 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClassification of Dysarthria based on the Levels of Severity. A Systematic Review
Oct 11, 2023Dysarthria is a neurological speech disorder that can significantly impact affected individuals' communication abilities and overall quality of life. The accurate and objective classification of dysarthria and the determination of its severity are crucial for effective therapeutic intervention. While traditional assessments by speech-language pathologists (SLPs) are common, they are often subjective, time-consuming, and can vary between practitioners. Emerging machine learning-based models have shown the potential to provide a more objective dysarthria assessment, enhancing diagnostic accuracy and reliability. This systematic review aims to comprehensively analyze current methodologies for classifying dysarthria based on severity levels. Specifically, this review will focus on determining the most effective set and type of features that can be used for automatic patient classification and evaluating the best AI techniques for this purpose. We will systematically review the literature on the automatic classification of dysarthria severity levels. Sources of information will include electronic databases and grey literature. Selection criteria will be established based on relevance to the research questions. Data extraction will include methodologies used, the type of features extracted for classification, and AI techniques employed. The findings of this systematic review will contribute to the current understanding of dysarthria classification, inform future research, and support the development of improved diagnostic tools. The implications of these findings could be significant in advancing patient care and improving therapeutic outcomes for individuals affected by dysarthria.
Complex Wavelet SSIM based Image Data Augmentation
Jul 11, 2020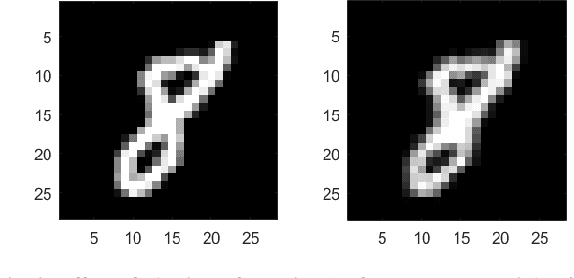
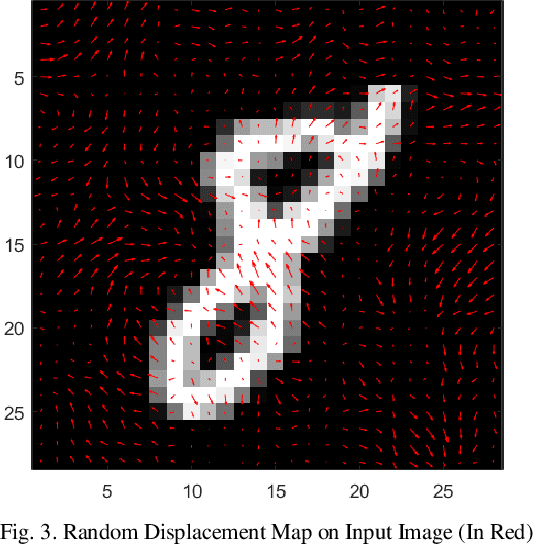

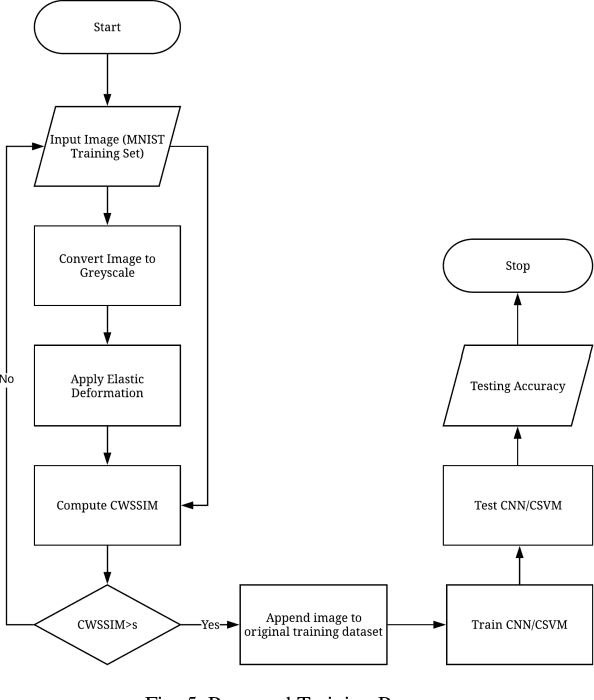
One of the biggest problems in neural learning networks is the lack of training data available to train the network. Data augmentation techniques over the past few years, have therefore been developed, aiming to increase the amount of artificial training data with the limited number of real world samples. In this paper, we look particularly at the MNIST handwritten dataset an image dataset used for digit recognition, and the methods of data augmentation done on this data set. We then take a detailed look into one of the most popular augmentation techniques used for this data set elastic deformation; and highlight its demerit of degradation in the quality of data, which introduces irrelevant data to the training set. To decrease this irrelevancy, we propose to use a similarity measure called Complex Wavelet Structural Similarity Index Measure (CWSSIM) to selectively filter out the irrelevant data before we augment the data set. We compare our observations with the existing augmentation technique and find our proposed method works yields better results than the existing technique.
