 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStory Shaping: Teaching Agents Human-like Behavior with Stories
Jan 24, 2023Reward design for reinforcement learning agents can be difficult in situations where one not only wants the agent to achieve some effect in the world but where one also cares about how that effect is achieved. For example, we might wish for an agent to adhere to a tacit understanding of commonsense, align itself to a preference for how to behave for purposes of safety, or taking on a particular role in an interactive game. Storytelling is a mode for communicating tacit procedural knowledge. We introduce a technique, Story Shaping, in which a reinforcement learning agent infers tacit knowledge from an exemplar story of how to accomplish a task and intrinsically rewards itself for performing actions that make its current environment adhere to that of the inferred story world. Specifically, Story Shaping infers a knowledge graph representation of the world state from observations, and also infers a knowledge graph from the exemplar story. An intrinsic reward is generated based on the similarity between the agent's inferred world state graph and the inferred story world graph. We conducted experiments in text-based games requiring commonsense reasoning and shaping the behaviors of agents as virtual game characters.
Situated Dialogue Learning through Procedural Environment Generation
Oct 07, 2021

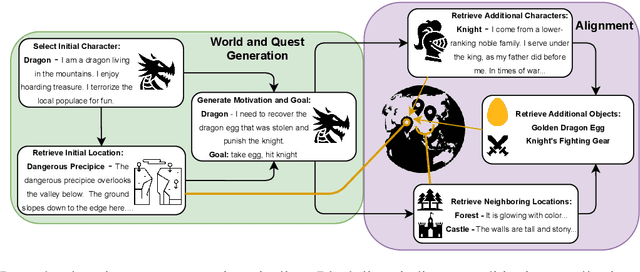

We teach goal-driven agents to interactively act and speak in situated environments by training on generated curriculums. Our agents operate in LIGHT (Urbanek et al. 2019) -- a large-scale crowd-sourced fantasy text adventure game wherein an agent perceives and interacts with the world through textual natural language. Goals in this environment take the form of character-based quests, consisting of personas and motivations. We augment LIGHT by learning to procedurally generate additional novel textual worlds and quests to create a curriculum of steadily increasing difficulty for training agents to achieve such goals. In particular, we measure curriculum difficulty in terms of the rarity of the quest in the original training distribution -- an easier environment is one that is more likely to have been found in the unaugmented dataset. An ablation study shows that this method of learning from the tail of a distribution results in significantly higher generalization abilities as measured by zero-shot performance on never-before-seen quests.