 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Theory of Universal Learning
Nov 09, 2020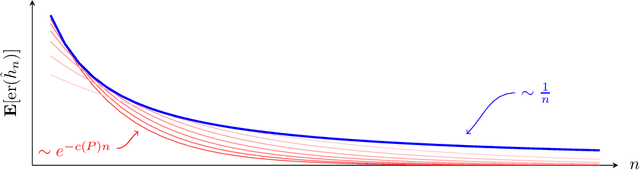
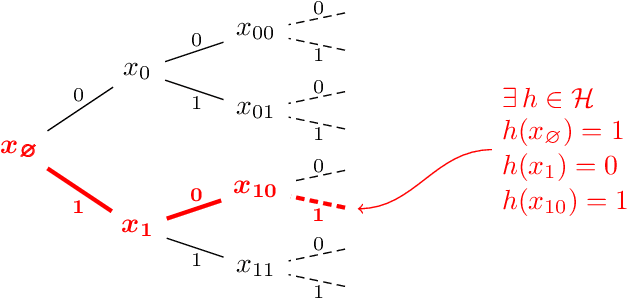
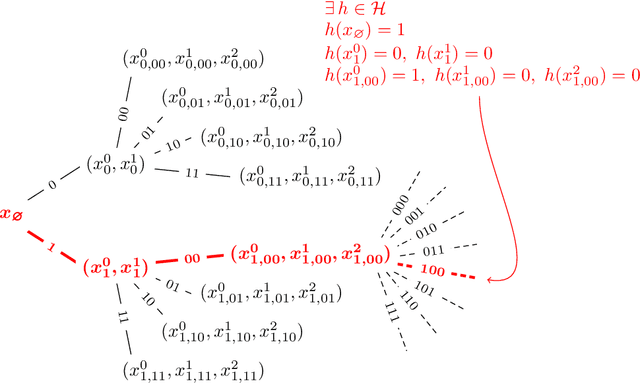
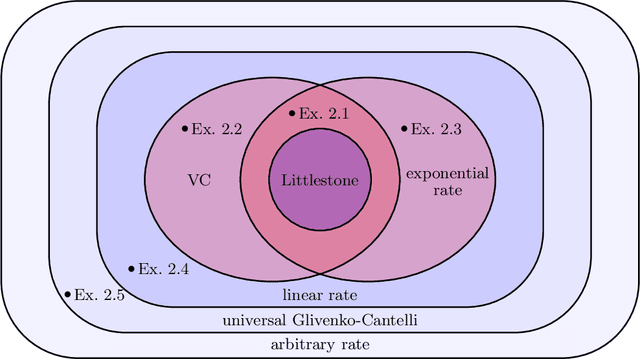
How quickly can a given class of concepts be learned from examples? It is common to measure the performance of a supervised machine learning algorithm by plotting its "learning curve", that is, the decay of the error rate as a function of the number of training examples. However, the classical theoretical framework for understanding learnability, the PAC model of Vapnik-Chervonenkis and Valiant, does not explain the behavior of learning curves: the distribution-free PAC model of learning can only bound the upper envelope of the learning curves over all possible data distributions. This does not match the practice of machine learning, where the data source is typically fixed in any given scenario, while the learner may choose the number of training examples on the basis of factors such as computational resources and desired accuracy. In this paper, we study an alternative learning model that better captures such practical aspects of machine learning, but still gives rise to a complete theory of the learnable in the spirit of the PAC model. More precisely, we consider the problem of universal learning, which aims to understand the performance of learning algorithms on every data distribution, but without requiring uniformity over the distribution. The main result of this paper is a remarkable trichotomy: there are only three possible rates of universal learning. More precisely, we show that the learning curves of any given concept class decay either at an exponential, linear, or arbitrarily slow rates. Moreover, each of these cases is completely characterized by appropriate combinatorial parameters, and we exhibit optimal learning algorithms that achieve the best possible rate in each case. For concreteness, we consider in this paper only the realizable case, though analogous results are expected to extend to more general learning scenarios.