Radial Based Analysis of GRNN in Non-Textured Image Inpainting
Jan 13, 2020Image inpainting algorithms are used to restore some damaged or missing information region of an image based on the surrounding information. The method proposed in this paper applies the radial based analysis of image inpainting on GRNN. The damaged areas are first isolated from rest of the areas and then arranged by their size and then inpainted using GRNN. The training of the neural network is done using different radii to achieve a better outcome. A comparative analysis is done for different regression-based algorithms. The overall results are compared with the results achieved by the other algorithms as LS-SVM with reference to the PSNR value.
Handwritten Character Recognition Using Unique Feature Extraction Technique
Jan 13, 2020
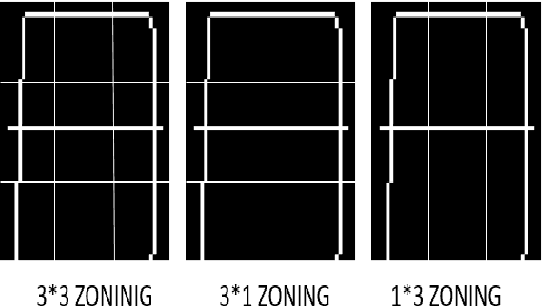

One of the most arduous and captivating domains under image processing is handwritten character recognition. In this paper we have proposed a feature extraction technique which is a combination of unique features of geometric, zone-based hybrid, gradient features extraction approaches and three different neural networks namely the Multilayer Perceptron network using Backpropagation algorithm (MLP BP), the Multilayer Perceptron network using Levenberg-Marquardt algorithm (MLP LM) and the Convolutional neural network (CNN) which have been implemented along with the Minimum Distance Classifier (MDC). The procedures lead to the conclusion that the proposed feature extraction algorithm is more accurate than its individual counterparts and also that Convolutional Neural Network is the most efficient neural network of the three in consideration.
Intensity and Rescale Invariant Copy Move Forgery Detection Techniques
