 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI Learns to Recognize Bengali Handwritten Digits: Bengali.AI Computer Vision Challenge 2018
Oct 10, 2018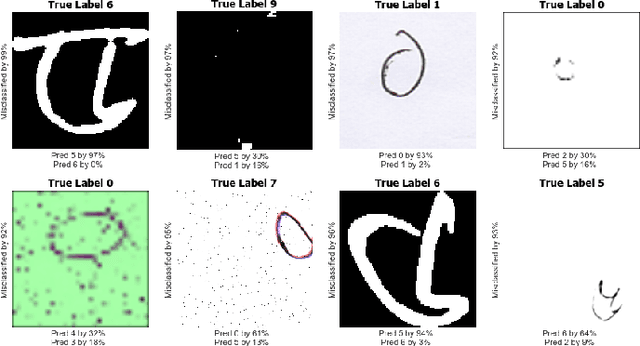
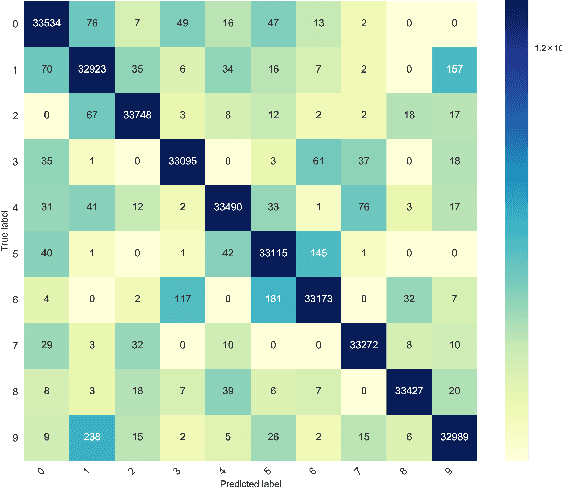
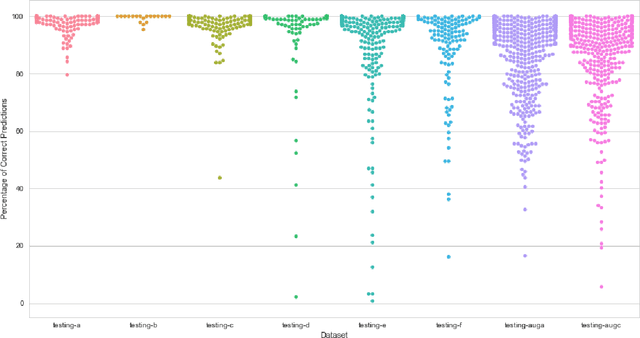
Solving problems with Artificial intelligence in a competitive manner has long been absent in Bangladesh and Bengali-speaking community. On the other hand, there has not been a well structured database for Bengali Handwritten digits for mass public use. To bring out the best minds working in machine learning and use their expertise to create a model which can easily recognize Bengali Handwritten digits, we organized Bengali.AI Computer Vision Challenge.The challenge saw both local and international teams participating with unprecedented efforts.
NumtaDB - Assembled Bengali Handwritten Digits
Jun 06, 2018


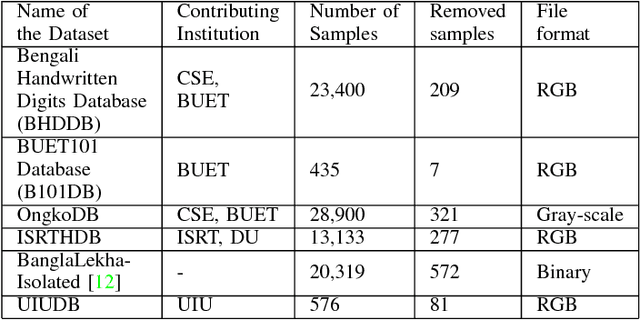
To benchmark Bengali digit recognition algorithms, a large publicly available dataset is required which is free from biases originating from geographical location, gender, and age. With this aim in mind, NumtaDB, a dataset consisting of more than 85,000 images of hand-written Bengali digits, has been assembled. This paper documents the collection and curation process of numerals along with the salient statistics of the dataset.