 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoundary-Decoder network for inverse prediction of capacitor electrostatic analysis
Nov 28, 2024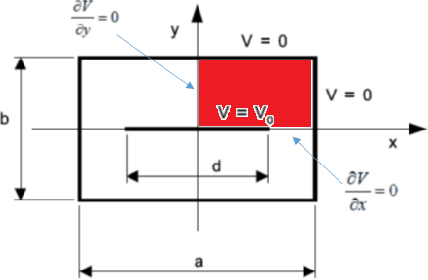
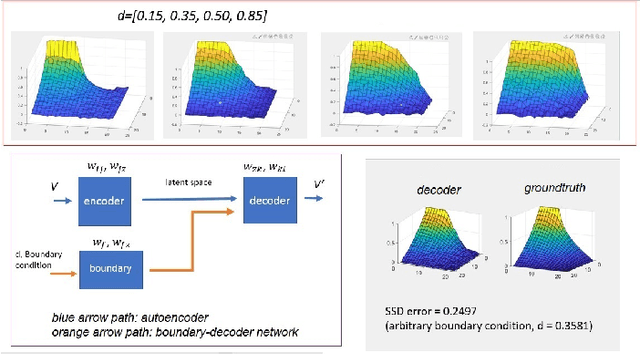
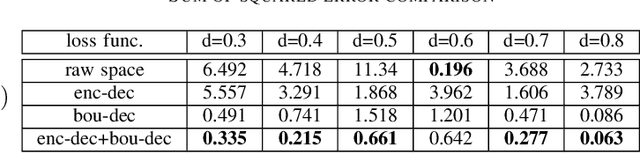
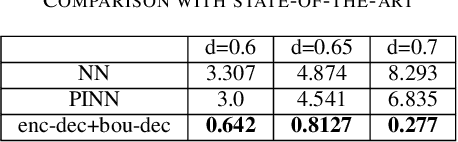
Traditional electrostatic simulation are meshed-based methods which convert partial differential equations into an algebraic system of equations and their solutions are approximated through numerical methods. These methods are time consuming and any changes in their initial or boundary conditions will require solving the numerical problem again. Newer computational methods such as the physics informed neural net (PINN) similarly require re-training when boundary conditions changes. In this work, we propose an end-to-end deep learning approach to model parameter changes to the boundary conditions. The proposed method is demonstrated on the test problem of a long air-filled capacitor structure. The proposed approach is compared to plain vanilla deep learning (NN) and PINN. It is shown that our method can significantly outperform both NN and PINN under dynamic boundary condition as well as retaining its full capability as a forward model.
Best Practices for Learning Domain-Specific Cross-Lingual Embeddings
Jul 06, 2019
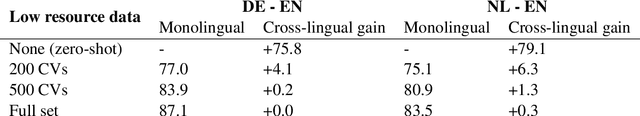
Cross-lingual embeddings aim to represent words in multiple languages in a shared vector space by capturing semantic similarities across languages. They are a crucial component for scaling tasks to multiple languages by transferring knowledge from languages with rich resources to low-resource languages. A common approach to learning cross-lingual embeddings is to train monolingual embeddings separately for each language and learn a linear projection from the monolingual spaces into a shared space, where the mapping relies on a small seed dictionary. While there are high-quality generic seed dictionaries and pre-trained cross-lingual embeddings available for many language pairs, there is little research on how they perform on specialised tasks. In this paper, we investigate the best practices for constructing the seed dictionary for a specific domain. We evaluate the embeddings on the sequence labelling task of Curriculum Vitae parsing and show that the size of a bilingual dictionary, the frequency of the dictionary words in the domain corpora and the source of data (task-specific vs generic) influence the performance. We also show that the less training data is available in the low-resource language, the more the construction of the bilingual dictionary matters, and demonstrate that some of the choices are crucial in the zero-shot transfer learning case.