 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA generalized method toward drug-target interaction prediction via low-rank matrix projection
May 03, 2018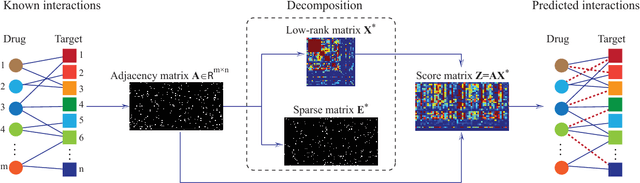
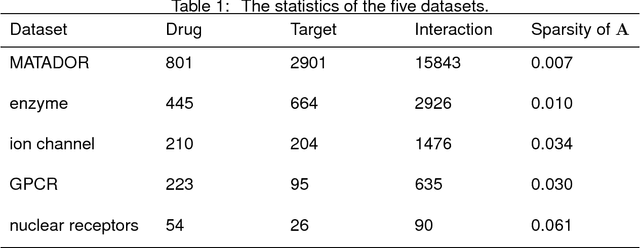
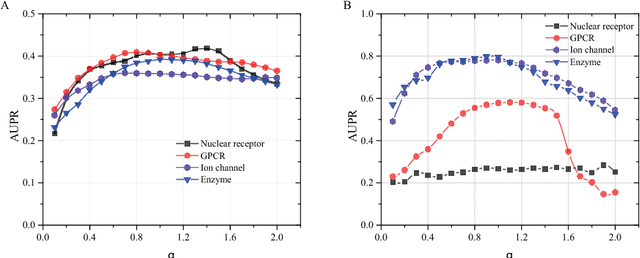
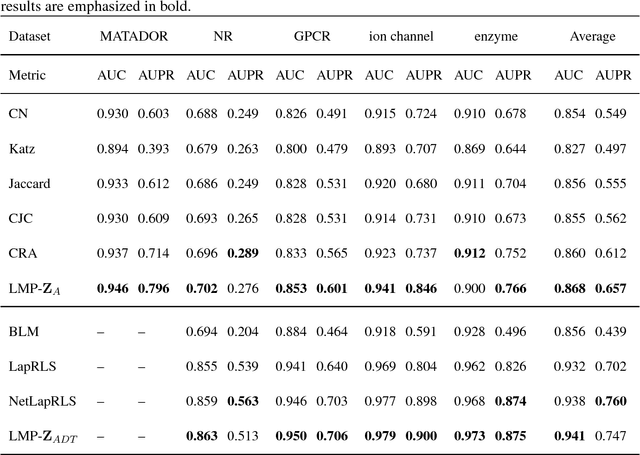
Drug-target interaction (DTI) prediction plays a very important role in drug development and drug discovery. Biochemical experiments or \textit{in vitro} methods are very expensive, laborious and time-consuming. Therefore, \textit{in silico} approaches including docking simulation and machine learning have been proposed to solve this problem. In particular, machine learning approaches have attracted increasing attentions recently. However, in addition to the known drug-target interactions, most of the machine learning methods require extra characteristic information such as chemical structures, genome sequences, binding types and so on. Whenever such information is not available, they may perform poor. Very recently, the similarity-based link prediction methods were extended to bipartite networks, which can be applied to solve the DTI prediction problem by using topological information only. In this work, we propose a method based on low-rank matrix projection to solve the DTI prediction problem. On one hand, when there is no extra characteristic information of drugs or targets, the proposed method utilizes only the known interactions. On the other hand, the proposed method can also utilize the extra characteristic information when it is available and the performances will be remarkably improved. Moreover, the proposed method can predict the interactions associated with new drugs or targets of which we know nothing about their associated interactions, but only some characteristic information. We compare the proposed method with ten baseline methods, e.g., six similarity-based methods that utilize only the known interactions and four methods that utilize the extra characteristic information. The datasets and codes implementing the simulations are available at https://github.com/rathapech/DTI_LMP.