Sep 11, 2018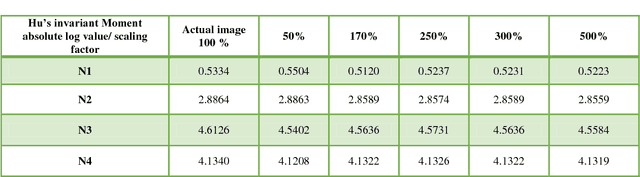
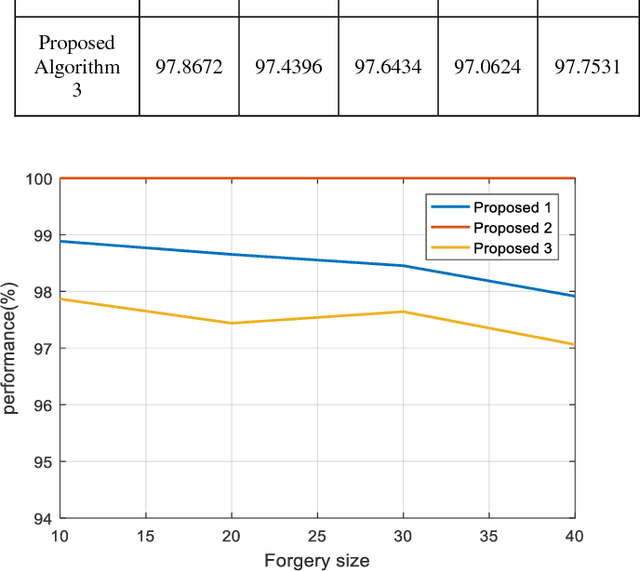
In this contemporary world digital media such as videos and images behave as an active medium to carry valuable information across the globe on all fronts. However there are several techniques evolved to tamper the image which has made their authenticity untrustworthy. CopyMove Forgery CMF is one of the most common forgeries present in an image where a cluster of pixels are duplicated in the same image with potential postprocessing techniques. Various state-of-art techniques are developed in the recent years which are effective in detecting passive image forgery. However most methods do fail when the copied image is rescaled or added with certain intensity before being pasted due to de-synchronization of pixels in the searching process. To tackle this problem the paper proposes distinct novel algorithms which recognize a unique approach of using Hus invariant moments and Discreet Cosine Transformations DCT to attain the desired rescale invariant and intensity invariant CMF detection techniques respectively. The experiments conducted quantitatively and qualitatively demonstrate the effectiveness of the algorithm.
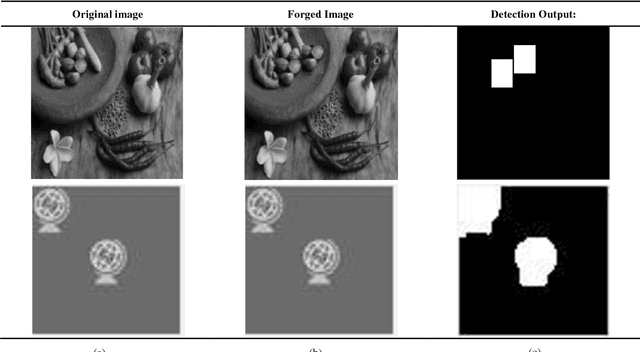
Copy Move Forgery using Hus Invariant Moments and Log Polar Transformations
Jun 07, 2018
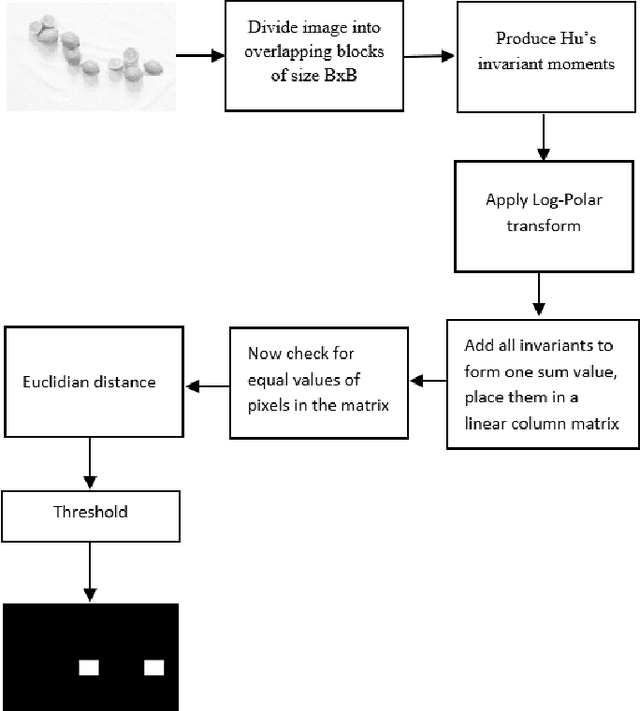
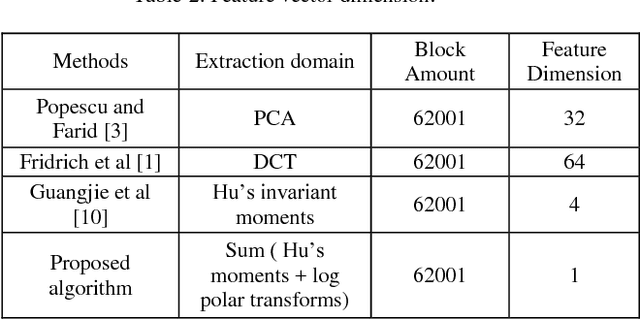
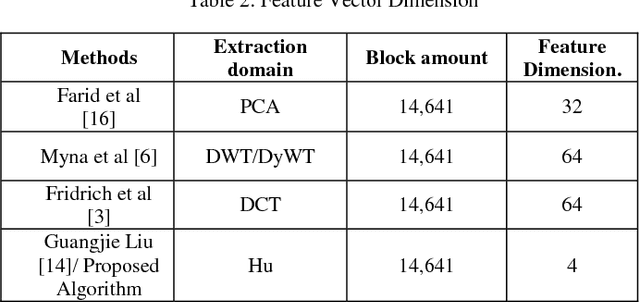
