 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMHub.ai: A Simple, Standardized, and Reproducible Platform for AI Models in Medical Imaging
Jan 15, 2026Artificial intelligence (AI) has the potential to transform medical imaging by automating image analysis and accelerating clinical research. However, research and clinical use are limited by the wide variety of AI implementations and architectures, inconsistent documentation, and reproducibility issues. Here, we introduce MHub.ai, an open-source, container-based platform that standardizes access to AI models with minimal configuration, promoting accessibility and reproducibility in medical imaging. MHub.ai packages models from peer-reviewed publications into standardized containers that support direct processing of DICOM and other formats, provide a unified application interface, and embed structured metadata. Each model is accompanied by publicly available reference data that can be used to confirm model operation. MHub.ai includes an initial set of state-of-the-art segmentation, prediction, and feature extraction models for different modalities. The modular framework enables adaptation of any model and supports community contributions. We demonstrate the utility of the platform in a clinical use case through comparative evaluation of lung segmentation models. To further strengthen transparency and reproducibility, we publicly release the generated segmentations and evaluation metrics and provide interactive dashboards that allow readers to inspect individual cases and reproduce or extend our analysis. By simplifying model use, MHub.ai enables side-by-side benchmarking with identical execution commands and standardized outputs, and lowers the barrier to clinical translation.
Improving Graduate Outcomes by Identifying Skills Gaps and Recommending Courses Based on Career Interests
Nov 12, 2025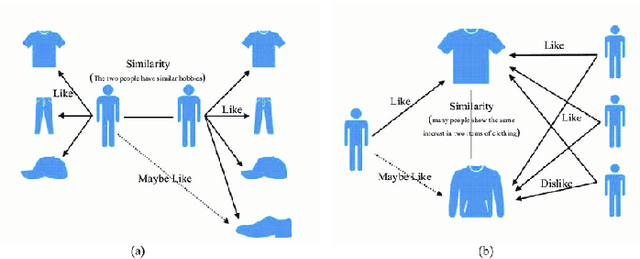


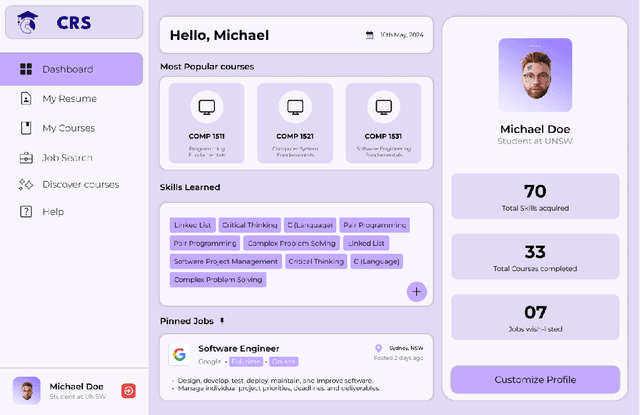
This paper aims to address the challenge of selecting relevant courses for students by proposing the design and development of a course recommendation system. The course recommendation system utilises a combination of data analytics techniques and machine learning algorithms to recommend courses that align with current industry trends and requirements. In order to provide customised suggestions, the study entails the design and implementation of an extensive algorithmic framework that combines machine learning methods, user preferences, and academic criteria. The system employs data mining and collaborative filtering techniques to examine past courses and individual career goals in order to provide course recommendations. Moreover, to improve the accessibility and usefulness of the recommendation system, special attention is given to the development of an easy-to-use front-end interface. The front-end design prioritises visual clarity, interaction, and simplicity through iterative prototyping and user input revisions, guaranteeing a smooth and captivating user experience. We refined and optimised the proposed system by incorporating user feedback, ensuring that it effectively meets the needs and preferences of its target users. The proposed course recommendation system could be a useful tool for students, instructors, and career advisers to use in promoting lifelong learning and professional progression as it fills the gap between university learning and industry expectations. We hope that the proposed course recommendation system will help university students in making data-drive and industry-informed course decisions, in turn, improving graduate outcomes for the university sector.
AI generated annotations for Breast, Brain, Liver, Lungs and Prostate cancer collections in National Cancer Institute Imaging Data Commons
Sep 30, 2024



AI in Medical Imaging project aims to enhance the National Cancer Institute's (NCI) Image Data Commons (IDC) by developing nnU-Net models and providing AI-assisted segmentations for cancer radiology images. We created high-quality, AI-annotated imaging datasets for 11 IDC collections. These datasets include images from various modalities, such as computed tomography (CT) and magnetic resonance imaging (MRI), covering the lungs, breast, brain, kidneys, prostate, and liver. The nnU-Net models were trained using open-source datasets. A portion of the AI-generated annotations was reviewed and corrected by radiologists. Both the AI and radiologist annotations were encoded in compliance with the the Digital Imaging and Communications in Medicine (DICOM) standard, ensuring seamless integration into the IDC collections. All models, images, and annotations are publicly accessible, facilitating further research and development in cancer imaging. This work supports the advancement of imaging tools and algorithms by providing comprehensive and accurate annotated datasets.
Improving Lesion Segmentation in FDG-18 Whole-Body PET/CT scans using Multilabel approach: AutoPET II challenge
Nov 02, 2023



