 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvancing protein language models with linguistics: a roadmap for improved interpretability
Paper and Code
Jul 03, 2022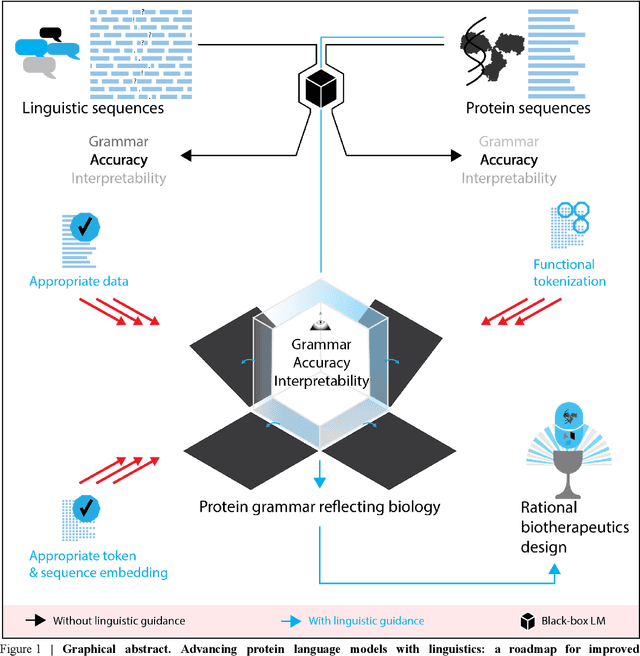
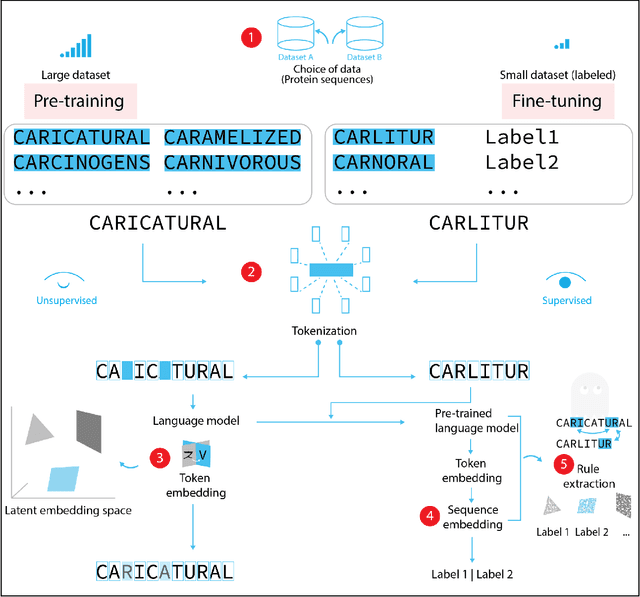
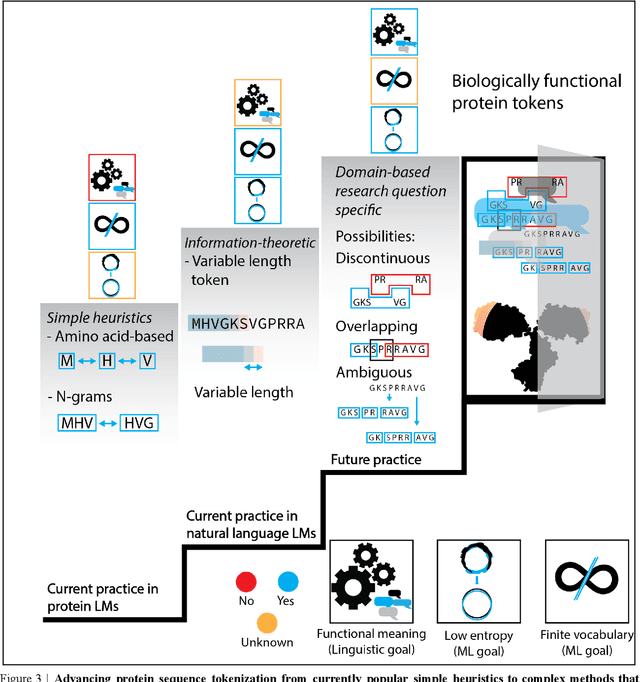
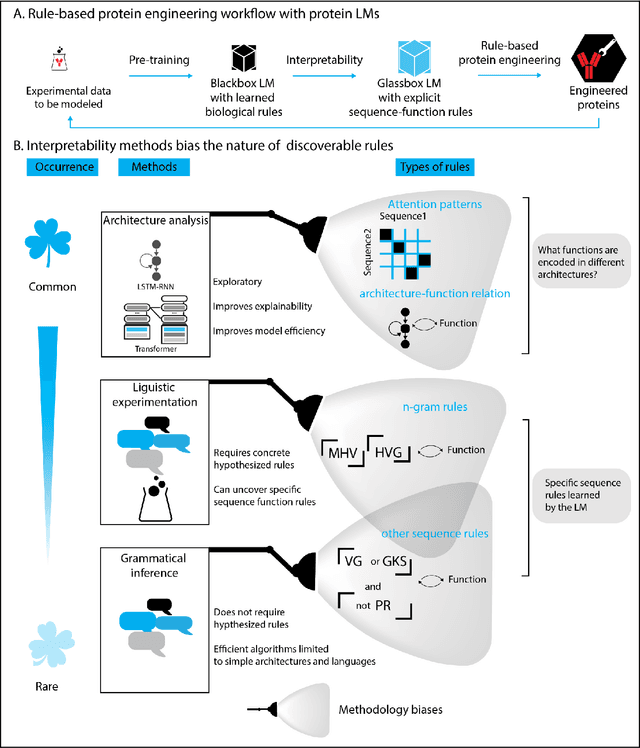
Deep neural-network-based language models (LMs) are increasingly applied to large-scale protein sequence data to predict protein function. However, being largely blackbox models and thus challenging to interpret, current protein LM approaches do not contribute to a fundamental understanding of sequence-function mappings, hindering rule-based biotherapeutic drug development. We argue that guidance drawn from linguistics, a field specialized in analytical rule extraction from natural language data, can aid with building more interpretable protein LMs that have learned relevant domain-specific rules. Differences between protein sequence data and linguistic sequence data require the integration of more domain-specific knowledge in protein LMs compared to natural language LMs. Here, we provide a linguistics-based roadmap for protein LM pipeline choices with regard to training data, tokenization, token embedding, sequence embedding, and model interpretation. Combining linguistics with protein LMs enables the development of next-generation interpretable machine learning models with the potential of uncovering the biological mechanisms underlying sequence-function relationships.