Link Prediction via Matrix Completion
Jun 23, 2016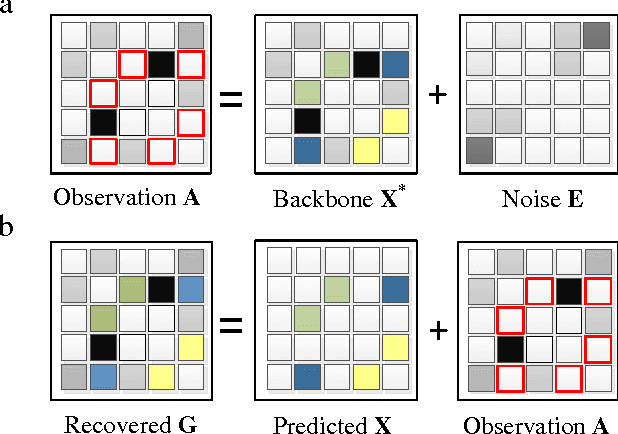
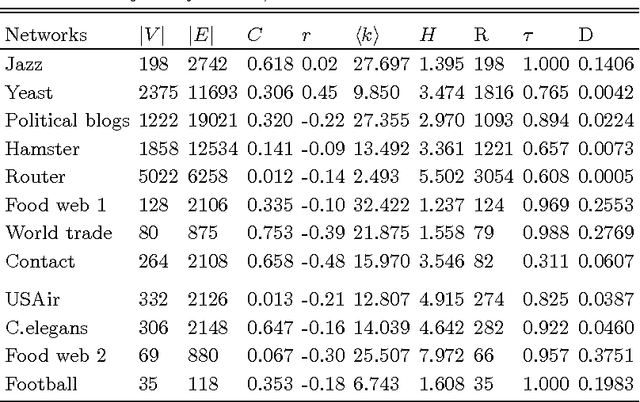
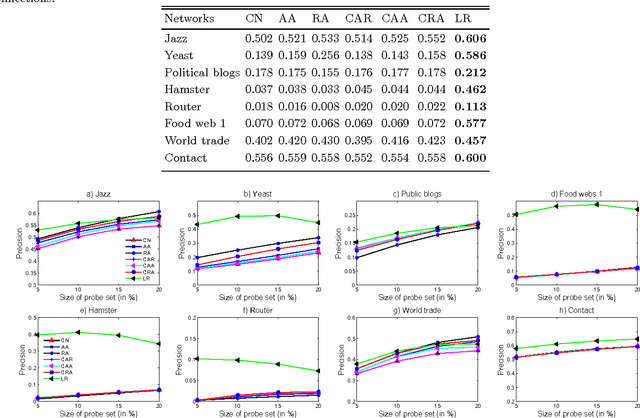
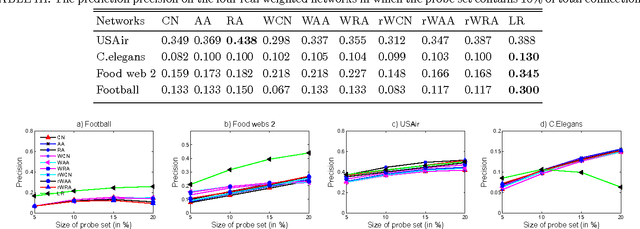
Inspired by practical importance of social networks, economic networks, biological networks and so on, studies on large and complex networks have attracted a surge of attentions in the recent years. Link prediction is a fundamental issue to understand the mechanisms by which new links are added to the networks. We introduce the method of robust principal component analysis (robust PCA) into link prediction, and estimate the missing entries of the adjacency matrix. On one hand, our algorithm is based on the sparsity and low rank property of the matrix, on the other hand, it also performs very well when the network is dense. This is because a relatively dense real network is also sparse in comparison to the complete graph. According to extensive experiments on real networks from disparate fields, when the target network is connected and sufficiently dense, whatever it is weighted or unweighted, our method is demonstrated to be very effective and with prediction accuracy being considerably improved comparing with many state-of-the-art algorithms.