Automatic segmentation of lesions in FDG-18 Whole Body (WB) PET/CT scans using deep learning models is instrumental for determining treatment response, optimizing dosimetry, and advancing theranostic applications in oncology. However, the presence of organs with elevated radiotracer uptake, such as the liver, spleen, brain, and bladder, often leads to challenges, as these regions are often misidentified as lesions by deep learning models. To address this issue, we propose a novel approach of segmenting both organs and lesions, aiming to enhance the performance of automatic lesion segmentation methods. In this study, we assessed the effectiveness of our proposed method using the AutoPET II challenge dataset, which comprises 1014 subjects. We evaluated the impact of inclusion of additional labels and data in the segmentation performance of the model. In addition to the expert-annotated lesion labels, we introduced eight additional labels for organs, including the liver, kidneys, urinary bladder, spleen, lung, brain, heart, and stomach. These labels were integrated into the dataset, and a 3D UNET model was trained within the nnUNet framework. Our results demonstrate that our method achieved the top ranking in the held-out test dataset, underscoring the potential of this approach to significantly improve lesion segmentation accuracy in FDG-18 Whole-Body PET/CT scans, ultimately benefiting cancer patients and advancing clinical practice.
The AIMI Initiative: AI-Generated Annotations for Imaging Data Commons Collections
Oct 23, 2023The Image Data Commons (IDC) contains publicly available cancer radiology datasets that could be pertinent to the research and development of advanced imaging tools and algorithms. However, the full extent of its research capabilities is limited by the fact that these datasets have few, if any, annotations associated with them. Through this study with the AI in Medical Imaging (AIMI) initiative a significant contribution, in the form of AI-generated annotations, was made to provide 11 distinct medical imaging collections from the IDC with annotations. These collections included computed tomography (CT), magnetic resonance imaging (MRI), and positron emission tomography (PET) imaging modalities. The main focus of these annotations were in the chest, breast, kidneys, prostate, and liver. Both publicly available and novel AI algorithms were adopted and further developed using open-sourced data coupled with expert annotations to create the AI-generated annotations. A portion of the AI annotations were reviewed and corrected by a radiologist to assess the AI models' performances. Both the AI's and the radiologist's annotations conformed to DICOM standards for seamless integration into the IDC collections as third-party analyses. This study further cements the well-documented notion that expansive publicly accessible datasets, in the field of cancer imaging, coupled with AI will aid in increased accessibility as well as reliability for further research and development.
Adversarial TCAV -- Robust and Effective Interpretation of Intermediate Layers in Neural Networks
Feb 26, 2020



Interpreting neural network decisions and the information learned in intermediate layers is still a challenge due to the opaque internal state and shared non-linear interactions. Although (Kim et al, 2017) proposed to interpret intermediate layers by quantifying its ability to distinguish a user-defined concept (from random examples), the questions of robustness (variation against the choice of random examples) and effectiveness (retrieval rate of concept images) remain. We investigate these two properties and propose improvements to make concept activations reliable for practical use. Effectiveness: If the intermediate layer has effectively learned a user-defined concept, it should be able to recall --- at the testing step --- most of the images containing the proposed concept. For instance, we observed that the recall rate of Tiger shark and Great white shark from the ImageNet dataset with "Fins" as a user-defined concept was only 18.35% for VGG16. To increase the effectiveness of concept learning, we propose A-CAV --- the Adversarial Concept Activation Vector --- this results in larger margins between user concepts and (negative) random examples. This approach improves the aforesaid recall to 76.83% for VGG16. For robustness, we define it as the ability of an intermediate layer to be consistent in its recall rate (the effectiveness) for different random seeds. We observed that TCAV has a large variance in recalling a concept across different random seeds. For example, the recall of cat images (from a layer learning the concept of tail) varies from 18% to 86% with 20.85% standard deviation on VGG16. We propose a simple and scalable modification that employs a Gram-Schmidt process to sample random noise from concepts and learn an average "concept classifier". This approach improves the aforesaid standard deviation from 20.85% to 6.4%.
Fine-grained Uncertainty Modeling in Neural Networks
Feb 11, 2020



Existing uncertainty modeling approaches try to detect an out-of-distribution point from the in-distribution dataset. We extend this argument to detect finer-grained uncertainty that distinguishes between (a). certain points, (b). uncertain points but within the data distribution, and (c). out-of-distribution points. Our method corrects overconfident NN decisions, detects outlier points and learns to say ``I don't know'' when uncertain about a critical point between the top two predictions. In addition, we provide a mechanism to quantify class distributions overlap in the decision manifold and investigate its implications in model interpretability. Our method is two-step: in the first step, the proposed method builds a class distribution using Kernel Activation Vectors (kav) extracted from the Network. In the second step, the algorithm determines the confidence of a test point by a hierarchical decision rule based on the chi-squared distribution of squared Mahalanobis distances. Our method sits on top of a given Neural Network, requires a single scan of training data to estimate class distribution statistics, and is highly scalable to deep networks and wider pre-softmax layer. As a positive side effect, our method helps to prevent adversarial attacks without requiring any additional training. It is directly achieved when the Softmax layer is substituted by our robust uncertainty layer at the evaluation phase.