, and visually similar to healthy tissue, AutoRad-Lung offers significant advantages over its CLIP-based counterparts by capturing pixel-level differences. Additionally, we introduce conditional context optimization, which dynamically generates context-specific prompts based on input Radiomics, improving cross-modal alignment.
Integrating AI for Human-Centric Breast Cancer Diagnostics: A Multi-Scale and Multi-View Swin Transformer Framework
Mar 17, 2025



Despite advancements in Computer-Aided Diagnosis (CAD) systems, breast cancer remains one of the leading causes of cancer-related deaths among women worldwide. Recent breakthroughs in Artificial Intelligence (AI) have shown significant promise in development of advanced Deep Learning (DL) architectures for breast cancer diagnosis through mammography. In this context, the paper focuses on the integration of AI within a Human-Centric workflow to enhance breast cancer diagnostics. Key challenges are, however, largely overlooked such as reliance on detailed tumor annotations and susceptibility to missing views, particularly during test time. To address these issues, we propose a hybrid, multi-scale and multi-view Swin Transformer-based framework (MSMV-Swin) that enhances diagnostic robustness and accuracy. The proposed MSMV-Swin framework is designed to work as a decision-support tool, helping radiologists analyze multi-view mammograms more effectively. More specifically, the MSMV-Swin framework leverages the Segment Anything Model (SAM) to isolate the breast lobe, reducing background noise and enabling comprehensive feature extraction. The multi-scale nature of the proposed MSMV-Swin framework accounts for tumor-specific regions as well as the spatial characteristics of tissues surrounding the tumor, capturing both localized and contextual information. The integration of contextual and localized data ensures that MSMV-Swin's outputs align with the way radiologists interpret mammograms, fostering better human-AI interaction and trust. A hybrid fusion structure is then designed to ensure robustness against missing views, a common occurrence in clinical practice when only a single mammogram view is available.