 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProgress and Challenges for the Application of Machine Learning for Neglected Tropical Diseases
Dec 02, 2022Neglected tropical diseases (NTDs) continue to affect the livelihood of individuals in countries in the Southeast Asia and Western Pacific region. These diseases have been long existing and have caused devastating health problems and economic decline to people in low- and middle-income (developing) countries. An estimated 1.7 billion of the world's population suffer one or more NTDs annually, this puts approximately one in five individuals at risk for NTDs. In addition to health and social impact, NTDs inflict significant financial burden to patients, close relatives, and are responsible for billions of dollars lost in revenue from reduced labor productivity in developing countries alone. There is an urgent need to better improve the control and eradication or elimination efforts towards NTDs. This can be achieved by utilizing machine learning tools to better the surveillance, prediction and detection program, and combat NTDs through the discovery of new therapeutics against these pathogens. This review surveys the current application of machine learning tools for NTDs and the challenges to elevate the state-of-the-art of NTDs surveillance, management, and treatment.
ImmunoLingo: Linguistics-based formalization of the antibody language
Sep 26, 2022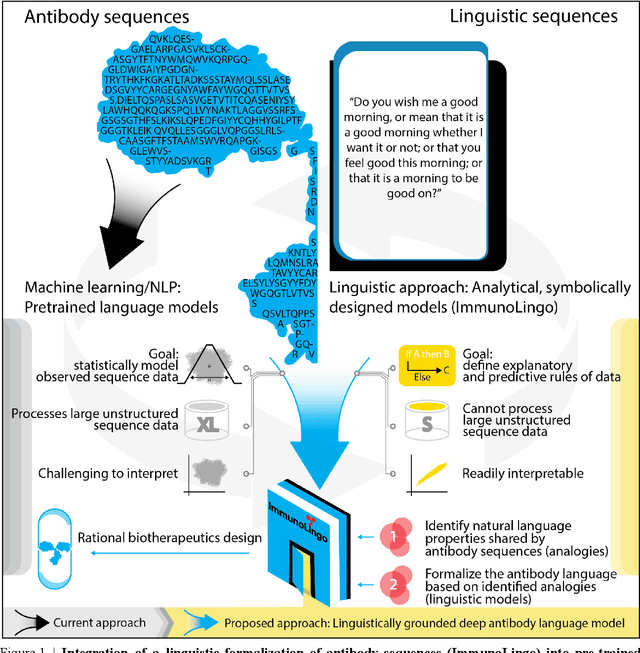
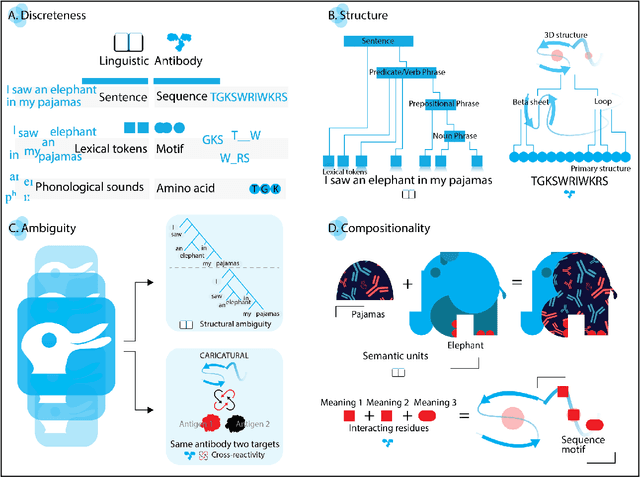
Apparent parallels between natural language and biological sequence have led to a recent surge in the application of deep language models (LMs) to the analysis of antibody and other biological sequences. However, a lack of a rigorous linguistic formalization of biological sequence languages, which would define basic components, such as lexicon (i.e., the discrete units of the language) and grammar (i.e., the rules that link sequence well-formedness, structure, and meaning) has led to largely domain-unspecific applications of LMs, which do not take into account the underlying structure of the biological sequences studied. A linguistic formalization, on the other hand, establishes linguistically-informed and thus domain-adapted components for LM applications. It would facilitate a better understanding of how differences and similarities between natural language and biological sequences influence the quality of LMs, which is crucial for the design of interpretable models with extractable sequence-functions relationship rules, such as the ones underlying the antibody specificity prediction problem. Deciphering the rules of antibody specificity is crucial to accelerating rational and in silico biotherapeutic drug design. Here, we formalize the properties of the antibody language and thereby establish not only a foundation for the application of linguistic tools in adaptive immune receptor analysis but also for the systematic immunolinguistic studies of immune receptor specificity in general.