With the increase in interchange of data, there is a growing necessity of security. Considering the volumes of digital data that is transmitted, they are in need to be secure. Among the many forms of tampering possible, one widespread technique is Copy Move Forgery CMF. This forgery occurs when parts of the image are copied and duplicated elsewhere in the same image. There exist a number of algorithms to detect such a forgery in which the primary step involved is feature extraction. The feature extraction techniques employed must have lesser time and space complexity involved for an efficient and faster processing of media. Also, majority of the existing state of art techniques often tend to falsely match similar genuine objects as copy move forged during the detection process. To tackle these problems, the paper proposes a novel algorithm that recognizes a unique approach of using Hus Invariant Moments and Log polar Transformations to reduce feature vector dimension to one feature per block simultaneously detecting CMF among genuine similar objects in an image. The qualitative and quantitative results obtained demonstrate the effectiveness of this algorithm.
Implementation of Neural Network and feature extraction to classify ECG signals
Feb 17, 2018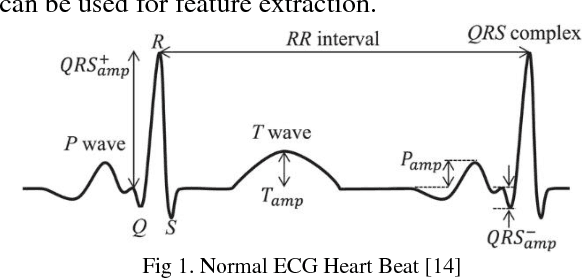
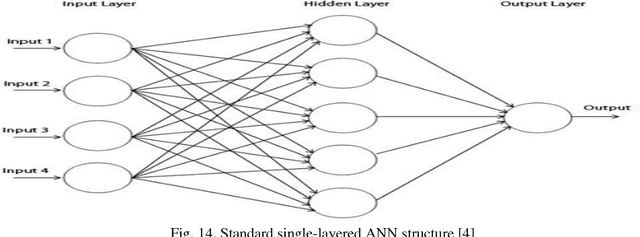
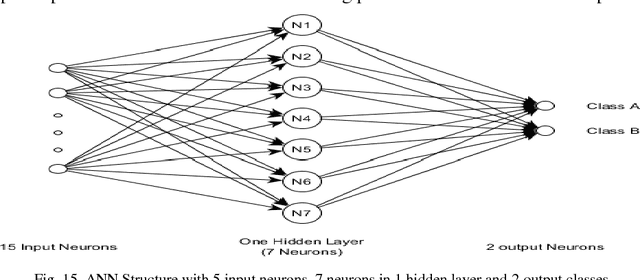
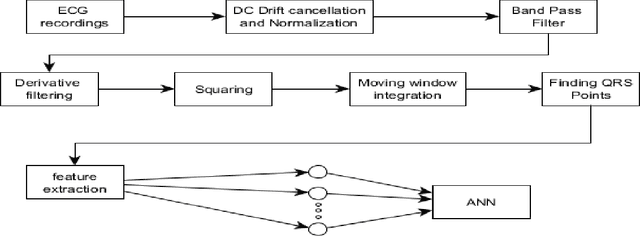
This paper presents a suitable and efficient implementation of a feature extraction algorithm (Pan Tompkins algorithm) on electrocardiography (ECG) signals, for detection and classification of four cardiac diseases: Sleep Apnea, Arrhythmia, Supraventricular Arrhythmia and Long Term Atrial Fibrillation (AF) and differentiating them from the normal heart beat by using pan Tompkins RR detection followed by feature extraction for classification purpose .The paper also presents a new approach towards signal classification using the existing neural networks classifiers.
