 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Transformers for Lightweight Action Recognition
Dec 07, 2021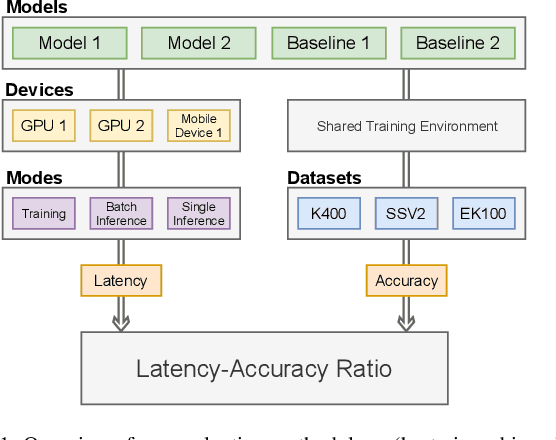


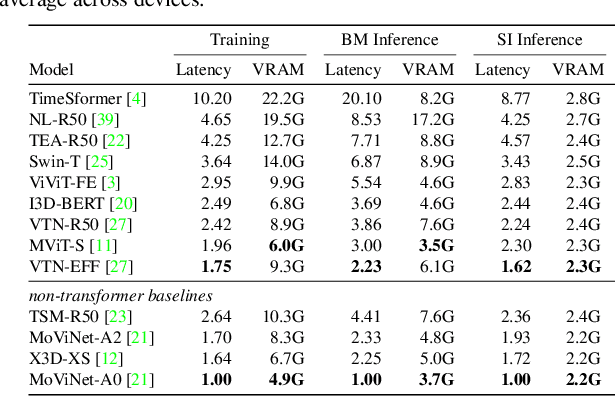
In video action recognition, transformers consistently reach state-of-the-art accuracy. However, many models are too heavyweight for the average researcher with limited hardware resources. In this work, we explore the limitations of video transformers for lightweight action recognition. We benchmark 13 video transformers and baselines across 3 large-scale datasets and 10 hardware devices. Our study is the first to evaluate the efficiency of action recognition models in depth across multiple devices and train a wide range of video transformers under the same conditions. We categorize current methods into three classes and show that composite transformers that augment convolutional backbones are best at lightweight action recognition, despite lacking accuracy. Meanwhile, attention-only models need more motion modeling capabilities and stand-alone attention block models currently incur too much latency overhead. Our experiments conclude that current video transformers are not yet capable of lightweight action recognition on par with traditional convolutional baselines, and that the previously mentioned shortcomings need to be addressed to bridge this gap. Code to reproduce our experiments will be made publicly available.
VideoLightFormer: Lightweight Action Recognition using Transformers
Jul 01, 2021



Efficient video action recognition remains a challenging problem. One large model after another takes the place of the state-of-the-art on the Kinetics dataset, but real-world efficiency evaluations are often lacking. In this work, we fill this gap and investigate the use of transformers for efficient action recognition. We propose a novel, lightweight action recognition architecture, VideoLightFormer. In a factorized fashion, we carefully extend the 2D convolutional Temporal Segment Network with transformers, while maintaining spatial and temporal video structure throughout the entire model. Existing methods often resort to one of the two extremes, where they either apply huge transformers to video features, or minimal transformers on highly pooled video features. Our method differs from them by keeping the transformer models small, but leveraging full spatiotemporal feature structure. We evaluate VideoLightFormer in a high-efficiency setting on the temporally-demanding EPIC-KITCHENS-100 and Something-Something-V2 (SSV2) datasets and find that it achieves a better mix of efficiency and accuracy than existing state-of-the-art models, apart from the Temporal Shift Module on SSV2.
Team PyKale Submission to the EPIC-Kitchens 2021 Unsupervised Domain Adaptation Challenge for Action Recognition
Jun 22, 2021

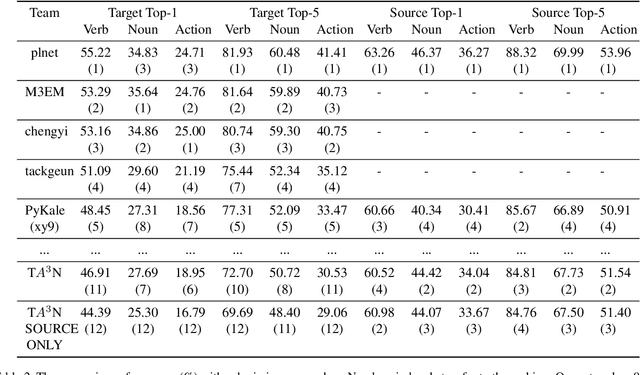
This report describes the technical details of our submission to the EPIC-Kitchens 2021 Unsupervised Domain Adaptation Challenge for Action Recognition. The EPIC-Kitchens dataset is more difficult than other video domain adaptation datasets due to multi-tasks with more modalities. Firstly, to participate in the challenge, we employ a transformer to capture the spatial information from each modality. Secondly, we employ a temporal attention module to model temporal-wise inter-dependency. Thirdly, we employ the adversarial domain adaptation network to learn the general features between labeled source and unlabeled target domain. Finally, we incorporate multiple modalities to improve the performance by a three-stream network with late fusion. Our network achieves the comparable performance with the state-of-the-art baseline T$A^3$N and outperforms the baseline on top-1 accuracy for verb class and top-5 accuracies for all three tasks which are verb, noun and action. Under the team name xy9, our submission achieved 5th place in terms of top-1 accuracy for verb class and all top-5 accuracies.