Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNumtaDB - Assembled Bengali Handwritten Digits
Paper and Code
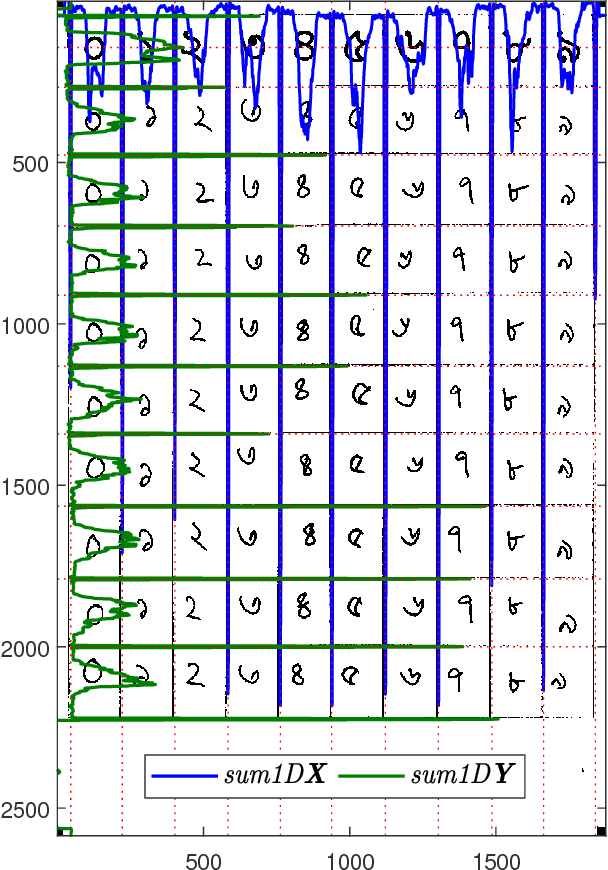

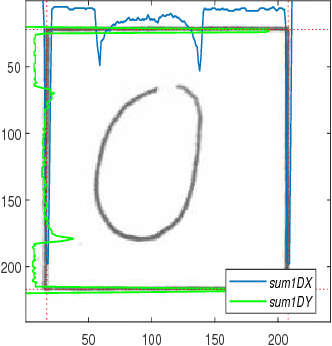

To benchmark Bengali digit recognition algorithms, a large publicly available dataset is required which is free from biases originating from geographical location, gender, and age. With this aim in mind, NumtaDB, a dataset consisting of more than 85,000 images of hand-written Bengali digits, has been assembled. This paper documents the collection and curation process of numerals along with the salient statistics of the dataset.
* 6 page, 12 figures
View paper on