 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Prognostics and Health Management of Wafer Chemical-Mechanical Polishing System using Autoencoder
Mar 03, 2025The Prognostics and Health Management Data Challenge (PHM) 2016 tracks the health state of components of a semiconductor wafer polishing process. The ultimate goal is to develop an ability to predict the measurement on the wafer surface wear through monitoring the components health state. This translates to cost saving in large scale production. The PHM dataset contains many time series measurements not utilized by traditional physics based approach. On the other hand task, applying a data driven approach such as deep learning to the PHM dataset is non-trivial. The main issue with supervised deep learning is that class label is not available to the PHM dataset. Second, the feature space trained by an unsupervised deep learner is not specifically targeted at the predictive ability or regression. In this work, we propose using the autoencoder based clustering whereby the feature space trained is found to be more suitable for performing regression. This is due to having a more compact distribution of samples respective to their nearest cluster means. We justify our claims by comparing the performance of our proposed method on the PHM dataset with several baselines such as the autoencoder as well as state-of-the-art approaches.
Boundary-Decoder network for inverse prediction of capacitor electrostatic analysis
Nov 28, 2024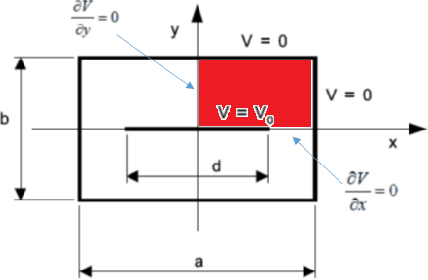
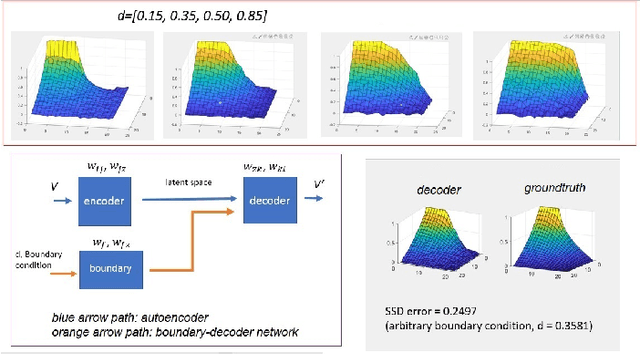
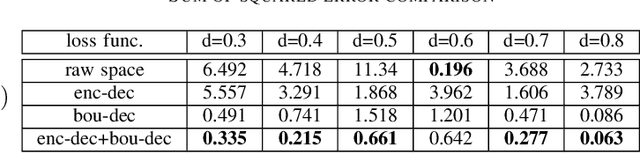
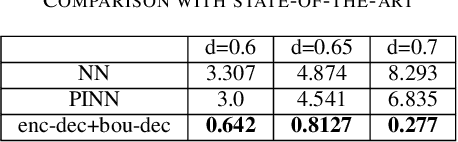
Traditional electrostatic simulation are meshed-based methods which convert partial differential equations into an algebraic system of equations and their solutions are approximated through numerical methods. These methods are time consuming and any changes in their initial or boundary conditions will require solving the numerical problem again. Newer computational methods such as the physics informed neural net (PINN) similarly require re-training when boundary conditions changes. In this work, we propose an end-to-end deep learning approach to model parameter changes to the boundary conditions. The proposed method is demonstrated on the test problem of a long air-filled capacitor structure. The proposed approach is compared to plain vanilla deep learning (NN) and PINN. It is shown that our method can significantly outperform both NN and PINN under dynamic boundary condition as well as retaining its full capability as a forward model.
Intelligent Personal Assistant with Knowledge Navigation
Apr 28, 2017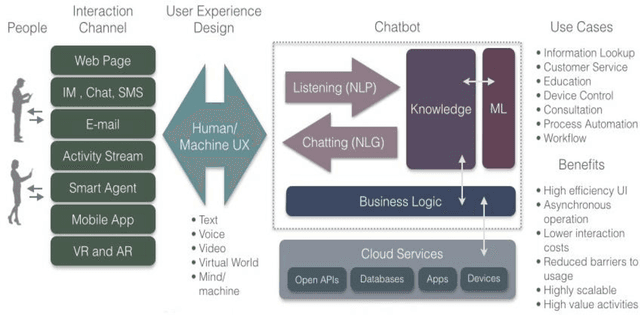
An Intelligent Personal Agent (IPA) is an agent that has the purpose of helping the user to gain information through reliable resources with the help of knowledge navigation techniques and saving time to search the best content. The agent is also responsible for responding to the chat-based queries with the help of Conversation Corpus. We will be testing different methods for optimal query generation. To felicitate the ease of usage of the application, the agent will be able to accept the input through Text (Keyboard), Voice (Speech Recognition) and Server (Facebook) and output responses using the same method. Existing chat bots reply by making changes in the input, but we will give responses based on multiple SRT files. The model will learn using the human dialogs dataset and will be able respond human-like. Responses to queries about famous things (places, people, and words) can be provided using web scraping which will enable the bot to have knowledge navigation features. The agent will even learn from its past experiences supporting semi-supervised learning.
Grading of Mammalian Cumulus Oocyte Complexes using Machine Learning for in Vitro Embryo Culture
Mar 05, 2016



Visual observation of Cumulus Oocyte Complexes provides only limited information about its functional competence, whereas the molecular evaluations methods are cumbersome or costly. Image analysis of mammalian oocytes can provide attractive alternative to address this challenge. However, it is complex, given the huge number of oocytes under inspection and the subjective nature of the features inspected for identification. Supervised machine learning methods like random forest with annotations from expert biologists can make the analysis task standardized and reduces inter-subject variability. We present a semi-automatic framework for predicting the class an oocyte belongs to, based on multi-object parametric segmentation on the acquired microscopic image followed by a feature based classification using random forests.