 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoRad-Lung: A Radiomic-Guided Prompting Autoregressive Vision-Language Model for Lung Nodule Malignancy Prediction
Paper and Code
Mar 26, 2025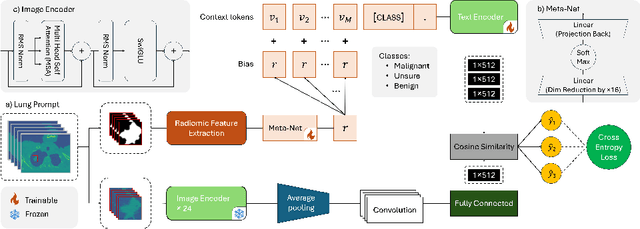
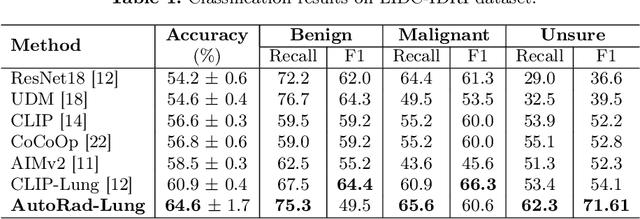
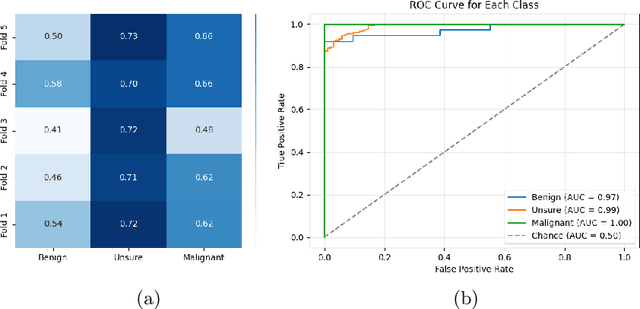
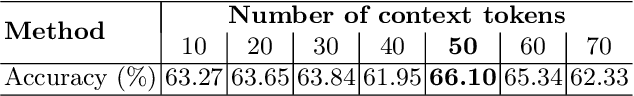
Lung cancer remains one of the leading causes of cancer-related mortality worldwide. A crucial challenge for early diagnosis is differentiating uncertain cases with similar visual characteristics and closely annotation scores. In clinical practice, radiologists rely on quantitative, hand-crafted Radiomic features extracted from Computed Tomography (CT) images, while recent research has primarily focused on deep learning solutions. More recently, Vision-Language Models (VLMs), particularly Contrastive Language-Image Pre-Training (CLIP)-based models, have gained attention for their ability to integrate textual knowledge into lung cancer diagnosis. While CLIP-Lung models have shown promising results, we identified the following potential limitations: (a) dependence on radiologists' annotated attributes, which are inherently subjective and error-prone, (b) use of textual information only during training, limiting direct applicability at inference, and (c) Convolutional-based vision encoder with randomly initialized weights, which disregards prior knowledge. To address these limitations, we introduce AutoRad-Lung, which couples an autoregressively pre-trained VLM, with prompts generated from hand-crafted Radiomics. AutoRad-Lung uses the vision encoder of the Large-Scale Autoregressive Image Model (AIMv2), pre-trained using a multi-modal autoregressive objective. Given that lung tumors are typically small, irregularly shaped, and visually similar to healthy tissue, AutoRad-Lung offers significant advantages over its CLIP-based counterparts by capturing pixel-level differences. Additionally, we introduce conditional context optimization, which dynamically generates context-specific prompts based on input Radiomics, improving cross-modal alignment.