Advancing protein language models with linguistics: a roadmap for improved interpretability
Jul 03, 2022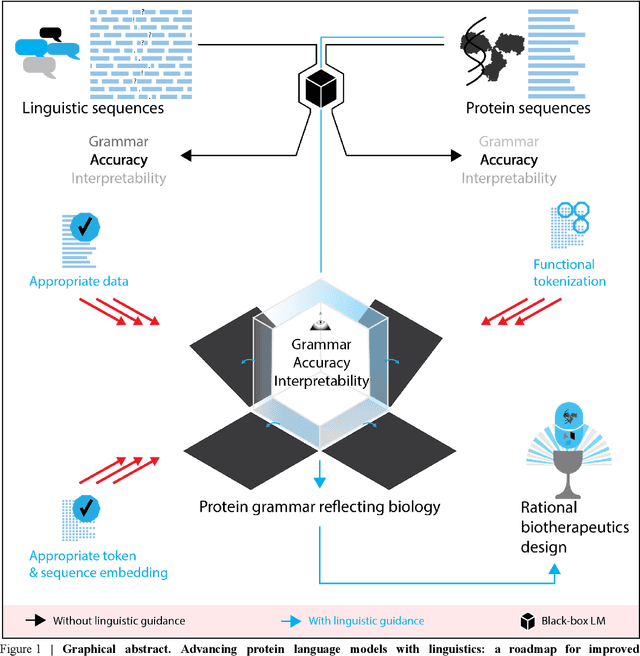
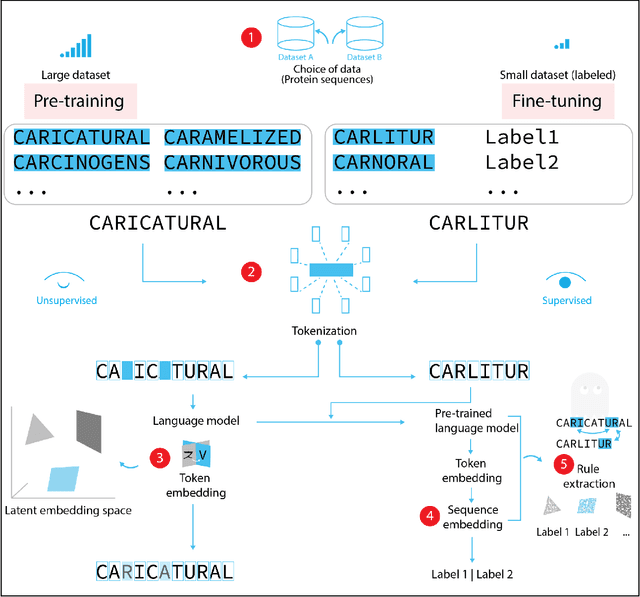
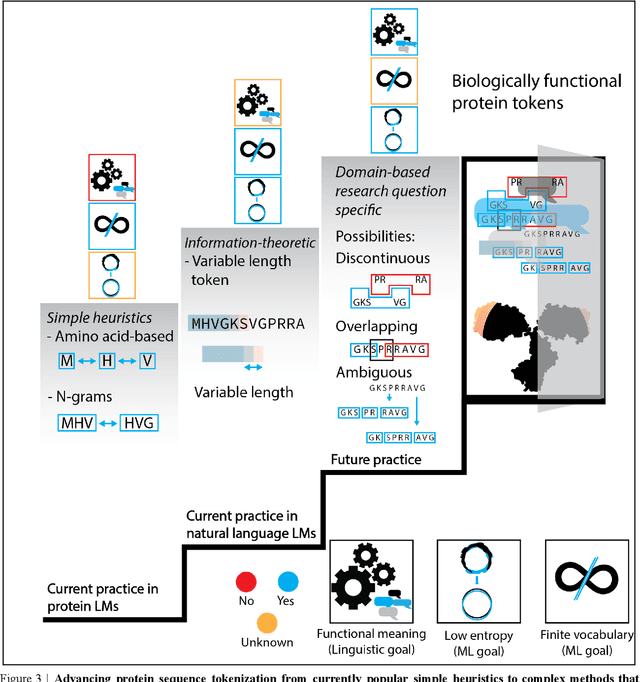
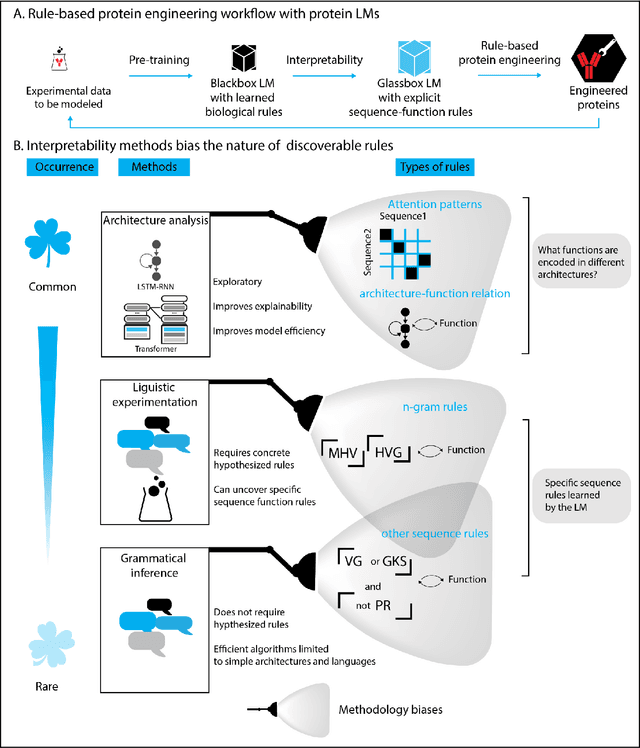
Deep neural-network-based language models (LMs) are increasingly applied to large-scale protein sequence data to predict protein function. However, being largely blackbox models and thus challenging to interpret, current protein LM approaches do not contribute to a fundamental understanding of sequence-function mappings, hindering rule-based biotherapeutic drug development. We argue that guidance drawn from linguistics, a field specialized in analytical rule extraction from natural language data, can aid with building more interpretable protein LMs that have learned relevant domain-specific rules. Differences between protein sequence data and linguistic sequence data require the integration of more domain-specific knowledge in protein LMs compared to natural language LMs. Here, we provide a linguistics-based roadmap for protein LM pipeline choices with regard to training data, tokenization, token embedding, sequence embedding, and model interpretation. Combining linguistics with protein LMs enables the development of next-generation interpretable machine learning models with the potential of uncovering the biological mechanisms underlying sequence-function relationships.