Sentiment Analysis on Speaker Specific Speech Data
Feb 17, 2018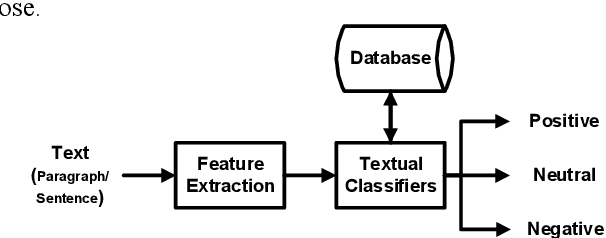
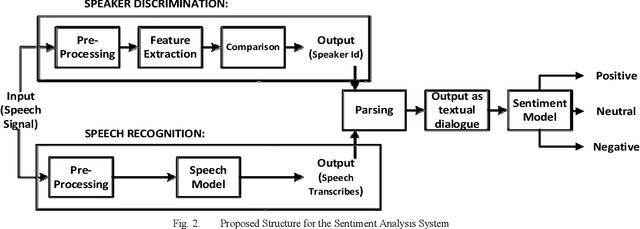

Sentiment analysis has evolved over past few decades, most of the work in it revolved around textual sentiment analysis with text mining techniques. But audio sentiment analysis is still in a nascent stage in the research community. In this proposed research, we perform sentiment analysis on speaker discriminated speech transcripts to detect the emotions of the individual speakers involved in the conversation. We analyzed different techniques to perform speaker discrimination and sentiment analysis to find efficient algorithms to perform this task.
Efficient Licence Plate Detection By Unique Edge Detection Algorithm and Smarter Interpretation Through IoT
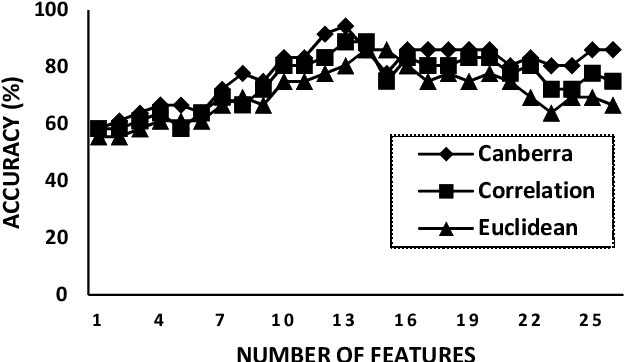
Oct 28, 2017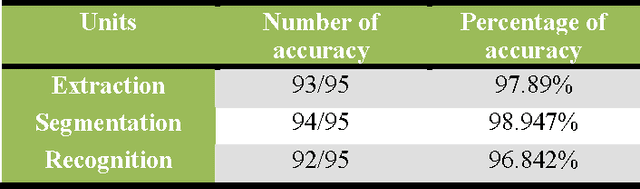



Vehicles play a vital role in modern day transportation systems. Number plate provides a standard means of identification for any vehicle. To serve this purpose, automatic licence plate recognition system was developed. This consisted of four major steps: Pre-processing of the obtained image, extraction of licence plate region, segmentation and character recognition. In earlier research, direct application of Sobel edge detection algorithm or applying threshold were used as key steps to extract the licence plate region, which does not produce effective results when the captured image is subjected to the high intensity of light. The use of morphological operations causes deformity in the characters during segmentation. We propose a novel algorithm to tackle the mentioned issues through a unique edge detection algorithm. It is also a tedious task to create and update the database of required vehicles frequently. This problem is solved by the use of Internet of things(IOT) where an online database can be created and updated from any module instantly. Also, through IoT, we connect all the cameras in a geographical area to one server to create a universal eye which drastically increases the probability of tracing a vehicle over having manual database attached to each camera for identification purpose.