 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOrigin-Aware Next Destination Recommendation with Personalized Preference Attention
Jan 11, 2021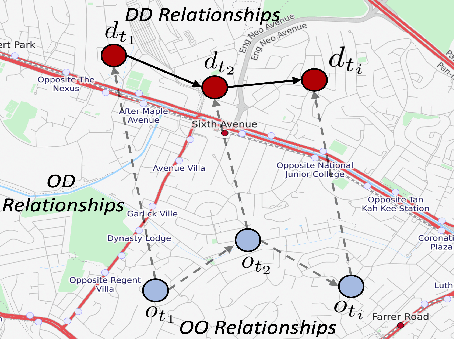
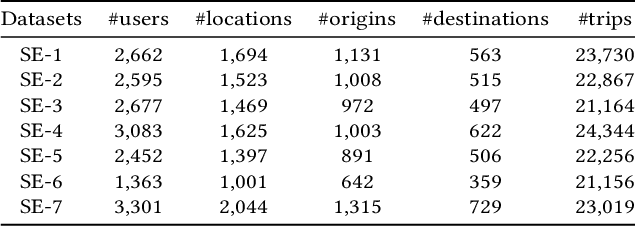
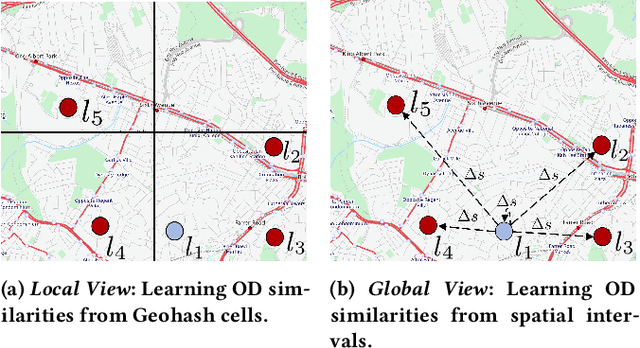
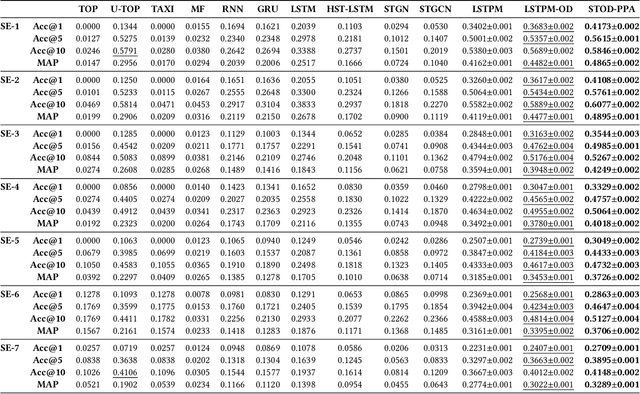
Next destination recommendation is an important task in the transportation domain of taxi and ride-hailing services, where users are recommended with personalized destinations given their current origin location. However, recent recommendation works do not satisfy this origin-awareness property, and only consider learning from historical destination locations, without origin information. Thus, the resulting approaches are unable to learn and predict origin-aware recommendations based on the user's current location, leading to sub-optimal performance and poor real-world practicality. Hence, in this work, we study the origin-aware next destination recommendation task. We propose the Spatial-Temporal Origin-Destination Personalized Preference Attention (STOD-PPA) encoder-decoder model to learn origin-origin (OO), destination-destination (DD), and origin-destination (OD) relationships by first encoding both origin and destination sequences with spatial and temporal factors in local and global views, then decoding them through personalized preference attention to predict the next destination. Experimental results on seven real-world user trajectory taxi datasets show that our model significantly outperforms baseline and state-of-the-art methods.
STP-UDGAT: Spatial-Temporal-Preference User Dimensional Graph Attention Network for Next POI Recommendation
Oct 06, 2020
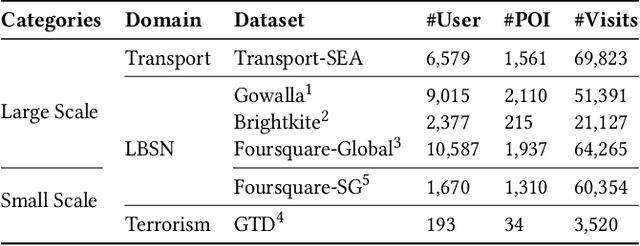
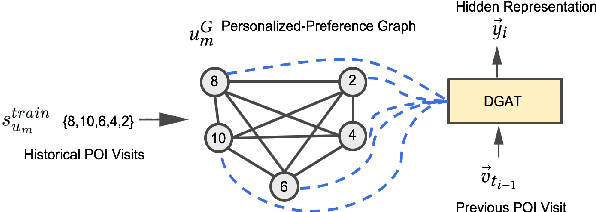
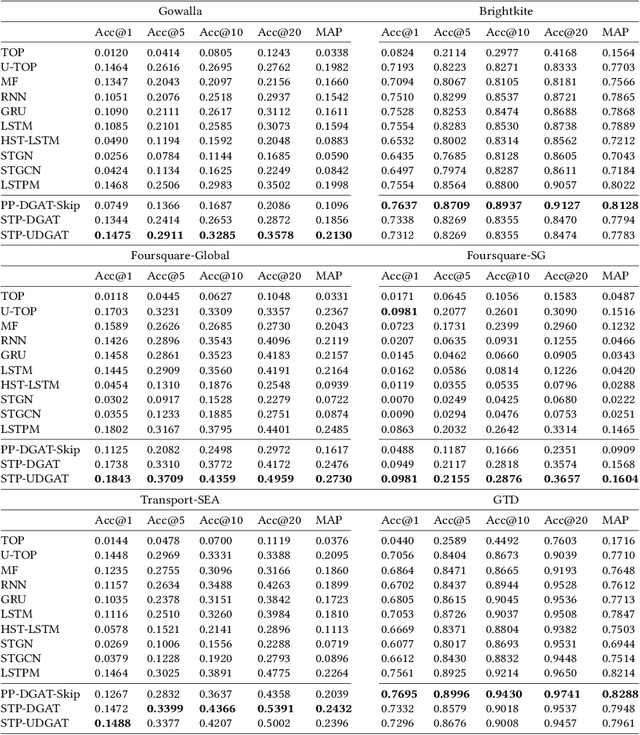
Next Point-of-Interest (POI) recommendation is a longstanding problem across the domains of Location-Based Social Networks (LBSN) and transportation. Recent Recurrent Neural Network (RNN) based approaches learn POI-POI relationships in a local view based on independent user visit sequences. This limits the model's ability to directly connect and learn across users in a global view to recommend semantically trained POIs. In this work, we propose a Spatial-Temporal-Preference User Dimensional Graph Attention Network (STP-UDGAT), a novel explore-exploit model that concurrently exploits personalized user preferences and explores new POIs in global spatial-temporal-preference (STP) neighbourhoods, while allowing users to selectively learn from other users. In addition, we propose random walks as a masked self-attention option to leverage the STP graphs' structures and find new higher-order POI neighbours during exploration. Experimental results on six real-world datasets show that our model significantly outperforms baseline and state-of-the-art methods.